视频推荐中用户兴趣建模、识别的挑战和解法

作者|李玉
编辑|Emily
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
以下为演讲实录:
本文将介绍一下优酷个性化搜索推荐的服务,优酷在视频个性化搜索推荐里用户兴趣个性化表达碰到的挑战和问题,当前工业界常用的方法,以及我们针对这些问题的尝试。
首先优酷已经非常大量的全面的采用了大量的个性化的搜索推荐技术,今天优酷为几个亿用户提供的服务是全面的,千人千面的个性化服务。在优酷的首页,所有用户看到的内容、推荐的内容都是根据用户个性化的兴趣匹配的完全不一样的内容。在优酷各个垂直频道,像电影频道、综艺频道,也完全采用个性化技术做分发。优酷有大量短视频,优酷短视频信息流的场景,也是大量的采用个性化技术在做分发。优酷的用户和内容都用大量算法做匹配。
今天优酷有多一半视频播放是通过个性化搜索推荐技术做分发的,个性化搜索推荐技术对于优酷 CTR,包括人均播放量,人均时长,留存率都有非常大的提升;更重要的是个性化的算法对于帮助用户发现好的内容,帮助互联网优质内容可以精准触达适合它的受众,在这一点上是贡献更大的,可能比单纯看 CTR 提升多少,或者人均播放量提升多少更重要。而且有时候帮助用户发现好的内容和帮助好的内容触达用户,有时候并不适合简单的业务指标,像 CTR、人均播放量不一定是一致的,所以怎么把用户的兴趣识别更准,怎么把内容推送的更准,这个事情比单纯的关注点击率、人均播放量提升更重要。
做视频个性化的兴趣的识别还是有非常多的挑战。
第一,优酷业务模式最核心的重点是一些头部内容,像电影、电视剧、综艺、动漫这些核心的头部内容,头部内容用户的选择成本特别高,用户要追几十集电视剧的话,它要考虑很多问题,很难真正选择开始追一个剧或者一个综艺,所以推荐的成功率往往偏低的,比较困难能够让客户真正推荐方式追一个剧。用户来使用优酷服务的时候目的性往往是比较强的,他带着比较强的比较精准的意图过来,发现和浏览逛的心智偏低。
第二,长视频的节目选择空间往往比较有限,算法更适合分发大量的长尾的内容,但是对于优酷这样的场景,选择空间有限的情况下,怎么把推荐这个事情个性化的服务做得更好,这也是比较大的挑战。
第三,头部节目用户行为往往是比较稀疏的,很多头部节目有大量的用户是不够活跃,每个月只有小于三个视频播放的行为。如果再看优酷短视频信息流的场景,用户可能有几百个行为。同样一屏会推荐比如 30 个,在短视频的场景可能对这个用户的了解是几百个观看行为,我推荐 30 个,但是长视频头部的节目里我只知道用户看过三个相关的视频,三个头部的视频,要推荐 30 个节目,所以是两个完全不同的问题,可能需要完全不同的做法,完全不同的模型和算法去解。
另外数据的噪声很多,数据的分布往往比较趋热,传统常见的模型甚至复杂的 DAN 的模型往往效果不好,因为数据的分布噪声非常大,数据的稀疏性比较大。从数据本身角度来看,视频的兴趣非常感性和微妙的,非常复杂,我们刚刚开始做优酷个性化服务的时候,一开始想把电商很成功的做法和系统搬过来,发现会碰到很多问题。对比一下电商,用户的兴趣非常简单明确,我想买一个电视或一条牛仔裤是非常明确的,他的意图是高度结构化,比如类目体系非常清晰,但视频是非常感性和微妙,比如有些用户喜欢武侠片,但是并不喜欢成龙这一类的武侠片,他是存在某种非常复杂的因素在里面。而且视频内容的兴趣往往是非常动态的,不是静态的,不断的演进,不断的发展。比如科幻的兴趣,有的是轻度科幻,也有中度的,也有重度的,是逐渐发展过来的。很多时候用户视频的内容兴趣还体现了很多亚文化的角度,比如二次元的角度,比如文艺青年,这些角度用户的观看兴趣是不同的。有时候用户视频兴趣体现用户个人的认同,视频维度非常多样,非常正交,越来越细分和多样化。比如我们有时候看一些案子,发现有的客户什么类型都看,也会看魔幻,也会看动作片、武打片,也会看新的,也会看几年前。后来发现他看所有的东西都是大制作,都是制作成本很高的,大制作可能也是兴趣的维度;还有前一段时间《白夜追踪》的剧,很多人描述是美剧质感,这是一个很好的维度,很多用户会喜欢这个维度。很多时候你的视频就在于你怎么梳理类目体系,包括用户对于内容的兴趣是不喜欢重复,识别出来适合他喜欢的还不够,因为用户对兴趣度和多样性的要求是远远高于其他的品类。
我们在不断思考的是用户这些内容的兴趣怎么通过传统的推荐的技术能不能表达好?能不能把这么复杂多样的微妙的用户在视频观看的兴趣表达出来?我们的模型有没有表达的能力表达出来这么复杂的规律? 我们的特征有没有足够强的特征表达这些事情。
识别用户的兴趣是非常重要的,往往一个实际产品的问题不能用简单一个方式去表示。
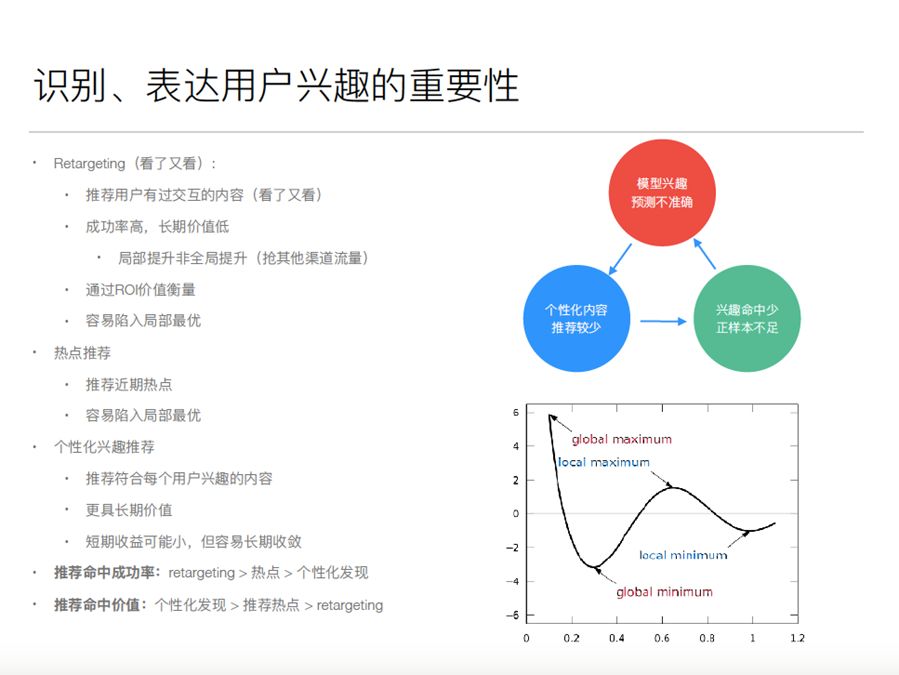
大部分传统的推荐算法都是用点击率预估去训练一个模型,推荐的内容可能有几种类型,一种类型是看了又看,推荐用户看过的,有过行为的东西,做过广告的人知道一个概念,就是用户有过交互的东西。第二类是热点,比如统计 CTR 很高的东西,除了这两类之外,才是真正去猜测和预估兴趣用户,根据用户兴趣去做推荐的。一般的模型会推这三类东西,这三类东西不一样,如果做过这个事情的人都知道,最有效的点击率最容易高的是推用户有过行为的东西往往很容易有效,但是推这些类型的价值率不高,推荐率高是因为难度比较低,成功率容易高,真正个性化的内容通过猜测用户的兴趣点去做推荐,往往你的成功率偏低,所以点击率偏低,所以从成功率来讲推荐有过行为的最高。推荐命中或者不命中的价值,都是个性化推荐是更高的。即使你推荐的某种给用户没有命中,也会提供一个很负样本信息,你对这个用户的兴趣点了解更深入,知道这个兴趣不感兴趣什么。相反如果你推的都是成功率很高的东西,你的模型长期来讲很容易陷入一个局部自由,因为你收到正负样本没有什么变化,你没有真正探索到用户的兴趣。
针对上边这些视频推荐里的挑战,我们来看看常见的工业界的做法,基本流程作为召回,然后筛选一部分侯选,然后做一个排序模型,很多大部分的公司都是这样做的。排序模型里会有一些统计特征、用户的画像,画像里包括 DEMO 的特征,还有基于内容标签的用户画像的特征,包括高微组合特征等等。如果从结构来讲的话,可以分为四个层次,最下面是数据层,然后是召回层,然后是一些特征工程的层次。在数据层面往往是 ETL 数据处理、采样。优酷做了大量不同的召回,经典的像 CF,包括 DNA 的 CF,还有 Slim,还有基于明星的召回,基于热度热点和趋势的召回。特征是比如说 Item 的特征。包括用户画像常用用户搜索记录、浏览记录。模型也有各种各样的。这些都是蛮常见的做法。
这些做法对于刚才我描述的视频兴趣的表达还是有很多问题,我们可以具体看一下。比如从特征的角度,使用这些 DEMO 往往有一个特征,用户视频兴趣往往和用户的年龄、性别和地域关系不大,比如三线城市 50 岁男性和一线城市 30 岁的女性看的东西是差不多的。基于用户标签画像,常见的做法是基于这个内容的标签去生成一些用户的画像,基于一些统计方法,针对这些特征做一些高纬的组合,比如用 DNN 也好,在视频推荐场景里,特别是头部内容推荐的场景里,行为过于稀疏,数据噪声比较大的时候,在高纬空间组合特征往往效果不是特别好。因为所有空间是很大的,往往很复杂的模型并不是一个全局收殓,往往收敛到一个局部,会发现组合出来的特征是不太准确的。在噪声大,数据稀疏的产品 i2i 里往往超过很好,在场景噪声很大的时候,对于数据降纬的处理。当我们把空间投影到 I 空间里,通过时间积累有很多用户产生行为,这时候数据量就会大很多。所以识别出来之间相似度就会好很多。我们可以理解成某种降纬的降噪对于数据稀疏性和噪声过大一种降噪的处理。基于这个相似度再作为特征放到排序模型里。
导致一个问题就是很容易丢失很多重要信息,比如很多用户看有的是因为喜欢这个主演,有的是因为我喜欢这个类型,也有可能因为这个剧比较热,所以去看,但是并不喜欢这个类型。这个剧热度过了之后就不看了。所以在这种情况下没有办法很好的表述这些信息。另外一个问题,不同的用户群体对于全局也很难特点好的表示不同用户群体的信息。下面这个图是 16 年解释的现象,当你去计算 C 和 I 之间相似度的时候,在 A 的用户群体里相似度比较高,但是在 B 这个群体里相似度是零,因为没有看过 I。当你算一个全局相似度的时候,它是这两个相似度的平均,对于 B 的相似度计算是不准确的,但是也只能解决一部分这样的问题。另外往往力度过细,没有像标准这样有一定的扩展性,趋热是很常见的现象。比如哈利波特,像这样的大热片跟所有的相似度都很高,怎么做热点的打压也是一个问题。
下面介绍一下针对这些问题我们的一些尝试。首先还是认为要非常精细地去做好用户的画像是非常重要,传统做法以内容标签为基础产出大量内容标签、类目体系、导演演员,然后根据用户观看内容的行为,对于各个内容的标签分类产生一些用户的画像。传统的做法是基于统计的方法,并没有很细致的解决好这个问题。
为什么我们觉得做好用户兴趣画像很重要?我们解这个问题很大的挑战在于数据的稀疏性很高,数据里面的噪声很大。对于稀疏性高、噪声很大的问题,如果你用一个很复杂的模型去解这样 N2N 的问题,模型很容易受到噪声的干扰,所以这个效果往往不好。右边这个图一般做法是你的输入是用户的行为,用户的数据,输出就是给用户推荐。如果简单用一个 MEDOL 解决这个问题很容易受到噪声影响。因为现在虽然技术发展很快,但是很多模型没有我们想象那么强大。我们做法是把这些问题拆解成若干个子问题,不是把一个 N2N 的问题 MEDO,而是拆解成若干个子问题,让 MEDO 解决更容易的问题,然后把人工的业务理解加入进去对这个问题做降纬和降噪,我们希望学到一个很准确的用户兴趣的表达,然后把用户的行为首先表现在用户兴趣表达上,把这个问题拆成两个问题,基于这个兴趣表达再去做推荐,拆成两个子问题,可以进行人工空间的整理、系统的建设、类目的建设,包括降纬降噪的处理。
这个思路并不新,学术界过去有很多工作,比如像 CTR,基于这样模型可以更精细的把用户画像解的更准。近几年也有很多围绕这个方向有很多进展,我们尝试有几个工作,像 CTPF 工作,还有下面的工作,都是效果蛮不错的。
介绍一下在这个方向上的进展和尝试。它把概率分布的假设换成播送分布,更多假设这个数据分布更稀疏,更符合实际用户在视频观看里的一些规律,因为用户在视频观看的时候,所谓时间是有限,不论我对这个兴趣再高,我只能看有限的视频,所以分布是偏稀疏。播送分解的思路效果更好。
我们实际应用的时候和学术界的假设还是不太一样,我们除了视频文本信息,因为视频文本信息在实际工业运用里往往噪声比较大,我们视频文本信息,比如视频的抬头,视频的简介。往往多视频是有点标题党,抬头并不能很好表示这个视频所讲的。实际应用里有大量编辑团队对这个视频打了标签,标签的问题有时候偏主观,也有随机性的噪声里面,我们可以把这些因素用一个概率模型去 MEDO 出来,我们认为这种标签也有某种随机分布。
包括视频热度的维度,我们希望把热度维度单独拆开,希望能够看到哪些用户是比较喜欢热点的,因为这个东西热才去看的,哪些用户是真正因为这个东西的类型才去感兴趣看的。按照这样的思路,我们可以把视频文本的维度、标签的维度、搜索词的维度,比如主演、主角、配角、导演这些信息都可以进行一个独立的分布。EM 迭代并不是全局收殓的方法,往往收殓到局部最优,我们需要做大量人工审核工作,做一个降噪的工作。审核以后把并不好的去掉,做第二次初始值,然后再做迭代,迭代以后会收殓。我们对这个方法做了各种实现上的性能上的优化,基于分布式架构,改造成一个分布式,让它可以处理优酷几亿视频和几亿用户的行为。
用户内容兴趣有复杂的规律,有些兴趣是长期,有些星期是短期的,当兴趣点满足了之后更追求多样性,过一旦时间又希望再看到这一类的内容,我们用了 GRU 的结构希望把用户兴趣时间维度上的信息能够学出来。网络输入是用户观看的 ID 序列,包括观看序列里标签的序列,经过 GRURECNET,再经过多个输出接层。我们做了一个改进,用户观看序列是非常不等距的,有的用户观看是一个月只有一个行为,有的一天有很的行为,跟 GRU 假设不一样。除了增加采样的间隔以外,把 GRU 改成 Time gatek。
刚才提到一个挑战很多用户的行为是比较有限的,我们对这些用户兴趣并不能识别很准,所以我们用了传染病模型建模的方式。中度活跃用户早期也是行为比较少的,我们可以看用户是怎么从早期行为稀少的阶段逐渐演变到中度活跃度比较高的情况。我可以计算一个用户各种兴趣点演进概率和演进的方式,基于这个预测用户将来会对什么感兴趣,根据这个去建模,把这个作为特征放到 MODEL 里,然后基于这个预测的概率做对用户兴趣的捕捉。
关于数据稀疏性的问题,最直接的解法就是通过随机流量有意识收集更多的数据,行为数据,包括交互数据。这里有一个问题,当其实数据是很稀疏的时候,当 N×N 的 I2I 的矩阵有很多元素很稀疏的,explore 收集数据需要很多流量,代价很高。所以我们考虑 NystromCUR,N×N 矩阵可以用这个矩阵当中的 C 行,C 是远远小于 N 的。所以沿着这个思路,通过 statistical leverage score 选择 C 个 item。重点 explore 对于 c 个 item 有过观看的用户。只有 C 行是比较稠密的,C 行数据是很准确的。当 C 行算的比较准的时候,还可以乘以 N×N 的矩阵。
另外可以构建一个 HIN 图,每个节点就是一个标签,按照标签的相似度去做迭代,通过迭代会收殓,下面是一个例子,可以像汽车建筑队、迷你卡车之类的,都是给小朋友看的视频,但是都是表达一类用户的兴趣点,可以通过这种方式找到更多用户的兴趣点。
特征交叉也是一个比较有趣的问题,算法模型能力有限,End2end 模型精准 capture 个性化特征能力有限。最优解在非常高纬空间中,由于噪音与模型收殓能力问题,需人工辅助降低搜索维度。使用交叉特征的统计值,效果好于使用离散交叉裸 id 特征。结合业务理解,辅助模型更好 capture 个性化特征。结合统计量的 variance 进行噪声过滤。
这是在优酷个性化搜索排序里的模型,这个模型会分成若干个域,域内部是全连接,然后还有 concat,还有域内信息的二次编码,还有稀疏全连接。
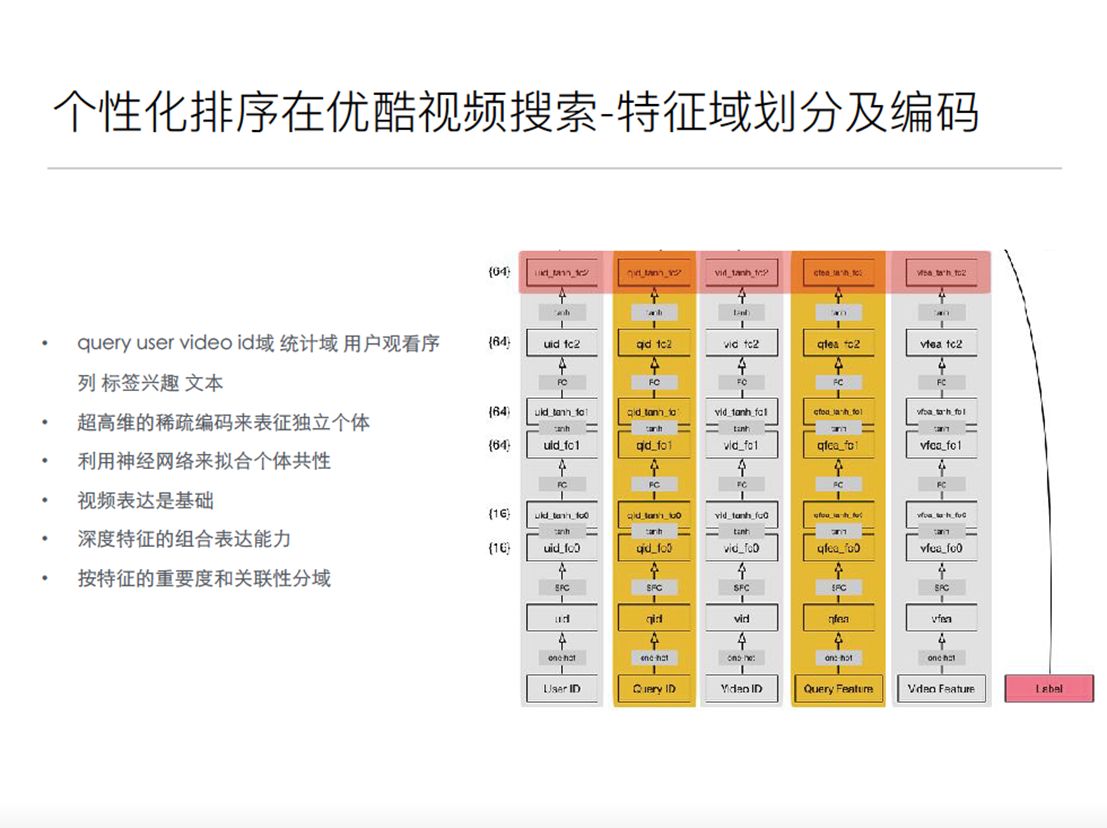
这个模型是当你的数据没有那么稀疏的时候,你的做法很简单,就是用足够深的表达能力足够深度的模型就可以把这个问题解的很好。输入里像用户的域是用用户所有观看记录,所有的视频观看的 ID 全部都放进去,每一个用户就是一个 ID 序列。视频维护有视频各种文本、标题,包括视频各种标签分类组合起来表达这个视频。这个问题就可以用这个模型解决很好。但是规模太大,参数已经是上亿级别,特征维度太高,这个模型虽然表达能力非常强,可以把落后裸 id 特征学习很好,但是从模型存储、离线的训练,包括在线网络的预估过程不能响应时间的要求,所以我们很大量的工作在这个领域做模型的压缩和编码的压缩。对于输入层稀疏 ID 的表达做各种压缩,包括域的选择为什么要拆开若干个域,对于离线和在线的评估也好、训练也好可以做一些效率上的提升。包括在离线版本和在线预估的版本,这两个也是有特征模型压缩的区分。包括在优酷搜索里的召回阶段,包括索引阶段,都会把深度表征学习大规模的模型建到索引里。
李玉博士,花名谈志,优酷数据智能部总监,负责优酷的个性化推荐、搜索、泛内容 AI 平台、视频 AI 理解等。加入阿里前曾在美国 Uber 负责个性化智能定价、补贴、拼车规划等工作;在京东任京东数据云总监;在美国雅虎负责雅虎的 DSP 广告平台、广告 Targeting 等工作。



