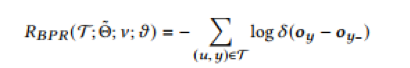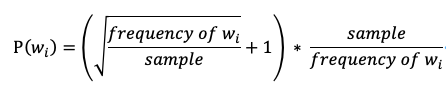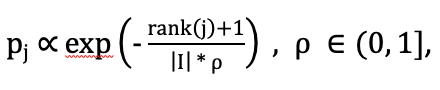新用户和冷用户喜好预测问题一直是推荐系统领域的难题,近期腾讯 QQ 看点(PCG 事业群)团队的一项研究提出了一种迁移学习架构 PeterRec,专门解决新用户和冷用户推荐问题。目前,该论文已被 SIGIR 2020 会议接收。
![]()
新用户和冷用户喜好预测问题一直是推荐系统领域的难题,并广泛存在于计算广告、App 推荐、电子商务和信息流推荐场景。
目前绝大多数解决方案都是基于用户外部画像数据进行喜好预测,因此预测准确率严重受制于画像数据准确率,并且用户画像数据搜集成本高,还涉及敏感的隐私问题;另外,据了解,即便拥有十分精准的用户画像数据,仍然很难针对新冷用户做到个性化推荐,其点击率和相应的 top-N 指标仍然显著低于常规热用户。
那么关于用户冷启动的场景,有没有更好的解决办法呢?最近,腾讯 QQ 看点(PCG 事业群)团队 SIGIR 2020 长文《Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation》提出了一种迁移学习架构 PeterRec,专门解决新用户和冷用户推荐问题。
PeterRec 的基本思想是通过自监督学习一个通用的用户表征,然后将该用户表征应用到下游任务中,例如冷启动用户场景(PeterRec 同时可以解决用户画像预测)。从论文的实验结果来看,这种采用自监督预训练网络学习用户点击行为的方法可以高效地推测出用户偏好等信息。
近年来,迁移学习对 CV 和 NLP 领域产生重大影响,但尚未广泛应用于推荐系统领域。此外,据我们调查,推荐系统领域目前的迁移学习科研工作都没有明确地展示出预训练网络对于下游任务具有 positive transfer 效果。而腾讯具有非常丰富的业务场景,部分业务(例如腾讯视频、QQ 浏览器)具有数亿的 DAU 用户,并且很多用户具有数百上千的点击行为,这些海量的用户点击行为为其他推荐业务场景(例如 QQ 看点、微视、腾讯广告、应用宝、微信看一看)的新冷用户提供了丰富的可迁移知识。
在本文中,腾讯 QQ 看点团队尝试将 PeterRec 模型应用于 QQ 看点的视频推荐业务中。之所以选择 PeterRec 模型,除了其较好的个性化推荐能力外,很重要的一点是,PeterRec 可以实现一预训练网络服务数十 / 百个推荐业务场景的能力。本文将从模型架构、数据处理、模型实现、后续工作四个方面进行介绍。
根据预训练的自监督方式,PeterRec 可以分为单向自回归方式(autoregressive)和双向遮掩式,这一点类似于近期的 NLP 工作,例如 GPT。根据微调阶段模型补丁嫁接插入方式又可以分为串行插入(serial)和并行插入(parallel)。这里只介绍 autoregressive、serial 版本的 PeterRec 模型。
![]()
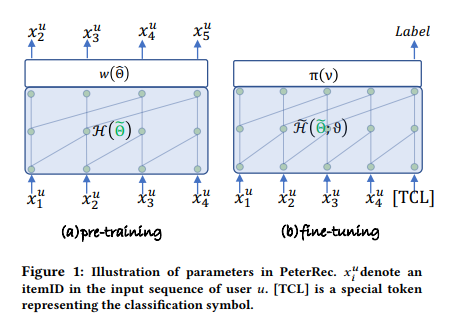
该阶段采用单向自回归的训练方式,根据用户观看的前 k 个视频预测其可能会看的下一个视频。输入是用户在腾讯视频看过的视频 id 序列 [x_1, x_2, x_3,······, x_n-1],然后通过 embedding lookup 的方式获取每一个视频的隐向量并输入到预训练网络中;输出是对应的下一个视频 id,即 [x_2, x_3,······, x_n-1, x_n]。可以看到,PeterRec 模型不需要借助任何图像和文本特征,仅需要用户点击视频的 ID 即可,视频的向量表示完全由模型训练得到,省去了特征工程的步骤, 这种预训练方式已经被应用于 CV 和 NLP 领域,并且取得了非常认可的效果,然而并没有在推荐系统领域得到推广。
微调(finetune)阶段是根据用户在腾讯视频的观看记录,预测其可能会在 QQ 看点感兴趣的视频。输入是 [x_1, x_2, x_3,······, x_n-1, x_n, [CLS] ],其中 [x_1, x_2, x_3,······, x_n-1, x_n] 为用户在腾讯视频看过的视频 ID 序列,[CLS] 是一个特殊的记号,表示在这个位置输出分类结果;输出 Label 是 QQ 看点的视频 ID,即预测用户在 QQ 看点可能会看的 top-N 个视频 ID。
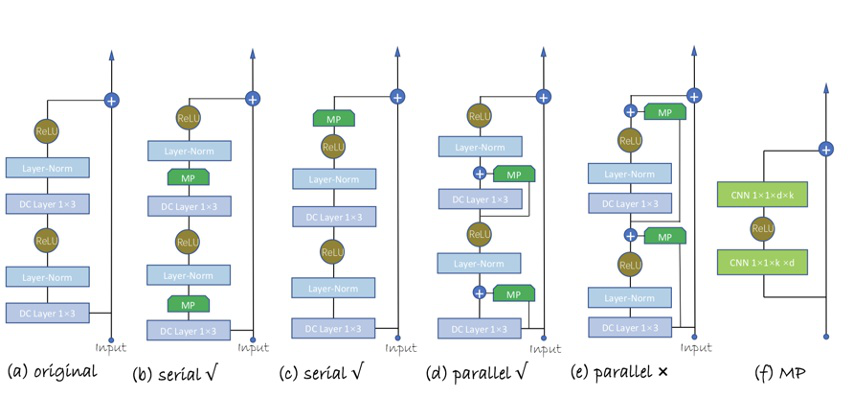
在模预训练阶段,我们将其看作一个超大多分类问题。输入的视频 ID 序列经 embedding_lookup 操作后,提供给后面的空洞卷积网络。整个空洞卷积网络由若干个 residual block(如下图 (a) 所示)堆叠构成。每个 block 包含两个空洞卷积层(DC layer),每层的空洞因子以 2^n 增加。最后通过一个 softmax 层预测出下一个视频。
相较于其他时序模型如 RNN、Transformer 等,PeterRec 模型基于空洞卷积神经网络构建大规模预训练模型,同时通过叠加空洞卷积层达到可视域指数级的增加,这种网络结构使得它在对超长的用户点击序列进行建模时更加高效。而相比之下,RNN 模型在对超长序列建模时,通常会遇到梯度消失和梯度爆炸的问题;而像 Transformer 这类 self-attention based 的模型,时间复杂度和显存需求会随着序列长度以二次方的级别增加。
![]()
为了实现对预训练网络参数的最大化共享,微调阶段仅对预训练模型做了两处改动:
1)在 residual block 中以串行的方式插入模型补丁(如上图 (b) 所示),每个模型补丁由一个瓶颈结构的残差块构成(如上图 (f) 所示),且参数量不到原始空洞卷积的十分之一;
2)直接移除预训练 softmax 层,然后添加新任务的分类层。
微调通常要重新训练整个网络,并更新模型所有参数,因此从参数量的角度来看,微调是非常低效的。相比这种微调所有参数的方式,PeterRec 模型在微调阶段仅对模型补丁和新任务的 softmax 层中的参数进行更新,参数量大大减小的同时却可以达到与微调所有参数相当甚至更好的效果。而且,由于仅有少数参数参与更新,PeterRec 模型还具有很好的抗过拟合能力。
预训练阶段采用 softmax 的多分类交叉熵损失函数。在实际操作中,腾讯视频中的视频经过各种过滤 ID 映射后还有数百万级别的有效视频。如果采用 full softmax,训练效率会很低,所以这里采用了 tf.nn.sampled_softmax_loss,实际只采样了 20% 的 item 作为负样本用做训练,当然其他 efficient 采样和 loss 设置也同样适用,例如 NCE loss 或者下文提到的 LambdaFM 方式。
对于排序场景,pairwise 类方法要比 pointwise 类方法(直接看做分类或者回归)更合适,所以微调阶段采用了 pairwise ranking loss (BPR)。pairwise loss 构造样本时我们同时考虑两个 item 比如 x_i 和 x_j,这两个 item 是有顺序的,比如用户在排序列表里点击了 x_i,而未点击 x_j,我们可以看做 x_i 要优于 x_j。
因此,我们需要为每一个真实物品 label(y)采样一个负样本 y-,通过计算用户的隐向量与 y 和 y- 的隐向量的内积作为两个 item 的打分 o_y 和 o_y-,然后算出最终的 BPR loss:
![]()
具体采样时采用 LambdaFM(CIKM2016)方式,其效果显著好于随机采样和仅仅使用曝光未点击作为负样本的方式。
这里介绍我们在优化模型过程中几个有效的数据处理方法:
由于涉及到不同业务数据,腾讯视频业务流水均需要封闭域中安全获取,得到用户的原始观看序列后,需要过滤一些过热或过冷的视频 item(过热的视频没有区分度,无法看出用户特定的偏好;过冷的视频由于出现次数少,模型学得的隐向量很难准确反映视频的信息,并且没有充分的训练很容易成为噪声而影响最终效果)。过滤后,腾讯视频的视频数量在 200w+ 的级别。
在预训练阶段,我们采用了 sampled_softmax_loss 来代替 full softmax loss,tensorflow 的 sampled_softmax_loss 函数在进行负采样时,是通过 log_uniform_candidate_sampler 进行的,使用这个 sampler 的效果是:item 编号越小,它被采样为负样本的概率越大。针对这种情况,我们在对视频 item 进行编号时,按照 item 在播放序列中的出现次数降序排列,然后从 0 开始编号。(原因可见下文「LambdaFM 负采样」)。微调阶段则采用 BPR loss,没有用到 log_uniform_candidate_sampler,因此可以不用按 item 频率进行编号。
首先,我们先从腾讯视频的流水数据中拿到用户 a 的播放序列。经过过滤(根据视频的播放时长和完播率过滤掉自动播放的视频)和去重(对原始播放序列的相邻 item 去重)后, 取用户 a 最新的 50 个播放视频作为一个预训练的训练样本 [x_1, x_2, x_3,······, x_50](若用户的播放序列长度不足 50,则在前面填充 [PAD])。用户播放序列行为可以根据计算资源设置,如果具有较充足的计算资源,则可以将行为序列设置得更大,如 200 甚至 1000。
以相同方式从 QQ 看点的流水数据中拿到用户 a 的播放行为 [y_1 y_2, y_3,······, y_m]。这时,根据用户 a 在腾讯视频和 QQ 看点的播放序列,我们可以为用户 a 构造 m 条 微调的训练样本:[x_1, x_2, x_3,······, x_50, [CLS], y_1], [x_1, x_2, x_3,······, x_50, [CLS], y_2], ...... , [x_1, x_2, x_3,······, x_50, [CLS], y_m]。(需要注意的是,只有腾讯视频和 QQ 看点的交集用户才能用于构造微调的训练样本,预测时候则不需要。)
经过上述处理,对于不同观看历史的用户,PeterRec 模型预测出来的 top-N 结果已经具有一定的相关性。实际的 case 分析显示,这些强相关视频仍然容易出现得分较低于高频 item 的情况,如排在 top100 之外,但是在头部都出现了 item vocab 中最热的那些视频,由此可见高频 item 对模型的影响还是很大。为了缓解 top-N 推荐结果中的头部效应问题,减少高频 item 对模型的影响,我们尝试了不同的均衡正负样本的策略,其中下列两种较为有效:
Word2vec 的实现中,会指定一个概率 P(wi) 对高频词进行打压,同时保留所有的低频词。实际源码中,高频词在每个样本中被保留的概率实现如下:
![]()
其中,参数 sample 用于控制降采样的程度,sample 值越小,降采样强度越大,实际使用中需要根据 item 的频率分布来确定,一般取 0.001 ~ 0.00001。
于是,我们在构造微调训练样本的时候,先根据概率分布 P(w_i ) 对用户在 QQ 看点的播放序列 [y_1 y_2, y_3,······, y_m] 进行一次降采样,按照一定比例丢弃一些高频的视频 item。然后再与其在腾讯视频的播放序列做拼接,得到微调的训练样本。
关于负采样,常用的做法有两种:1)采用曝光未点击作为负样本;2)从总的候选池子中随机取样。
我们发现(1)方法效果较差,因此采用从候选 item 池子随机选择 itemID,但这种方式仍然存在一定的缺陷,它采样出来的样本多数集中在长尾处,LambdaFM 论文中是这么描述的:
In fact, it has been recognized that item popularity distribution in most real-world recommendation datasets has a heavy tail, following an approximate power-law or exponential distribution.
Accordingly, most non-positive items drawn by uniform sampling are unpopular due to the long tail distribution, and thus contribute less to the desired loss function. Based on the analysis, it is reasonable to present a popularity-aware sampler to replace the uniform one before performing each SGD.
这里 popularity-aware sampler 的意思是让更受欢迎的 item 有更大的几率被采样为负样本,这其实是符合直觉的,因为相比那些不受欢迎且用户没有观看的视频,那些受欢迎但用户没有观看的视频更具信息量,更能帮助我们发现用户的偏好。我们发现 LambdaFM 论文提供了 3 种负采样方法,本文这里采用了第一种负采样方式,在后续工作我们也会尝试动态负采样,根据论文动态负采样通常推荐 top-N 效果更好。
微调训练过程中,我们采用了 LambdaFM 中的 Static & Context-independent Sampler 进行负采样,即视频 j 被采样为负样本的概率 pj 与它的热度排名 rank(j) 呈正相关:
![]()
其中,rank(j) 表示视频 j 在所有视频 item 集合 I 中的热度排名,ρ 表示阈值,通常取 0.3-0.5。
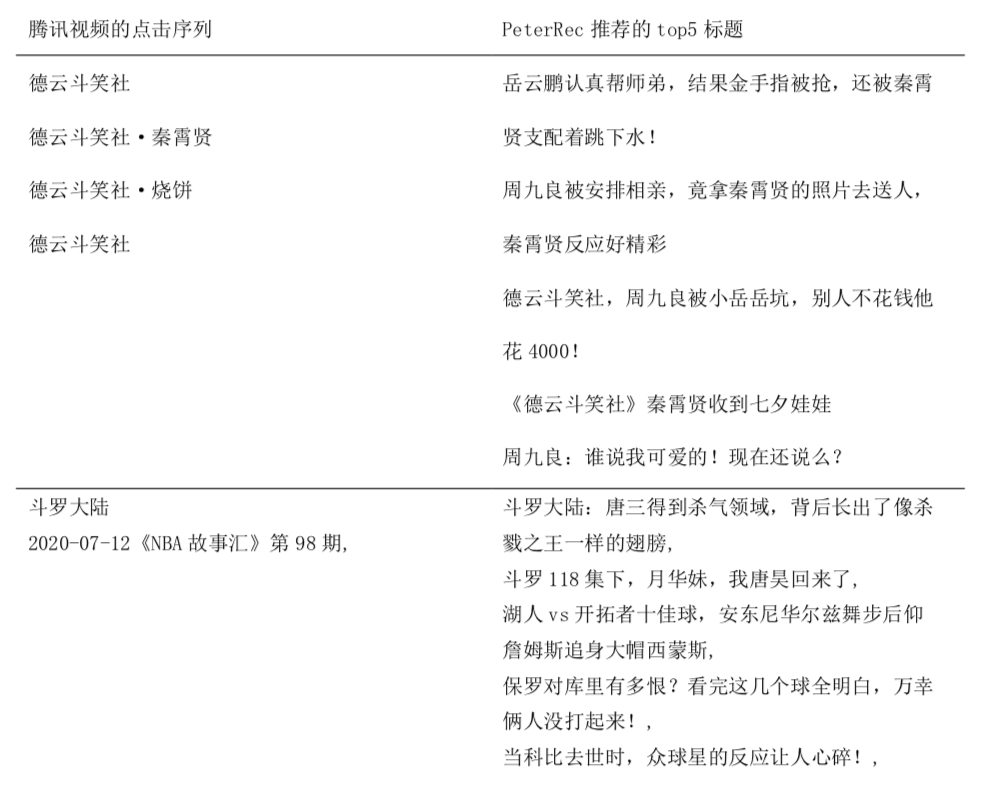
前面的处理过程已经可以很精准地实现看点视频推荐的个性化或者相关性,我们随机挑选了两个实例(参见表 1)。同时,这还能有效处理用户在腾讯视频和 QQ 看点的偏好不一致问题:在具体的 case 分析中,我们发现部分用户在腾讯视频看的大多是卡通类的视频,而在 QQ 看点很少看这类视频,此时,PeterRec 模型推出的视频更接近于他们在 QQ 看点看过的真实视频,而非卡通类视频。我们推测主要原因可能是该部分用户在腾讯视频大多是学龄儿童甚至是学龄前期,主要是使用其父母账号观看腾讯视频,而在看点账号大多是其父母在使用,因此推出的视频偏向于年轻父母偏好。
![]()
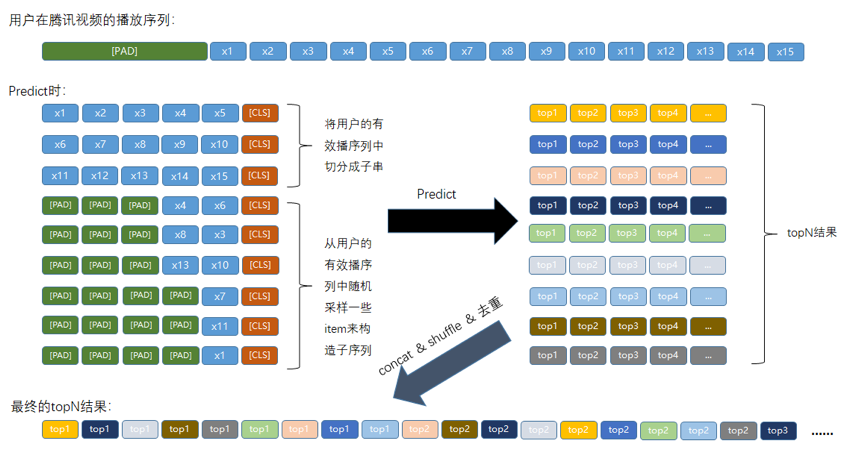
后续为了增加推荐 top-N 结果中的多样性,我们在 Predict 的过程中做了一些改变:
![]()
图 3:Predict 处理
如上图所示,我们在为用户生成推荐列表时,不再是直接将用户在腾讯视频的播放序列输入到模型中,我们将其拆分成了两类子序列:
第一类是播放序列里的有效播放序列的子串。取子串的原因是,我们发现,用户观看的相邻视频之间兴趣点比较一致,也就是用户会在某个时刻连续观看一些同类的视频。这使得子串里的视频大多属于同一类,用户的兴趣点明确,更有利于模型找到用户的偏好。
第二类是从用户的有效播序列中随机采样一些 item 来构造子序列,原因是用户的播放序列中往往包含了多个种类的视频,随机构造子序列引入了随机性,可以更好地丰富 top-N 结果中包含的视频种类。
最后将用户对应的所有子序列的 top-N 结果,进行 concat、shuffle 和去重,得到用户最终的 top-N 推荐列表。
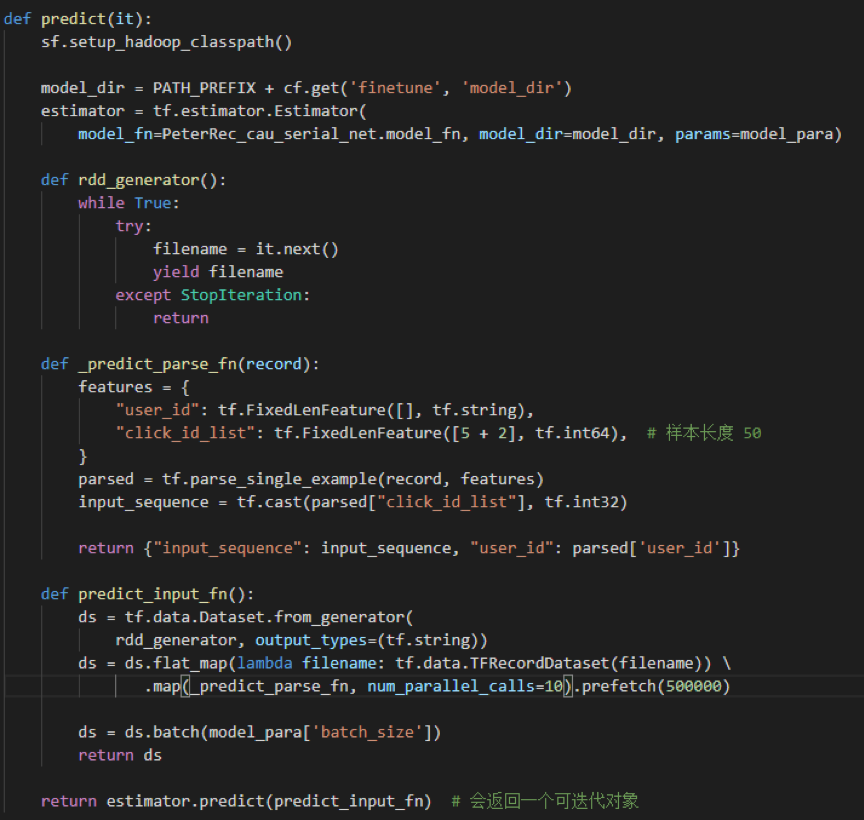
模型代码是由参考原始论文源码,采用 tensorflow estimator + tf.data + spark-fuel 框架实现,完整代码可参考 git
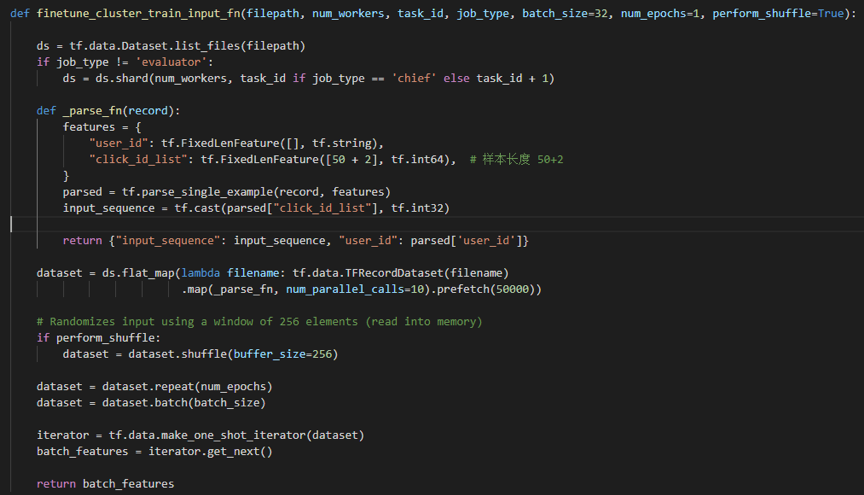
Google 官方推荐处理中大数据集时,先将数据集转化为 TFRecord 数据,这样可加快数据读取和预处理中的速度。因此,我们先使用 spark 对训练数据进行处理,然后转成 TFRecord 的格式传到 hdfs 上。TFRecord 做好了,要怎么读取呢?可以通过 tf.data 来生成一个迭代器,每次调用都返回一个大小为 batch_size 的 batch,这样可以很方便地支持多线程读取数据。关于如何优化 input pipeline 的性能,可参考 Better performance with the tf.data API、How to improve data input pipeline performance?
需要注意的是,预训练阶段和微调阶段的 click_id_list 长度是不一样的。
![]()
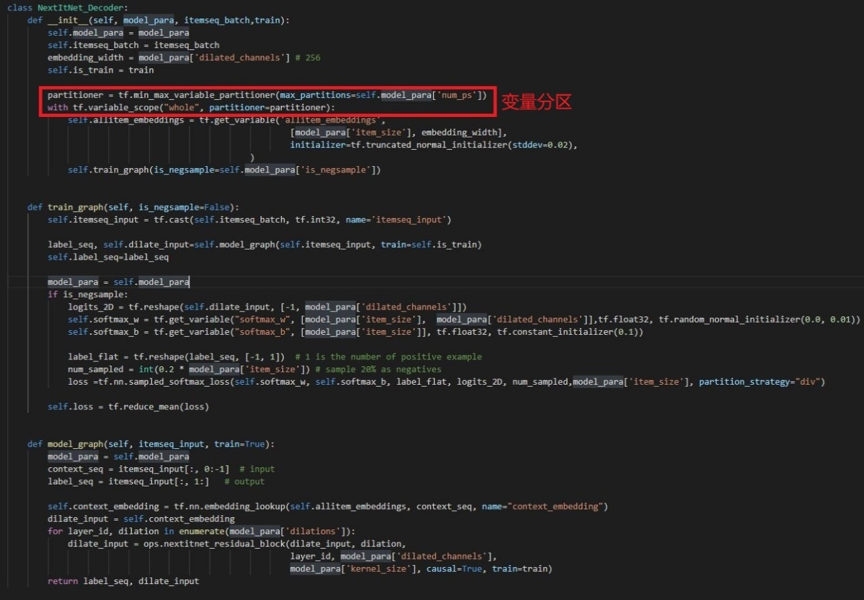
PeterRec 模型的网络结构比较简单高效,且空洞卷积的使用也使得模型能够并行训练和降低显存需求,这里直接复用了源码中的模型结构和模型补丁结构。另外,在采用 PS 策略进行分布式训练时,为了均衡 ps 节点的负载和加速训练,最好是对模型参数做分区,以便模型参数被均匀分配到各个 ps 上。
![]()
模型训练的过程采用 tf. Estimator 实现。tf.Estimator 的特点是:既能在 model_fn 中灵活的搭建网络结构,也不至于像原生 tensorflow 那样复杂繁琐。相比于原生 tensorflow 更便捷、相比与 keras 更灵活,属于二者的中间态。
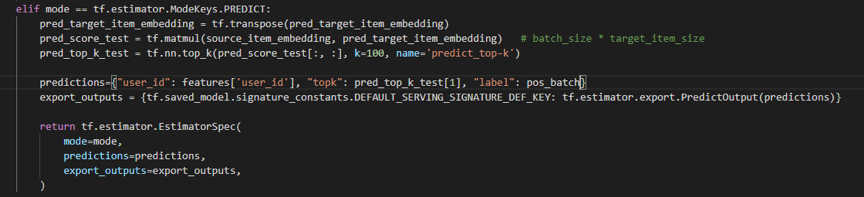
实现 tf.Estimator 主要分三个部分:input_fn、model_fn、main 三个函数。其中 input_fn 负责处理输入数据,model_fn 负责构建网络结构,main 来决定要进行什么样的任务(train、eval、predict 等)。input_fn 在上文「输入处理」一节中已经介绍过,这里只介绍 model_fn 和 main 函数。
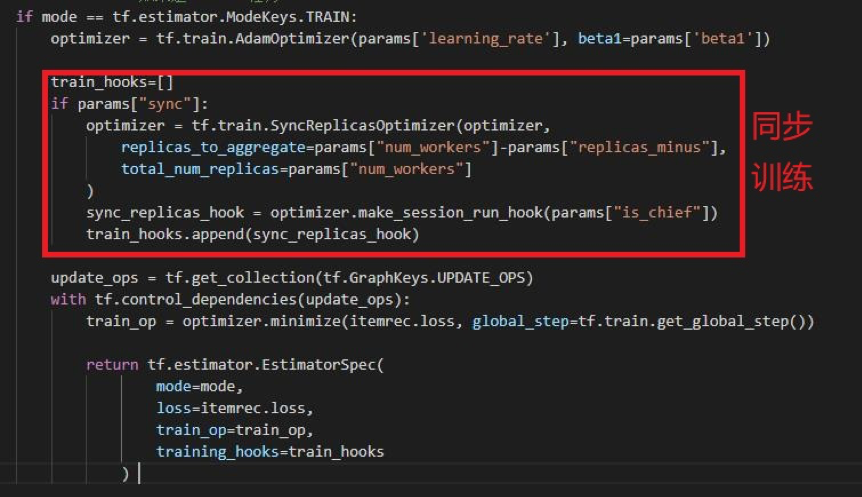
model_fn 函数:模型的网络结构、loss 已在上一节中介绍过,这里只给出了定义 train_op 的部分。这里采用了同步更新机制,每个 worker 节点直接访问外部存储系统(hdfs)获得一个 batch,然后计算 loss 和 gradient,汇总到 PS 节点,当所有 worker 节点都完成一个 batch 时,才更新一次参数;在实际实验中,我们通过调节 replicas_to_aggregate,我们通过忽略几个速度慢的 worker 梯度来加速训练 。
![]()
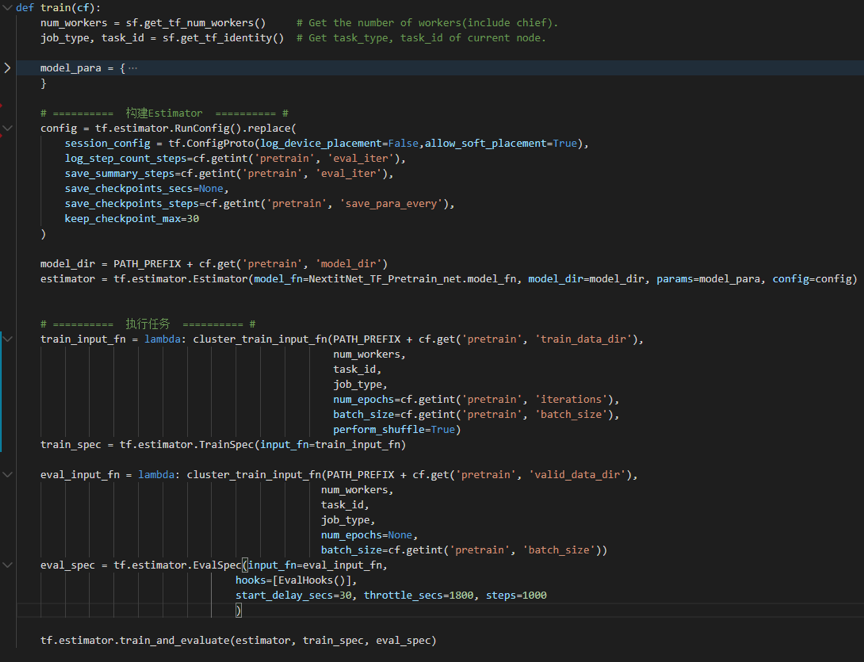
main 函数:有了输入数据 input_fn 和模型 model_fn,main 函数就负责如何使用模型和数据。这里使用 train_and_evaluate 来一边训练一边输出验证集效果。另外,hook 可以看作是在训练验证基础上实现其他复杂功能的「插件」,比如本例中的 EvalHooks(用于计算 NDCG 等评估指标)。
![]()
离线打分时,采用 spark-fuel 的分布式预测方式,如下图所示。需要注意的是,预测过程其实就是一个 Spark 作业,没有 TensorFlow Cluster,每个 Spark Task 中通过 TensorFlow API 加载模型,对 RDD Partition 中的每条数据做推理。
![]()
在模型的预测阶段,我们需要对每一个模型输出的用户向量(即 [CLS] 对应的最后一个 hidden layer 的输出),快速求出最相关的 Top-K 个视频,如下图所示。当 item 数量较大时,下图中直接计算内积的速度会比较慢,可以采用 faiss 的 IndexHNSWFlat 来完成 Top-K 的查询。参考长视频推荐:基于欧氏转换的 top-k 内积解决方案。
![]()
后续我们将推进 PeterRec 在其他业务场景上的尝试(包括画像预测), 充分利用 PeterRec 的参数高效特性优势,同时我们近期将发布 PeterRec 完整的工程化代码和配套迁移学习数据集用于学界和业界研究使用。
另外,腾讯看点推荐团队近期推出用户表征的 lifelong learning(文献 4)模型 Conure,是首个能实现不同推荐任务,不同业务场景间的可持续学习算法模型, 离线实验结果显示该方法可以实现一个模型支持数十个推荐业务,尤其擅长解决冷启动问题和画像预测问题。如果各个下游任务之间存在一定的关联性,那么 Conure 可以比 PeterRec 取得更好的预测准确率。
[1] A Simple Convolutional Generative Network for Next Item Recommendation. Yuan et al, 2019, WSDM.
[2] Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. Yuan et al, 2020, SIGIR.
[3] LambdaFM: Learning Optimal Ranking with Factorization Machines Using Lambda Surrogates. Yuan et al, 2016, CIKM.
[4] One Person, One Model, One World: Learning Continual User Representation without Forgetting. Yuan et al, 2020, Arxiv: https://arxiv.org/pdf/2009.13724.pdf.
Java工程师入门深度学习(二):DJL推理架构详解
DJL是亚马逊推出的开源的深度学习开发包,它是在现有深度学习框架基础上使用原生Java概念构建的开发库。DJL目前提供了MXNet,、PyTorch和TensorFlow的实现。Java开发者可以立即开始将深度学习的SOTA成果集成到Java应用当中。
11月3日20:00
,李政哲(AWS软件开发工程师)将带来线上分享,介绍DJL推理模块并结合具体场景讲解各模块使用方法,推理 API 的使用方法以及如何优化推理速度,如何部署在微服务、大数据服务以及移动端并搭配客户成功案例的讲解。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com