开源 | 基于会话的最优推荐模型:SR-GNN的PaddlePaddle实现
本文转载自百度 PaddlePaddle
百度深度学习平台PaddlePaddle于近期开源了基于会话(session-based)的推荐系统模型(SR-GNN)。
相较于之前通过循环神经网络(RNN)来对会话进行序列化建模导致的不能够得到用户的精确表征以及忽略了items中复杂的转换特性,SR-GNN通过将序列化的问题转换为图的问题,对所有的会话序列通过有向图进行建模,然后通过图神经网络(GNN)来学习每个item的隐向量表示,进而通过一个注意力网络(Attention Network)架构模型来捕捉用户的短期兴趣,以达到捕获长期与短期兴趣共存的向量表示。
SR-GNN模型明显优于一些最先进的基于会话的推荐方法。
项目地址:https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/gnn
应用背景
随着互联网上信息量的快速增长,推荐系统能够帮助用户缓解信息过载的问题,进而有效帮助用户在众多Web应用程序中(比如:搜索、电子商务、媒体流网站等)选择自己感兴趣的信息。大多数现有的推荐系统都假设一个前提:用户画像(user profile)和历史活动信息是被不断记录的。
然而实际上,在许多服务中,用户的信息可能是未知的,并且只有处于当前正在进行的会话中的用户历史行为可用。
因此,在一个会话中,能对有限的行为进行建模并相应地生成推荐是非常重要的。但是在这种场景下,需要依靠丰富的user-item交互信息的传统推荐系统无法产生令人满意的推荐结果。
当前基于会话的推荐系统简介
由于推荐系统的高实际价值,越来越多的研究人员开始提出基于会话的推荐方案。
基于马尔可夫链的推荐系统:该模型基于用户上一次的行为来预测用户的下一次行为,然而由于强独立性相关假设,该模型的预测结果并不十分准确。
基于循环神经网络(RNN)的推荐系统:相比于传统的推荐问题,基于会话的推荐问题的不同点在于如何利用用户的短期会话交互信息数据来预测用户可能会感兴趣的内容。
基于会话的推荐可以建模为序列化问题,也就是基于用户的短期历史活动记录来预测下一时刻可能会感兴趣的内容并点击阅览。而深度学习中的RNN模型正是一类用于处理序列数据的神经网络。随着序列的不断推进,RNN模型中靠前的隐藏层将会影响后面的隐藏层。于是将用户的历史记录交互数据作为输入,经过多层神经网络,达到预测用户兴趣的目的。该模型也达到了令人满意的预测结果。
然而,该模型也有两处不足。
第一点就是在基于会话的推荐系统中,会话通常是匿名的且数量众多的,并且会话点击中涉及的用户行为通常是有限的,因此难以从每个会话准确的估计每个用户表示(user representation),进而生成有效推荐内容。
第二点是利用RNN来进行的建模,不能够得到用户的精确表示以及忽略了item中复杂的转换特性。
SR-GNN概述
为了克服第二部分描述的基于其他模型的推荐系统不足之处,文章作者提出了基于会话的图神经网络模型的推荐系统(SR-GNN)。该模型可以更好的挖掘item中丰富的转换特性以及生成准确的潜在的用户向量表示。SR-GNN模型的工作流如下:
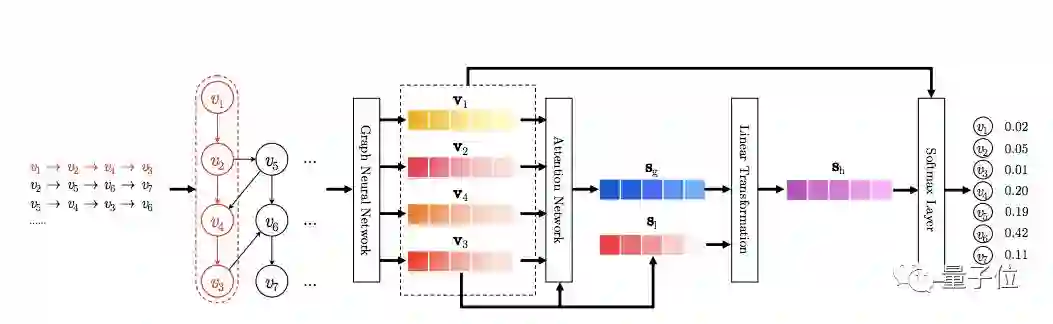
△ 图1:SR-GNN模型的工作流
首先,对所有的session序列通过有向图进行建模。 接着通过GNN,学习每一个node(item)的隐向量表示。然后通过一个attention架构模型得到每个session的embedding。最后通过一个softmax层进行全表预测。
1.构建会话图(constructing session graphs)
每一个会话序列都被建模为有向图。在此会话图中每一个节点(node)代表一个item。有向图的每一条边意味着一个用户在该会话中依次点击了起点和终点表示的item。每一个item被嵌入到统一的embedding空间,并且我们用节点向量来指明每一个item隐向量。基于节点向量,每一个会话被建模成一个嵌入向量。
2.学习每个item隐向量表示(Learning Item Embeddings on Session Graphs)
利用GNN来学习每一个item的隐向量表示。图神经网络之所以适合基于会话的推荐是因为它能利用丰富的节点间关系来自动抽取出会话图的特征。
3.生成每个会话的embedding(generating session embeddings)
以前的基于会话的推荐方法总是假设在每一个对话中,都存在明显的用户潜在表征。相反的,SR-GNN方法不对用户做出任何假设,而是将会话直接由组成它的若干节点进行表示。每一个session利用注意力机制将整体偏好与当前偏好结合进行表示。
4.生成推荐(make recommendation)
当获得每一个会话的embedding后,我们可以计算出所有候选item的推荐分数值。接着我们利用softmax函数和已经获得的推荐分数值来计算不同候选item的概率值,来表明在该次会话中用户下一次可能点击的不同item的概率。
PaddlePaddle实战
SR-GNN代码库简要目录结构及说明:
.
├── README.md # 文档
├── train.py # 训练脚本
├── infer.py # 预测脚本
├── network.py # 网络结构
├── reader.py # 和读取数据相关的函数
├── data/
├── download.sh # 下载数据的脚本
├── preprocess.py # 数据预处理
数据准备:使用DIGINETICA数据集。可以按照下述过程操作获得数据集以及进行简单的数据预处理。
• Step 1: 运行如下命令,下载DIGINETICA数据集并进行预处理
cd data && sh download.sh
• Step 2: 产生训练集、测试集和config文件
python preprocess.py --dataset diginetica
cd ..
运行之后在data文件夹下会产生diginetica文件夹,里面包含config.txt、test.txt以及 train.txt三个文件。
生成的数据格式为:session_list, label_list。其中session_list是一个session的列表,里面的每个元素都是一个list,代表不同的session。label_list是一个列表,每个位置的元素是session_list中对应session的label。
训练:可以参考下面不同场景下的运行命令进行训练,还可以指定诸如batch_size,lr(learning rate)等参数,具体的配置说明可通过运行下列代码查看
python train.py -h
gpu 单机单卡训练
CUDA_VISIBLE_DEVICES=1 python -u train.py —use_cuda 1 > log.txt 2>&1 &
cpu 单机训练
CPU_NUM=1 python -u train.py --use_cuda 0 > log.txt 2>&1 &
值得注意的是上述单卡训练可以通过加—use_parallel 1参数使用Parallel Executor来进行加速。
以下为训练结果示例:我们在Tesla K40m单GPU卡上训练的日志如下所示(以实际输出为准)
W0308 16:08:24.249840 1785 device_context.cc:263] Please NOTE: device: 0, CUDA Capability: 35, Driver API Version: 9.0, Runtime API Version: 8.0
W0308 16:08:24.249974 1785 device_context.cc:271] device: 0, cuDNN Version: 7.0.
2019-03-08 16:08:38,079 - INFO - load data complete
2019-03-08 16:08:38,080 - INFO - begin train
2019-03-08 16:09:07,605 - INFO - step: 500, loss: 10.2052, train_acc: 0.0088
2019-03-08 16:09:36,940 - INFO - step: 1000, loss: 9.7192, train_acc: 0.0320
2019-03-08 16:10:08,617 - INFO - step: 1500, loss: 8.9290, train_acc: 0.1350
...
2019-03-08 16:16:01,151 - INFO - model saved in ./saved_model/epoch_0
...
预测:运行如下命令即可开始预测。可以通过参数指定开始和结束的epoch轮次。
CUDA_VISIBLE_DEVICES=3 python infer.py
以下为预测结果示例:
W0308 16:41:56.847339 31709 device_context.cc:263] Please NOTE: device: 0, CUDA Capability: 35, Driver API Version: 9.0, Runtime API Version: 8.0
W0308 16:41:56.847705 31709 device_context.cc:271] device: 0, cuDNN Version: 7.0.
2019-03-08 16:42:20,420 - INFO - TEST --> loss: 5.8865, Recall@20: 0.4525
2019-03-08 16:42:45,153 - INFO - TEST --> loss: 5.5314, Recall@20: 0.5010
2019-03-08 16:43:10,233 - INFO - TEST --> loss: 5.5128, Recall@20: 0.5047
...
PaddleRec智能推荐
这里给大家安利一下PaddleRec智能推荐。推荐系统在当前的互联网服务中正在发挥越来越大的作用,目前大部分电子商务系统、社交网络,广告推荐,搜索引擎,都不同程度的使用了各种形式的个性化推荐技术,帮助用户快速找到他们想要的信息。此外,在工业可用的推荐系统中,推荐策略一般会被划分为多个模块串联执行。
PaddlePaddle对推荐算法的训练提供了完整的支持,并提供了多种模型配置供用户选择。包括TagSpace,GRU4Rec,Word2Vec,GraphNeuralNetwork,DeepInterestNetwork等等,之后还会继续添加其他模型也包括更多的图模型,欢迎大家尝试使用。
附上链接:https://github.com/PaddlePaddle/models/tree/develop/PaddleRec
论文传送门:
Session-based Recommendation with Graph Neural Networks,Shu Wu, Yuyuan Tang,Yanqiao Zhu, Liang Wang,Xing Xie,Tieniu Tan
https://arxiv.org/abs/1811.00855
— 完 —
小程序|get更多AI学习干货

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



