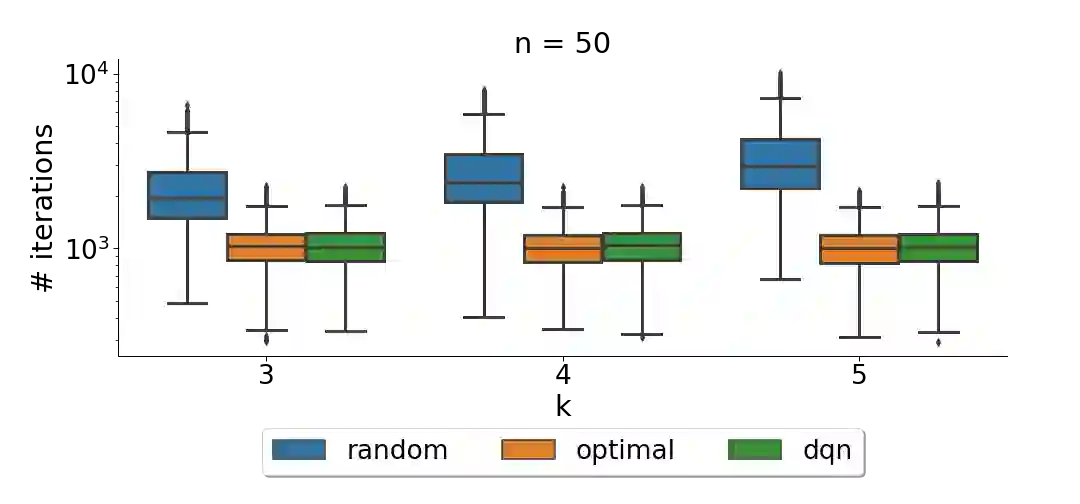
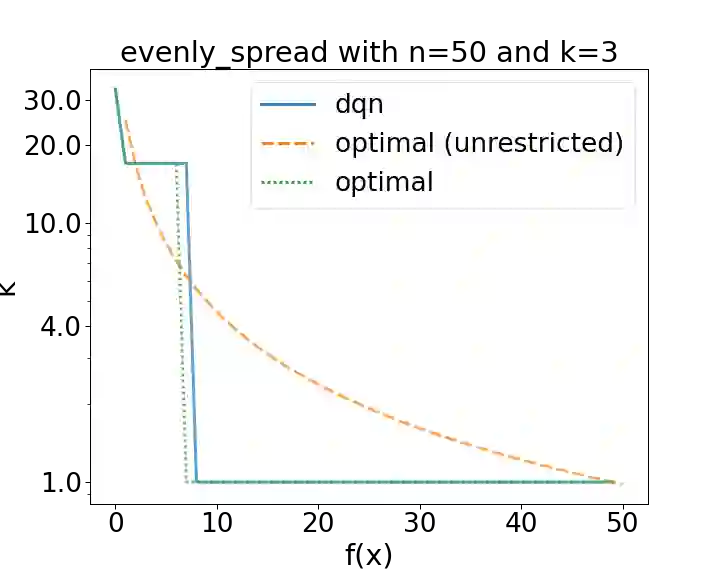
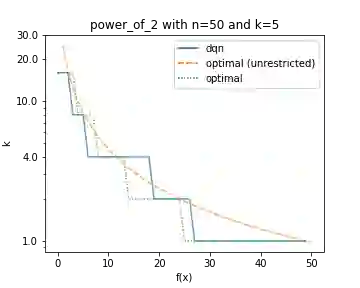
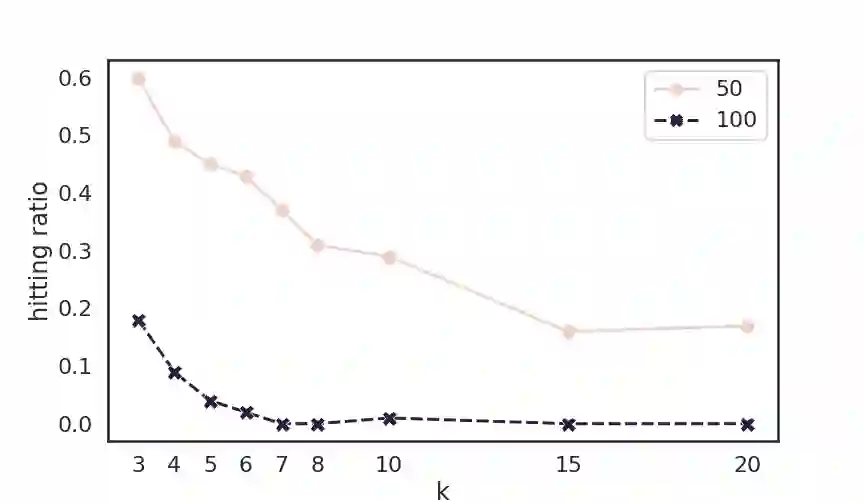
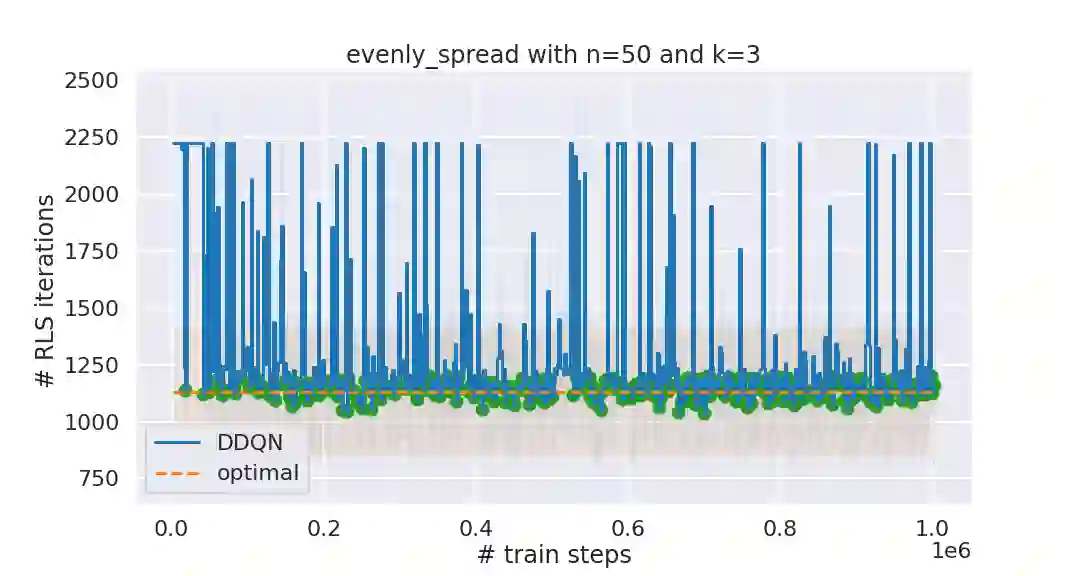
It has long been observed that the performance of evolutionary algorithms and other randomized search heuristics can benefit from a non-static choice of the parameters that steer their optimization behavior. Mechanisms that identify suitable configurations on the fly ("parameter control") or via a dedicated training process ("dynamic algorithm configuration") are therefore an important component of modern evolutionary computation frameworks. Several approaches to address the dynamic parameter setting problem exist, but we barely understand which ones to prefer for which applications. As in classical benchmarking, problem collections with a known ground truth can offer very meaningful insights in this context. Unfortunately, settings with well-understood control policies are very rare. One of the few exceptions for which we know which parameter settings minimize the expected runtime is the LeadingOnes problem. We extend this benchmark by analyzing optimal control policies that can select the parameters only from a given portfolio of possible values. This also allows us to compute optimal parameter portfolios of a given size. We demonstrate the usefulness of our benchmarks by analyzing the behavior of the DDQN reinforcement learning approach for dynamic algorithm configuration.
翻译:长期以来人们一直认为,演进算法和其他随机搜索理论的性能可以从非静态地选择指导其优化行为的参数中受益。因此,确定飞行(“参数控制”)或通过专门培训过程(“动力算法配置”)的适当配置的机制是现代进化计算框架的一个重要组成部分。解决动态参数设置问题的若干方法存在,但我们几乎无法理解哪些应用更适合。在古典基准中,具有已知地面真理的问题收集可以在这方面提供非常有意义的洞察力。不幸的是,有深奥的控制政策的环境非常罕见。我们知道哪些参数设置尽量减少预期运行时间的少数例外之一是“领导一”问题。我们通过分析最佳控制政策来扩展这一基准,该控制政策只能从特定组合的可能值中选择参数。这也使我们能够计算出某个特定大小的最佳参数组合。我们通过分析动态算法的DDQN强化学习方法的行为来证明我们基准的有用性。