华为、人大、清华和港中文联合发布推荐系统的Benchmarking
| 作者:YEN
| 研究方向:推荐系统、计算广告

推荐系统的Benchmarking:BARS(BenchmArking for Recommender Systems)
-
论文标题:Towards Open Benchmarking for Recommender Systems(论文投稿到(NeurIPS 2021 Track on Datasets and Benchmarks)) -
论文地址: https://openreview.net/forum?id=9jkFflx6Q6U -
项目地址: https://openbenchmark.github.io/BARS/
尽管推荐系统近年来发展迅速,但一个普遍的关键问题是,仍然缺乏一个标准的基准,以鼓励严格的评估和量化在这个研究领域取得的真正进展。在本文中,作者提出了一个开放的推荐基准,它涵盖了现代推荐系统中两个最重要的阶段,即匹配和排序。特别是,它包含了各种数据集上的大量推荐模型之间的全面比较结果,以及每个结果对应的详细的可重复脚本。还提供了一个用户友好的基准测试工具包,以方便模型实现。作者的基准测试结果表明,该领域的评估不够严格(例如,忽略重要的基线),迫切需要建立统一的基准测试。因此,本研究旨在为推荐系统的健康发展提供肥沃的土壤,以激发更坚实和可重复的研究。
本文目录
项目简介
推荐系统排序阶段Benchmarking
数据集
实验结果
推荐系统匹配阶段Benchmarking
数据集
实验结果
模型复现步骤
官网也说明了希望各位开发者积极参与到该项目的贡献!!
项目简介
科学的开放性是促进进步的关键。BARS是一个旨在为推荐系统开放 Benchmarking 的项目,允许更好的定量研究的可重复性和可重复性。BARS的最终目标是在推荐系统的开发中推动更多可重复的研究。BARS具有以下主要功能:
-
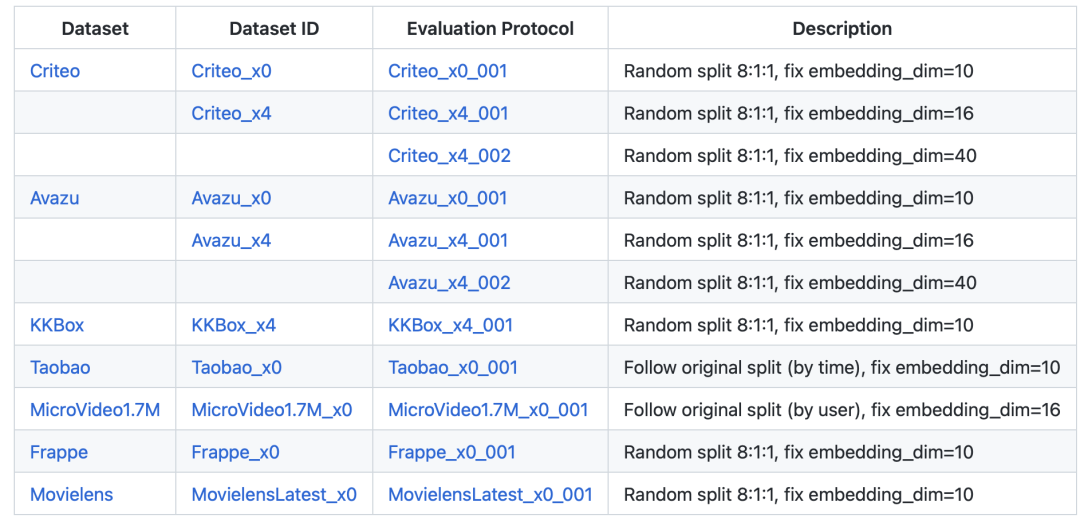
开放数据集:BARS 收集了一组广泛使用的公共数据集用于推荐研究,并分配唯一的数据集ID来跟踪每个数据集的特定数据分割。这允许以统一的方式共享和试验数据集。 -
开源代码:BARS 支持开源原则,并为推荐研究提供开源模型实现列表。 -
基准测试pipeline:BARS 构建了一个开放的基准测试pipeline,以确保每个步骤产生的所有工件的透明度和可用性。 -
综合结果:BARS提供了迄今为止最全面的基准测试结果,涵盖了数十个 SOTA模型和数十个数据集分割。这些结果可以很容易地重复用于未来的研究。 -
重现步骤:BARS 的核心是通过详细记录重现步骤,遵循开放的基准测试管道,确保每个基准测试结果的可重现性。 -
任何人均可编辑:BARS 对社区开放。任何人都可以通过 Github 上的拉取请求贡献新的数据集、新模型或新的基准测试结果。
通过设置开放的基准测试标准,以及免费提供的数据集、源代码和复制步骤,作者希望 BARS 项目可以使社区中的所有研究人员、从业人员和教育工作者受益。
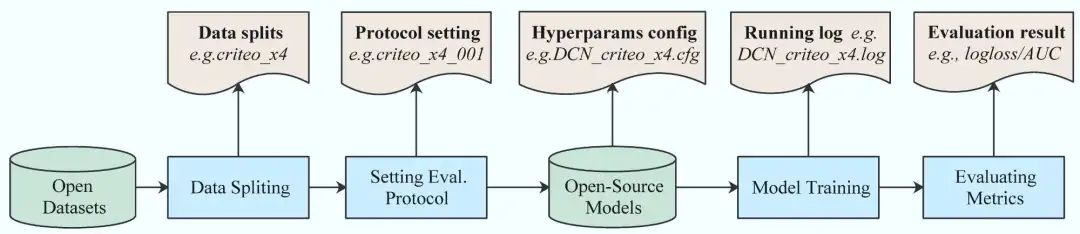
推荐系统排序阶段Benchmarking

数据集
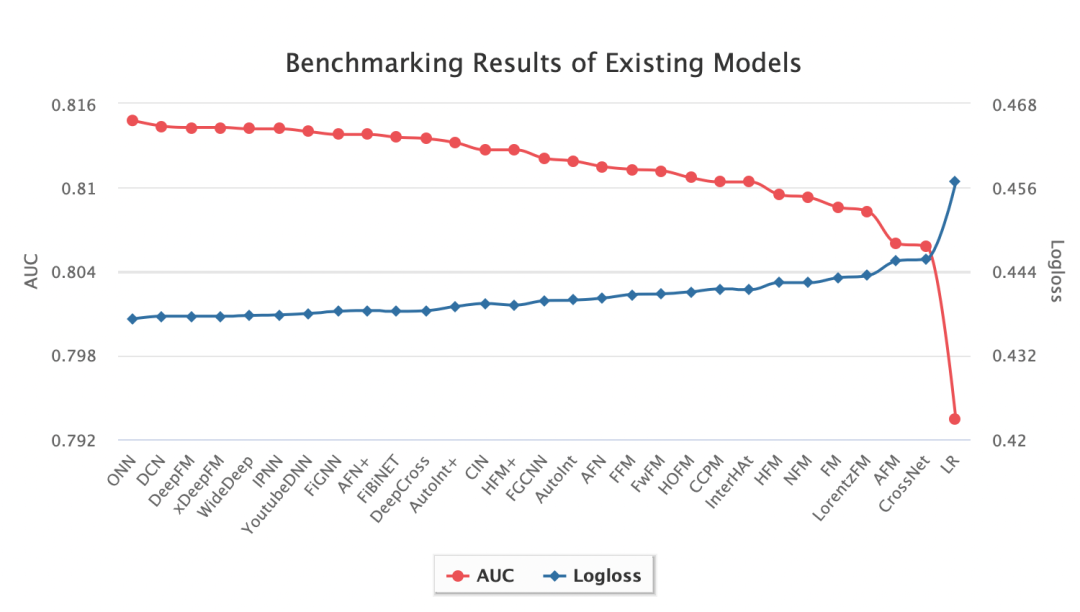
实验结果
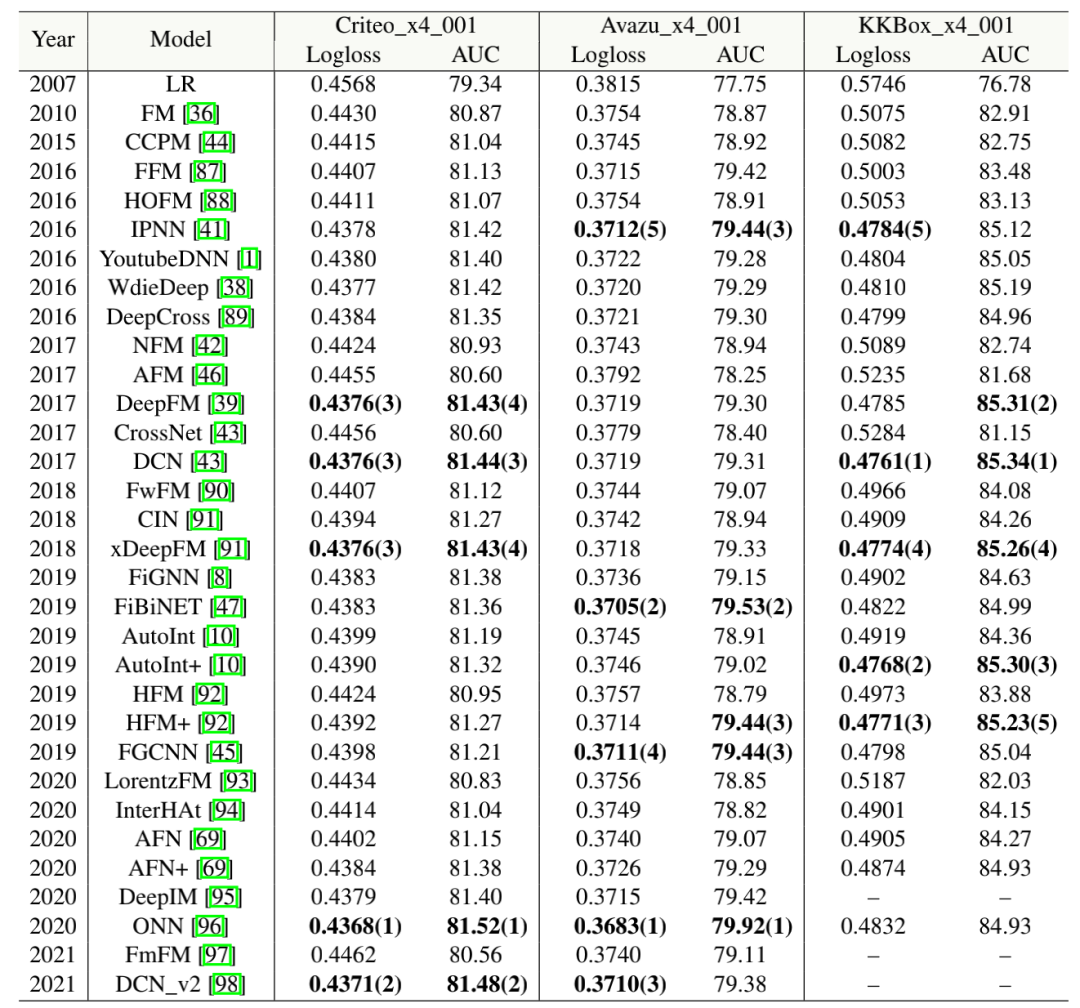
更多实验结果参考官网的实验部分:https://openbenchmark.github.io/ctr-prediction/leaderboard/criteo_x4_001.html
例如:
推荐系统匹配阶段Benchmarking

数据集
实验结果
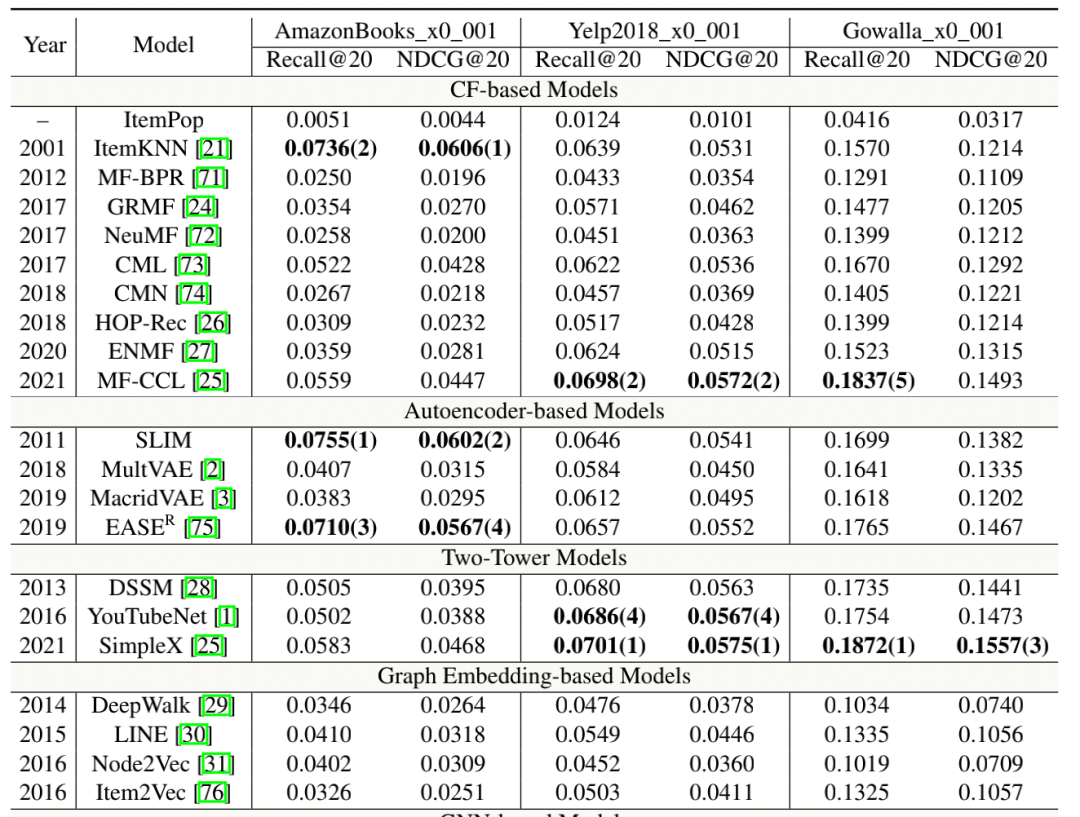
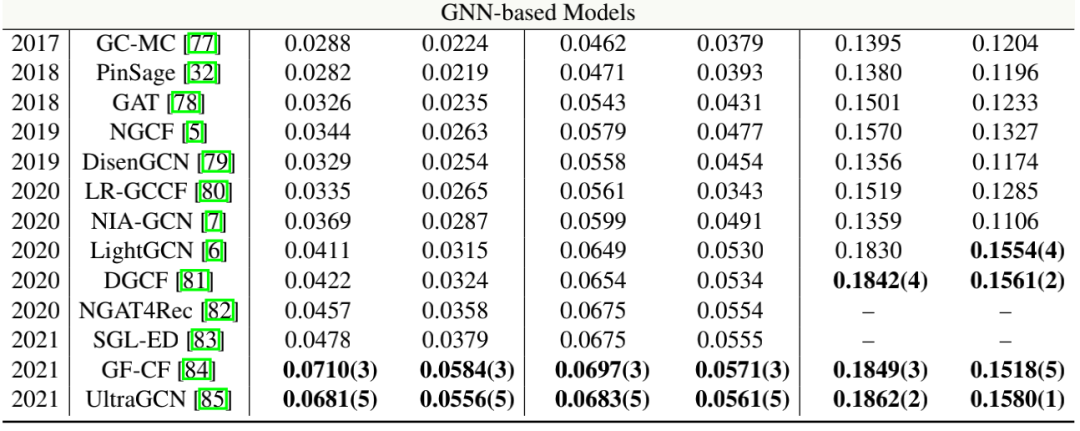
更多实验结果参考官网实验部分:https://openbenchmark.github.io/candidate-matching/leaderboard/amazonbooks_x0_001.html
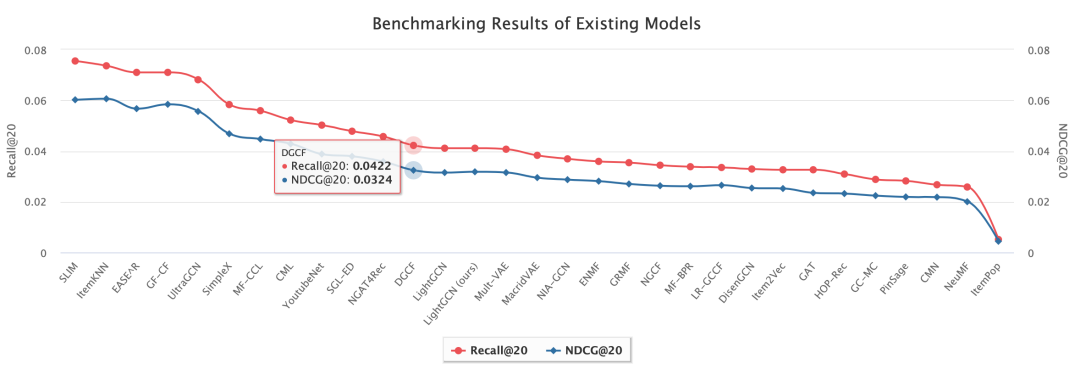
模型复现步骤
官网给了详细的复现参数配置以及训练日志,例如:
2020-08-09 23:28:47,581 P587 INFO {
"batch_norm": "False",
"batch_size": "10000",
"data_format": "h5",
"data_root": "../data/Criteo/",
"dataset_id": "criteo_x4_5c863b0f",
...
2020-08-09 23:28:47,583 P587 INFO Set up feature encoder...
2020-08-09 23:28:47,583 P587 INFO Load feature_map from json: ../data/Criteo/criteo_x4_5c863b0f/feature_map.json
2020-08-09 23:28:47,583 P587 INFO Loading data...
2020-08-09 23:28:47,588 P587 INFO Loading data from h5: ../data/Criteo/criteo_x4_5c863b0f/train.h5
2020-08-09 23:28:52,372 P587 INFO Loading data from h5: ../data/Criteo/criteo_x4_5c863b0f/valid.h5
2020-08-09 23:28:54,189 P587 INFO Train samples: total/36672493, pos/9396350, neg/27276143, ratio/25.62%
2020-08-09 23:28:54,315 P587 INFO Validation samples: total/4584062, pos/1174544, neg/3409518, ratio/25.62%
2020-08-09 23:28:54,315 P587 INFO Loading train data done.
2020-08-09 23:29:13,705 P587 INFO Start training: 3668 batches/epoch
2020-08-09 23:29:13,705 P587 INFO ************ Epoch=1 start ************
2020-08-10 02:08:56,236 P587 INFO [Metrics] logloss: 0.445034 - AUC: 0.806660
2020-08-10 02:08:56,238 P587 INFO Save best model: monitor(max): 0.361626
2020-08-10 02:08:57,906 P587 INFO --- 3668/3668 batches finished ---
2020-08-10 02:08:57,976 P587 INFO Train loss: 0.462868
2020-08-10 02:08:57,976 P587 INFO ************ Epoch=1 end ************
2020-08-10 04:48:54,593 P587 INFO [Metrics] logloss: 0.442922 - AUC: 0.808947
2020-08-10 04:48:54,594 P587 INFO Save best model: monitor(max): 0.366025
2020-08-10 04:48:56,825 P587 INFO --- 3668/3668 batches finished ---
2020-08-10 04:48:56,898 P587 INFO Train loss: 0.457419
...
官网也说明了希望大家积极参与到该项目的贡献!!




