2018年有意思的几篇GAN论文
【导读】本文介绍了两篇2018年不仅最先进,而且酷而有趣的两篇论文。
作者|Damian Bogunowicz
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks:可视化和理解生成性对抗网络 - 考虑到GAN的火热程度,很明显这项技术迟早会在商业上使用。但是,由于我们对其内在机制知之甚少,我认为创建可靠的产品仍然很困难。这项工作帮助我们真正理解与控制GAN。绝对查看他们精彩的互动演示进化的
Evolutionary Generative Adversarial Networks - 这是一篇真正易读且简单易懂的文章。进化算法与GAN一起 - 这一定很酷。
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks
论文地址:
https://arxiv.org/pdf/1811.10597.pdf
主要思想
毫无疑问,GAN证明了深度神经网络的强大功能。 机器学习能够生成令人惊叹的高分辨率图像,就好像它像我们一样理解世界。 但是,就像其他统计模型一样,他们最大的缺陷就是缺乏可解释性。 这项研究向理解GAN迈出了非常重要的一步。 它允许我们在生成器中找到“负责”生成类别c中某些对象的单元。 作者声称,我们可以找到生成器的一层并找到一些单元,它们负责在生成的图像中生成类别c的物体。 作者通过引入两个步骤:解剖(Dissection)和干预(Intervention),为每个类别寻找一套“因果”单元。 此外,这可能是第一项工作,它为理解GAN的内部机制提供了系统分析。
方法
生成器 G可以被视为潜在向量的映射 ž 到生成的图像 X = G (z) 。 我们的目标是了解 r ,一种内部表示,是生成器G的特定层的输出。
X = G(z)= F(r)
我们想检查一下r是否与类别c的对象密切相关。我们知道 r包含有关这些特定对象的生成的编码信息。 我们的目标是了解这些信息如何在内部编码。 作者声称有一种方法可以从r中提取这些单元,然后负责生成类别c的对象。
问题是,如何进行这种分离? 作者提出了两个步骤,即解剖和干预。
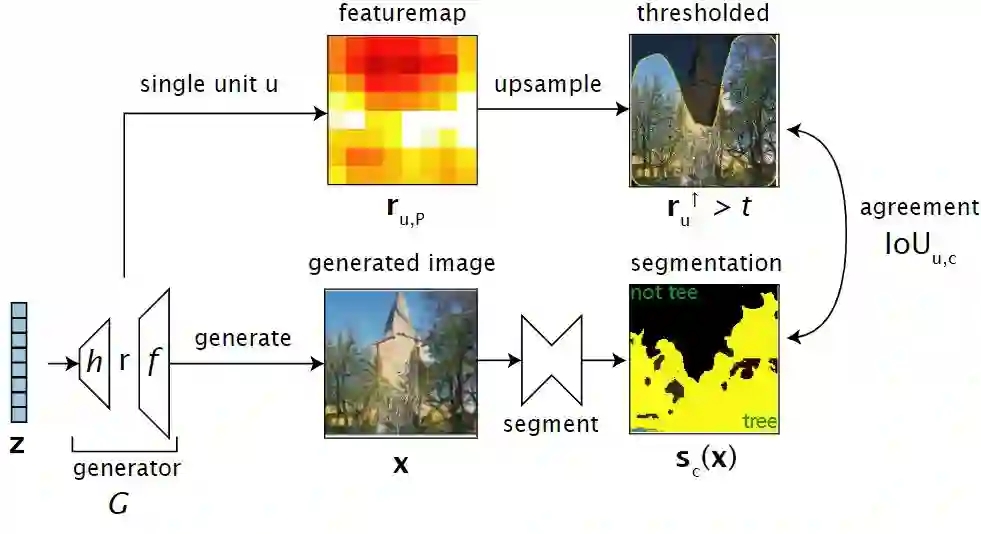
解剖 - 我们想要识别我们感兴趣的类,它们具有明确的表示形式 r。 这是通过比较两个图像来完成的。 我们通过计算x获得第一张图像 。 第二张图是通过在特征图上进行上采样,使其维度与x相匹配 。然后对其进行阈值处理以确定哪个像素被该特定单元“点亮”。 最后我们计算两个输出之间的空间一致性, 值越高,说明类别c与该单位因果效应越强。 通过对每个单元执行此操作,我们最终可以找出类别c的用r中的单元的显式表示 。
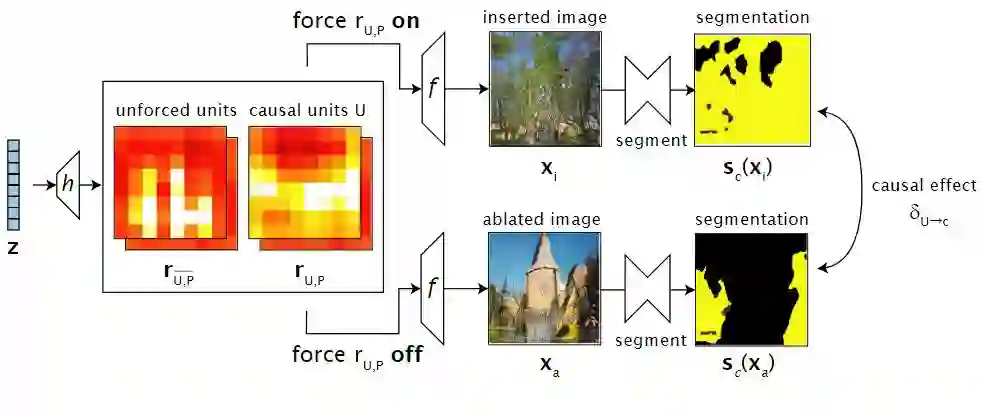
干预 - 在这里我们要做的是确定相关的类别。 现在,我们试图找到每个类别的最佳分割。 这意味着我们一方面消融(抑制)因果单元,希望感兴趣的类别从生成的图像中消失。 另一方面,我们放大它们对生成图像的影响,希望在生成的图片中有更多类别c的物体。 通过这种方式,我们可以了解它们对感兴趣的类别c的存在有多大贡献 。 最后,我们将通过类别分割的两张图片进行比较。 语义图之间越不像越好。 这意味着在一张图像上我们完全“调整”了树木的影响。
实验结果:

a)由Progressive GAN生成的教堂图像,b)给定预先训练的Progressive GAN,我们识别负责生成类“树”的单元,c)我们可以抑制这些单元从图像中“擦除”树... d)放大图像中树木的密度
结果表明,我们正在理解网络的内部概念。 这些见解可以帮助我们改善网络的行为。 了解图像的哪些特征来自神经网络的哪个部分对于解释,商业使用和进一步研究非常有价值。

a)出于调试目的,我们可以识别引入工件......,b)和c)的那些单元并将它们关闭以“修复”GAN
它可以解决的一个问题是生成不合理的图片。即使是训练的很好的GAN有时也会产生非常不切实际的形象,而这些错误的原因以前是未知的。现在我们可以将这些错误与导致视觉伪像的神经元集相关联。通过识别和抑制这些单元,可以提高生成图像的质量。
通过将一些单位设置为固定的平均值,例如对于门,我们可以确保门将出现在图像的某个位置。当然,这不能违反分布的学习统计数据(我们不能强迫门出现在天空中)。另一个限制来自这样的事实,即某些对象固有地链接到某些位置,因此无法从图像中删除它们。例如:人们不能简单地从会议大厅移去椅子,只能减少它们的密度或大小。
Evolutionary Generative Adversarial Networks
论文链接:
https://arxiv.org/abs/1803.00657
主要思想:
在经典设置中,通过使用反向传播交替更新生成器和鉴别器来训练GAN。 这个最小最大博弈是通过利用目标函数中的交叉熵机制来实现的。 E-GAN的作者提出了基于进化算法的替代GAN框架。 它们以进化问题的形式重述损失函数。 生成器的任务是在鉴别器的影响下经历恒定的突变。 根据“适者生存”的原则,人们希望上一代生成器能够以这种方式“发展”,以便学习正确的训练样本分布。
方法:
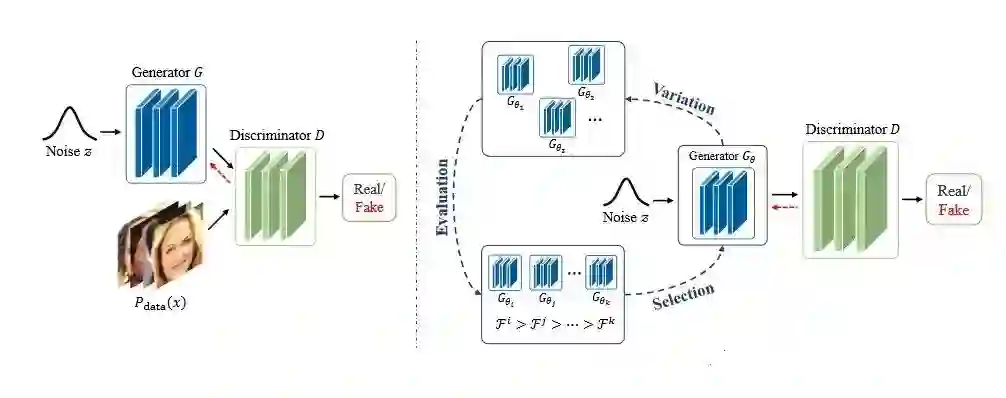
最初的GAN框架(左)与E-GAN框架(右)。在E-GAN框架中有一群生成器 G θ 在动态环境中发展 - 鉴别者 d 。该算法涉及三个阶段:变化,评估和选择。最好的后代保留下一次迭代。
进化算法试图在给定环境中(这里是鉴别器)发展一群生成器。群体中的每个个体代表生成网络的参数空间中的可能解决方案。演变过程归结为三个步骤:
变化:生成器个体 G θ 生产孩子 G θ 0 , G θ 1 , G θ 2 ....通过根据某些突变属性修改自身。
评估:使用适应度函数评估每个孩子,这取决于鉴别器的当前状态
选择:评估每个孩子,并根据适应度函数确定它是否足够好。如果是,则保留,否则将其丢弃。 这些步骤涉及两个概念,应该更详细地讨论:突变和适应度函数。
突变 - 这些是在变异步骤中引入孩子的变化。受到原始GAN培训目标的启发。作者区分了三种最有效的突变类型。这些是minmax突变(其促进最小化Jensen-Shannon散度),启发式突变(其添加反向Kullback-Leibler发散项)和最小二乘法突变(受LSGAN启发)。
适应度函数 - 在进化算法中,适应度函数告诉我们给定孩子与实现既定目标的距离。这里,适应度函数包括两个元素:质量适应得分和多样性健康得分。前者确保,发生器产生的输出可以欺骗鉴别器,而后者则注意生成样本的多样性。因此,一方面,教导的后代不仅要接近原始分布,还要保持多样化,避免模式崩溃陷阱。
作者声称他们的方法解决了多个众所周知的问题。 E-GAN不仅在稳定性和抑制模式崩溃方面做得更好,还减轻了仔细选择超参数和架构(对收敛至关重要)的负担。最后,作者声称E-GAN比传统的GAN框架更快收敛。
实验结果:
该算法不仅在合成数据上进行了测试,还对CIFAR-10数据集和Inception得分进行了测试。作者修改了流行的GAN方法,如DCGAN,并在真实数据集上进行了测试。结果表明,可以训练E-GAN从目标数据分布生成各种高质量的图像。根据作者的说法,在每个选择步骤中只保留一个孩子就足以成功地遍历参数空间以达到最佳解决方案。我发现E-GAN的这个属性真的很有趣。此外,通过仔细检查空间连续性,我们可以发现,E-GAN确实学到了从潜在的嘈杂空间到图像空间的有意义的投影。通过在潜在矢量之间插值,我们可以获得生成的图像,其平滑地改变语义上有意义的面部属性。

原文链接:
https://dtransposed.github.io/blog/Best-of-GANs-2018-(Part-1-out-of-2).html
-END-
专 · 知
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




