SIGIR2020 | 一种新颖的推荐系统重训练技巧
背景
挑战
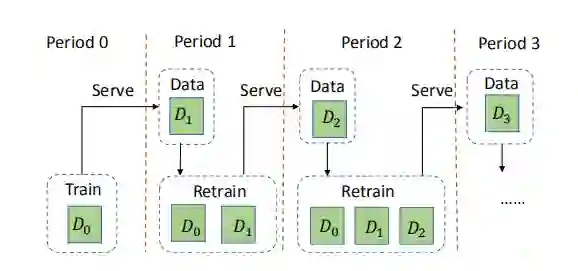
传统的重训练方式需要每隔一段时间重新训练整个用户数据,比如Period0用D0训练好模型之后上线,经过Period1服务用户一段时间后产生用户数据D1,因此为了捕捉用户当前的兴趣偏好,需要一起重新训练之前庞大的历史用户数据D0和新增加的用户数据D1。
-
挑战:历史数据量随着时间的推移会越来越大,那么每一次重新训练数据量就越来越大,训练时间也会越来越长,消耗也就越来越大。 解决方案:针对历史数据,模型无需再进行模型训练。也就是说,我们只需要训练一次用户的历史数据即可。在未来的若干次重训练中,我们仅需要训练增量数据(用户新产生的数据)即可。这不仅避免了历史数据的重复计算,而且减少了训练能耗。 -
挑战:重训练只依据用户产生的新数据来更新模型,少量的新数据能够精确、全面、稳定地表达用户偏好信息呢? 解决方案:基于增量数据规模小的特点,模型采用了迁移的思路,将学习历史训练数据的经验,迁移到新的增量数据的学习上。这就避免了重训练仅包含增量数据的问题。
模型
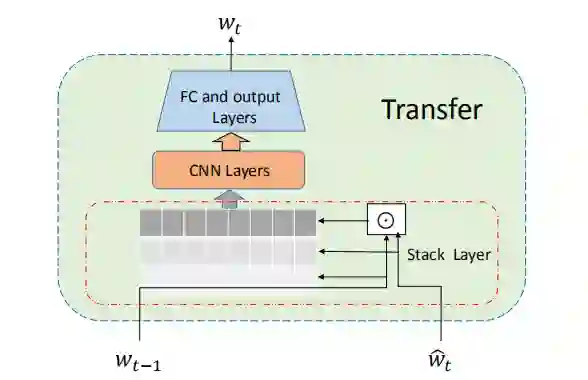
整个模型可以简化为两个部分:
(1)表达转移组件。构建一个表达传递组件,将先前训练中获得的知识转移到新交互的训练中。我们将传递组件设计为卷积神经网络(CNN),该卷积神经网络将先前的模型参数输入为常量,将当前模型的输入作为可训练参数。合理性在于,先前训练中获得的知识会集中在模型参数中,这样,表达性神经网络就应该能够将知识提炼到所需的目的。

Paper: How to Retrain Recommender System? A Sequential Meta-Learning Method
推荐阅读

登录查看更多
相关内容

Arxiv
8+阅读 · 2018年3月5日
Arxiv
15+阅读 · 2018年1月5日




相关VIP内容
相关资讯