INTERSPEECH 是由国际语音通讯协会 (International Speech Communication Association, ISCA) 创办的语音信号处理领域顶级旗舰国际会议,9月18号开会!本教程部分将介绍自监督语音表示学习方法及其与相关研究领域的联系。非常值得关注!

尽管深度学习模型已经彻底改变了语音和音频处理领域,但它们为单个任务和应用场景构建了专门的模型。深度神经模型也阻碍了方言和标记数据有限的语言。自监督表示学习方法有望提供一个单一的通用模型,以造福于一系列任务和领域。他们最近在NLP和计算机视觉领域取得了成功,达到了新的性能水平,同时减少了许多下游场景所需的标签。语音表示学习也在经历着类似的发展,主要有三类: 生成、对比和预测。其他方法则依赖于多模态数据进行预训练,将文本或视觉数据流与语音混合。虽然自监督语音表征仍是一个发展中的研究领域,但它与声学词嵌入和零词汇资源学习密切相关。本教程部分将介绍自监督语音表示学习方法及其与相关研究领域的联系。由于目前的许多方法只关注自动语音识别作为下游任务,我们将回顾最近对学习表示的基准测试的努力,以扩展这种表示在语音识别之外的应用。本教程的一个实践部分将提供构建和评估语音表示模型的实用指导。

尽管有监督深度学习已经彻底改变了语音和音频处理,但它仍然需要为个别任务和应用场景建立专门的模型。同样,要将这种方法应用到只有有限标记数据的方言和语言中也很困难。自监督表示学习方法有望提供一个单一的通用模型,该模型将有益于各种任务和领域。这种方法已经在自然语言处理和计算机视觉领域取得了成功,实现了新的性能水平,同时减少了许多下游场景所需的标签数量。语音表示学习在生成法、对比法和预测法这三大类中经历着类似的进展。其他方法依赖于多模态数据进行预训练,将文本或视觉数据流与语音混合。尽管自监督语音表示仍然是一个新兴的研究领域,但它与声学词嵌入和零词汇资源学习密切相关,这两种方法已经活跃了多年的研究。本文介绍了自监督语音表示学习的方法及其与其他研究领域的联系。由于目前许多方法只关注自动语音识别作为下游任务,我们回顾了最近对学习表示进行基准测试的努力,以扩展语音识别以外的应用。
在过去的十年中,深度学习方法通过性能的巨大飞跃彻底改变了语音处理,实现了各种现实应用。深度神经网络的监督学习是这种转换的基石,为富含标记数据[1]-[3]的场景提供了令人印象深刻的增益。矛盾的是,这种对监督学习的严重依赖限制了那些不能吸引同等水平标签数据的语言和领域的进步。为了克服对标签数据的需求,研究人员探索了使用非成对音频数据的方法,以开辟新的工业语音用例和低资源语言[4]-[6]。受儿童如何通过听力和与家庭和环境的互动来学习他们的第一语言的启发,科学家试图使用原始波形和频谱信号来学习语音表示,这些表示捕获低水平的声学事件、词汇知识,一直到句法和语义信息。这些习得的表示然后用于需要最少数量的标记数据[7]-[9]的目标下游应用程序。形式上,表示学习指的是提取潜在特征的算法,这些特征捕获了观察到的输入[9]的潜在解释因素。
表示学习方法通常被认为是无监督学习的例子,它指的是机器学习方法的家族,发现训练样本中自然发生的模式,没有预先分配的标签或分数[10]。术语“无监督”是用来区分这一类方法与“有监督”方法和“半监督”方法的区别。“有监督”方法为每个训练样本分配一个标签,“半监督”方法利用少量带标签的训练样本来指导使用大量无标记样本的学习。无监督学习技术的例子包括k-means聚类[11]、混合模型[12]、自动编码器[13]和非负矩阵分解[14]。自监督学习(SSL)是无监督学习方法的一个快速发展的子类,这是一种利用从输入数据本身提取的信息作为标签来学习对下游任务有用的表示的技术。本文重点介绍自监督学习方法。
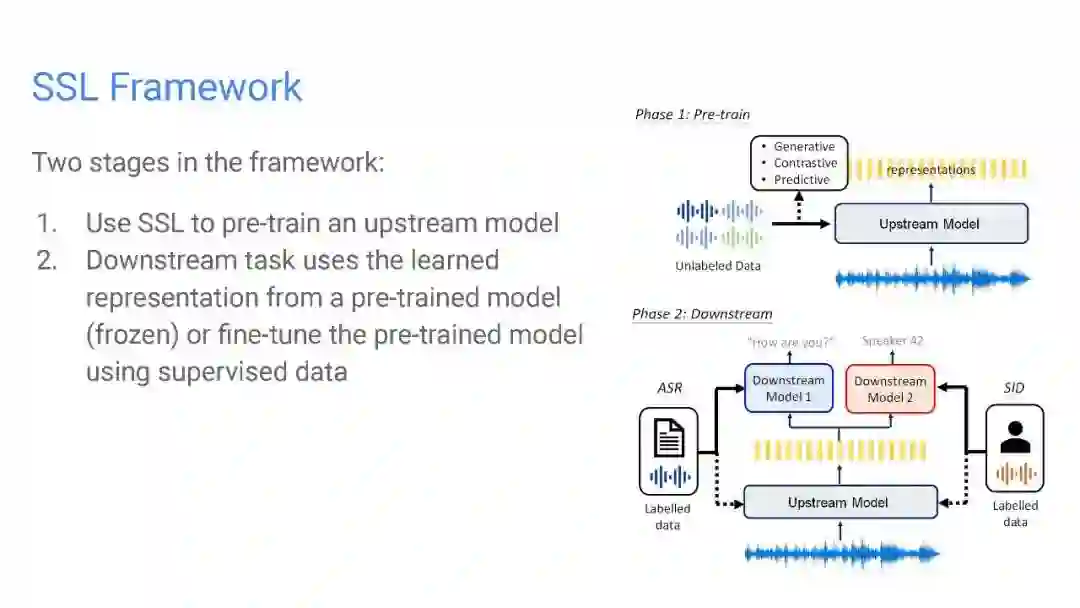
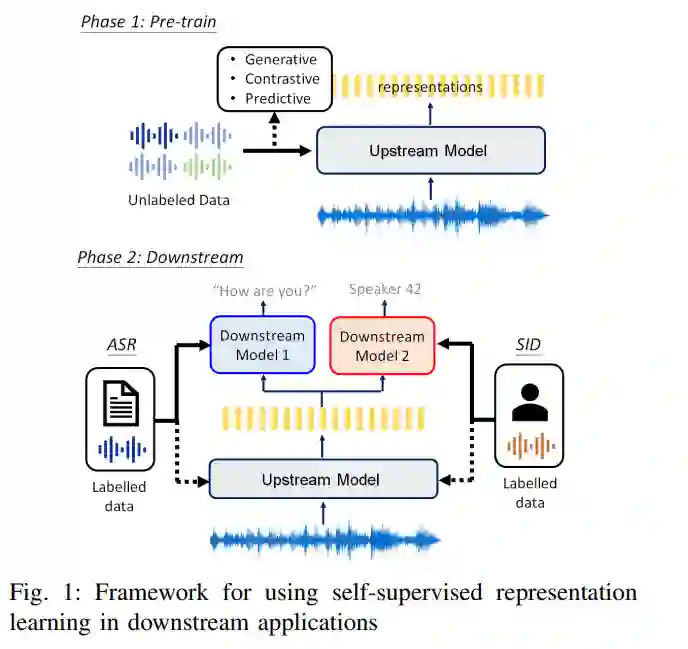
图1概述了与下游应用程序相关的自监督表示学习。该框架分为两个阶段。在第一阶段,我们使用SSL预训练表示模型,也称为上游模型或基础模型。在第二阶段,下游任务使用来自冻结模型的学习表示,或在监督阶段[15]中微调整个预先训练的模型。自动语音识别(ASR)和说话人识别(SID)是图1中下游应用的例子。人们认为,学习过的语音表示应该是分离的、不变的和有层次的。由于口语话语所包含的信息要比相应的文本转录丰富得多。例如,说话人的身份、风格、情绪、周围的噪音和沟通渠道的噪音——学习能把这些变化因素分离出来的表征是很重要的。此外,学习到的特征对背景噪声和通信通道的变化的不变性确保了下游应用场景的稳定性。声学、词汇和语义级别的学习特征层次结构支持具有不同需求的应用程序。例如,说话人识别任务受益于低水平的声学表征,而语音翻译任务则需要输入话语的语义表征。
由于SSL技术的普及,已经发表了关于该技术在一般[16]-[18]以及其在自然语言处理(NLP)[19] -[22]和计算机视觉(CV)[23]中的应用的评论。然而,这些概述都没有关注用于语音处理的SSL。由于语音信号与图像和文本输入有很大的不同,许多理论和技术已经发展起来,以解决语音的独特挑战。一篇综述讨论了基于深度学习模型[24]的语音表示学习,但没有讨论自我监督学习的最新进展。这激发了对语音SSL的概述。本文的结构安排如下。第二节简要回顾了语音表示学习的历史,第三节回顾了当前的语音SSL模型。第四节调查SSL数据集和基准,并讨论和比较来自不同工作的结果。第五节分析了成功的SSL方法,并对技术创新的重要性提出了见解。第VI节回顾了使用SSL的零资源下游任务。最后,第七部分对全文进行了总结,并提出了未来的研究方向。
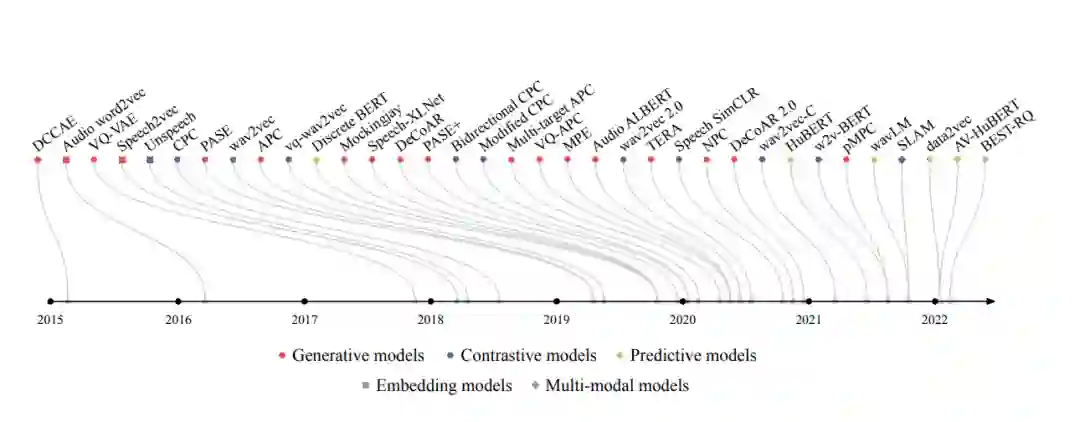
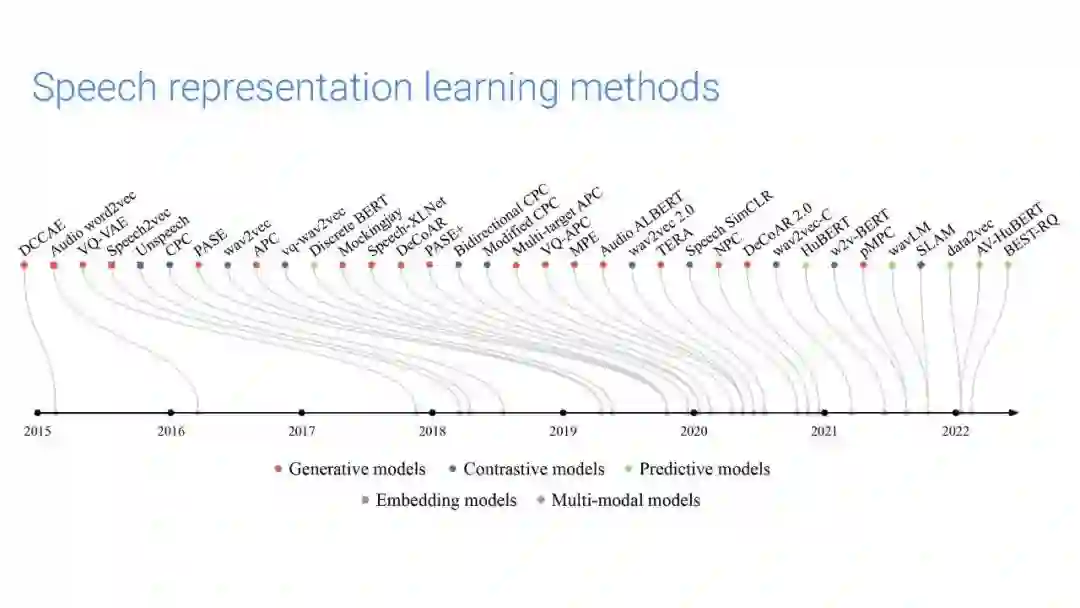
图2:根据arXiv上的首次发布日期或会议提交日期列出的模型的选择,当这一点明显先于前者时。这些模型分为生成型、对比型和预测型。此外,一些模型的特征是嵌入模型或多模态模型,尽管大多数模型只从语音学习帧级表示。有些模型混合使用生成和对比任务。例如,PASE和PASE+使用多任务设置,但发现生成任务对下游任务性能最重要[69]。