让知识来指引你:序列推荐场景中以知识为导向的强化学习模型

时序推荐是基于用户的顺序行为,对未来的行为进行预测的任务。目前的工作利用深度学习技术的优势,取得了很好的效果。但是这些工作仅专注于所推荐商品的局部收益,并未考虑该商品对于序列长期的影响。
强化学习(RL)通过最大化长期回报为这一问题提供了一个可能的解决方案。但是,在时推荐场景中,用户与商品交互的稀疏性,动态性增加了强化学习的随机探索的难度,使得模型不能很好地收敛。
近年来,知识图谱被广泛地用于推荐系统,但是这些工作往往忽略了知识对于探索过程的指导,从而使得RL模型不能很好地解决时序推荐任务中用户偏好的漂移。
针对以上问题,北京邮电大学的王鹏飞老师课题组同中国人民大学的赵鑫课题组首次探讨了将强化学习技术应用在时序推荐任务上的可能性。提出了一种知识引导的强化学习模型,将知识图信息融合到 RL 框架进行序列推荐。他们的研究成果 KERL: A Knowledge-Guided Reinforcement Learning Model for Sequential Recommendation 发表在 2020 年的 SIGIR 会议上。

论文标题:KERL: A Knowledge-Guided Reinforcement Learning Model for Sequential Recommendation
论文来源:SIGIR 2020
论文链接:https://arxiv.org/abs/2004.08068

框架模型
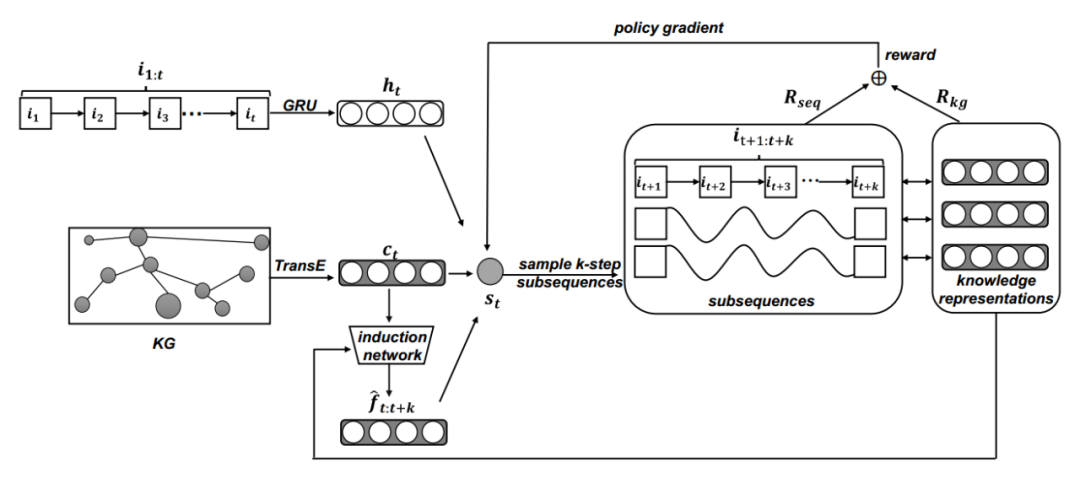
融合知识的状态表示方法
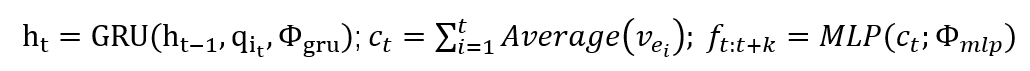
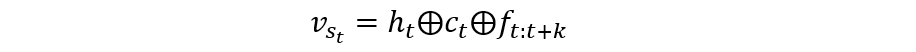
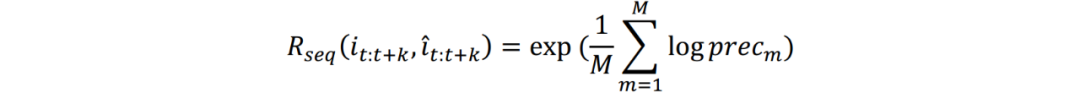
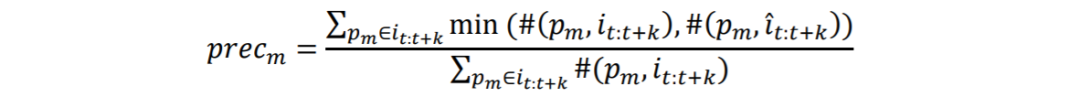
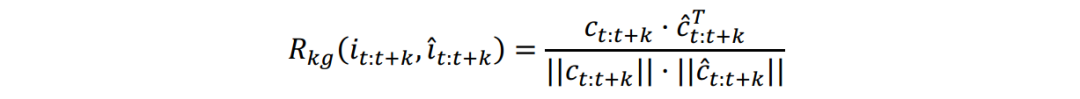
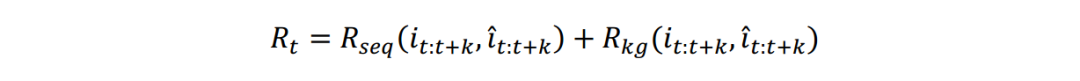
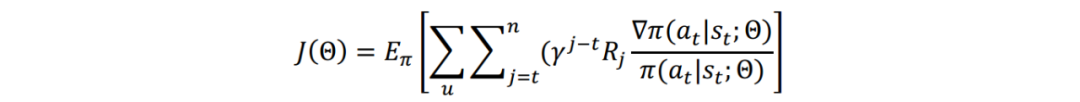
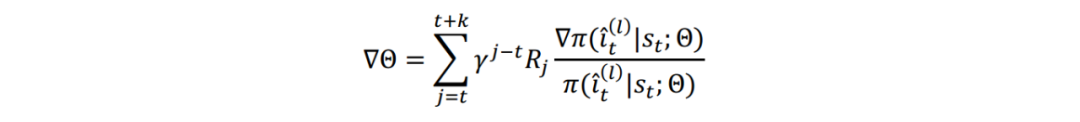
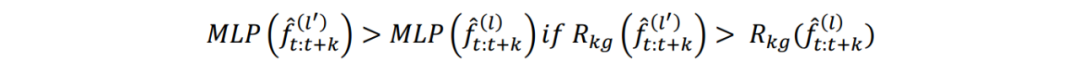

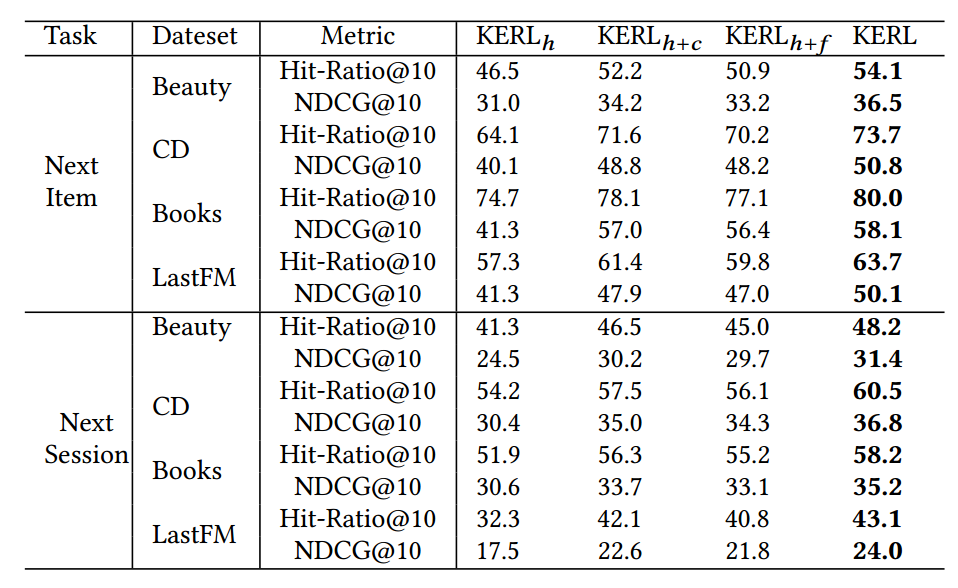
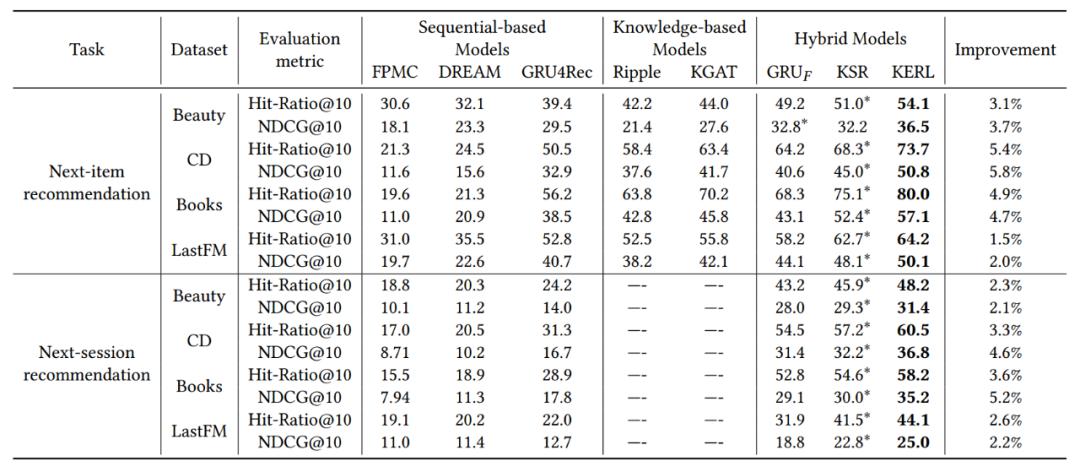
模型试验效果
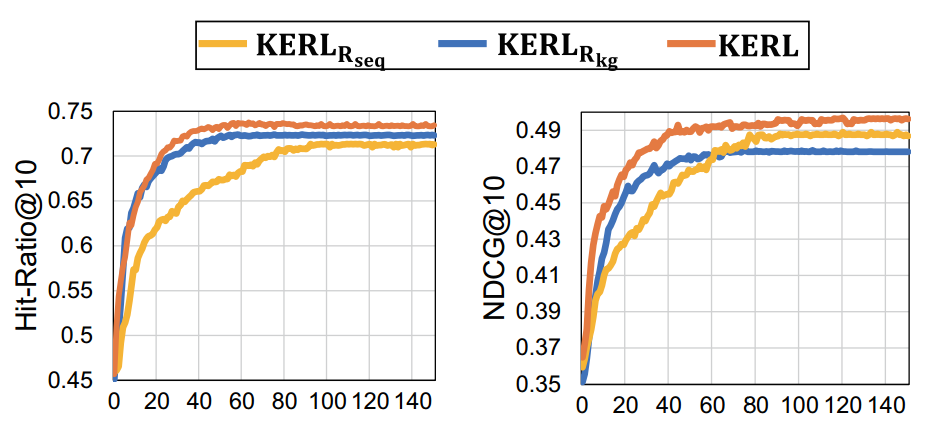

论文总结
关于作者
王鹏飞,北京邮电大学计算机学院硕士生导师
2017年获得中科院计算技术研究所博士学位,现入北京邮电大学,任计算机学院的助理教授,硕士生导师。主要专注于研究用户行为的时序建模,文本分类等任务。近五年内在国内外著名学术期刊与会议上发表论文20余篇,在国际顶级会议(SIGIR、WSDM、CIKM等)以第一作者发表论文10余篇,并在并担任多个国际会议(如SIGIR,AAAI等)评审人。
范钰, 北京邮电大学计算机学院硕士研究生
目前研究生在读,研究方向为推荐系统中用户行为的时序建模,图神经网络。已在SIGIR会议发表论文两篇。
夏龙,约克大学博士后研究员
2017年于中国科学院计算技术研究所获博士学位后,加入京东数据科学实验室担任资深研究员。研究兴趣包括数据挖掘,应用机器学习,信息检索和人工智能。在国际顶级会议期刊如KDD,SIGIR,TIST发表论文十余篇,并担任KDD,WWW,AAAI,WSDM等国际学术会议程序委员会委员。
赵鑫,中国人民大学信息学院副教授、博士生导师
博士师从北京大学李晓明教授,专注于研究面向文本内容的社交用户话题兴趣建模。近五年内在国内外著名学术期刊与会议上发表论文80余篇,其中包括ACM TOIS和SIGIR、IEEE TKDE和SIGKDD、ACL等。所发表的学术论文共计被引用3500余次。担任多个重要的国际会议或者期刊评审,入选第二届CCF青年人才发展计划。曾获得CIKM 2017最佳短文候选以及AIRS 2017最佳论文奖。
牛少彰,北京邮电大学计算机学院教授
2004年于北京邮电大学获得博士学位。作为主要研究人员参加了973项目、国家自然科学基金等项目,同时兼任中国电子学会高级会员,中国电子学会多媒体信息安全专家委员会委员等职务。现主要从事网络信息安全、网络攻防技术、信息内容安全、信息隐藏技术、数字权益管理技术、软件安全以及计算机取证技术方面的教学和科研工作。
Jimmy Huang,约克大学信息技术学院教授、博士生导师
博士毕业于伦敦大学。ACM杰出科学家,加拿大约克大学约克研究主席,英国计算机学会会员和皇家艺术学会会员。主要研究重点是信息检索,大数据及其在Web和医疗保健中的应用领域。在国际著名学术期刊与会议所发表的学术论文共计被引用20000余次。曾获得第32届欧洲信息检索会议最佳论文奖,作为研究创新部早期研究员获得首席卓越研究奖(2007-2012年)。2015年获LA&PS杰出研究,学术创造力奖。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





