网易伏羲推出一种基于强化学习的推荐系统全新Benchmark

简介
基于强化学习的推荐系统(RL-basedressmender system,RS)旨在通过将序贯推荐应用到多步决策任务中,从而从一批收集的数据中获得好的策略。然而,当前基于RL的RS benchmark通常存在较大的现实差距,因为它们大多只包括人工RL数据集或半模拟RS数据集,并且训练的策略只在模拟环境中评估。在现实世界中,并非所有推荐问题都适合转化为强化学习问题。与以往的学术RL研究不同,基于RL的RS存在外推误差,并且在部署前很难得到充分验证。在本文中,我们介绍了RL4RS(Recommender Systems的强化学习)基准测试——一种完全从工业应用系统中收集的新资源,用于训练和评估RL算法。它包含了两个真实数据集、优化的模拟环境、相关的高级RL基线、数据理解工具和反事实的策略评估算法。除了基于RL的推荐系统之外,我们希望这些资源能为强化学习和神经组合优化的研究做出贡献。
github项目:https://github.com/fuxiAIlab/RL4RS
数据集下载: https://drive.google.com/file/d/1YbPtPyYrMvMGOuqD4oHvK0epDtEhEb9v/view?usp=sharing
文章pdf: https://arxiv.org/pdf/2110.11073.pdf
Kaggle竞赛地址: https://www.kaggle.com/c/bigdata2021-rl-recsys/overview
相关资源: https://fuxi-up-research.gitbook.io/fuxi-up-challenges/
特性介绍
和现有的开源的基于强化学习的推荐系统Benchmark对比:
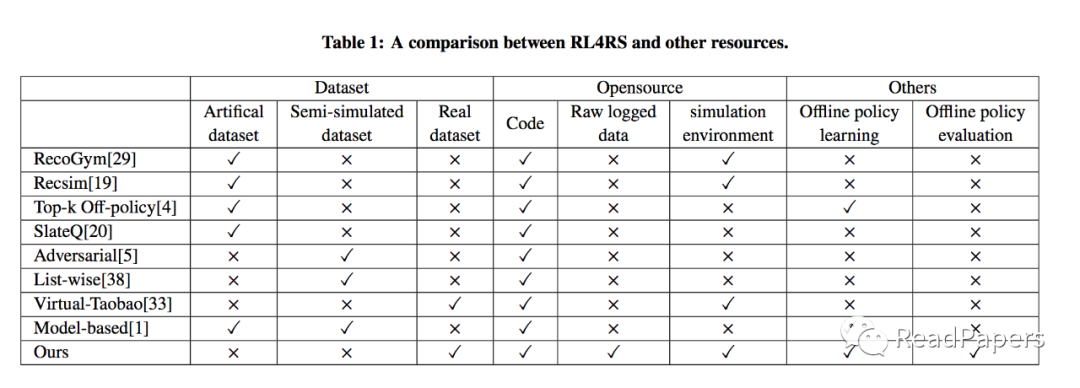
真实世界的数据集
-
两个真实世界的数据集:除了人工数据集或半模拟数据集外,RL4RS 还从 网易游戏发布的最受欢迎的游戏之一收集原始记录数据,本质是一种序贯决策问题。 -
数据理解工具:RL4RS 提供了一个数据理解工具,用于评估RL 在推荐系统数据集上的正确使用方式。 -
进阶数据集设置:RL4RS 为每个数据集提供强化学习部署之前和之后的分离数据,可以在SL-based 算法收集的数据集中,模拟训练RL策略。
实用的强化学习基线
-
model-free RL: RL4RS 支持最先进的 RL 库,例如 RLlib 和 Tianshou,提供了由 RLlib 库在离散和连续(将策略梯度与 K-NN 搜索相结合)RL4RS 环境中实现的最先进的model-free算法(A2C、PPO 等)的示例代码。 -
offline RL: RL4RS 通过 d3rlpy 库实现包括 BC、BCQ 和 CQL 在内的离线 RL 算法。RL4RS 也是第一个报告离线 RL 算法(BCQ 和 CQL)在基于 RL 的 RS 领域的有效性。 -
RL-based RS baselines: RL4RS 实现了一些在基于 RL 的推荐领域提出的算法,包括 Exact-k 和 Adversarial User Model。 -
offline RL evaluation: 除了奖励指标和传统的 RL 评估设置(在同一环境下训练和测试),RL4RS 通过更加重视反事实策略评估来提供一种完整的评估框架。
实现的方法列表如下:
| algorithm | discrete control | continuous control | offline RL? |
|---|---|---|---|
| Behavior Cloning (supervised learning) | ✅ | ✅ | |
| Deep Q-Network (DQN) | ✅ | ⛔ | |
| Double DQN | ✅ | ⛔ | |
| Rainbow | ✅ | ⛔ | |
| PPO | ✅ | ✅ | |
| A2C A3C | ✅ | ✅ | |
| IMPALA | ✅ | ✅ | |
| Deep Deterministic Policy Gradients (DDPG) | ⛔ | ✅ | |
| Twin Delayed Deep Deterministic Policy Gradients (TD3) | ⛔ | ✅ | |
| Soft Actor-Critic (SAC) | ✅ | ✅ | |
| Batch Constrained Q-learning (BCQ) | ✅ | ✅ | ✅ |
| Bootstrapping Error Accumulation Reduction (BEAR) | ⛔ | ✅ | ✅ |
| Advantage-Weighted Regression (AWR) | ✅ | ✅ | ✅ |
| Conservative Q-Learning (CQL) | ✅ | ✅ | ✅ |
| Advantage Weighted Actor-Critic (AWAC) | ⛔ | ✅ | ✅ |
| Critic Reguralized Regression (CRR) | ⛔ | ✅ | ✅ |
| Policy in Latent Action Space (PLAS) | ⛔ | ✅ | ✅ |
| TD3+BC | ⛔ | ✅ | ✅ |
易于使用的可扩展 API
-
low coupling structure: RL4RS 指定了一种固定的数据格式以减少代码耦合。并将数据相关的逻辑统一为数据预处理脚本或用户自定义的状态类。 -
file-based RL environment: RL4RS 实现了一个基于文件的gym环境,它支持随机采样和顺序访问超过内存大小的数据集。很容易将其扩展到分布式文件系统。 -
http-based vector Env: RL4RS 原生支持 Vector Env,即环境一次性处理批数据。我们通过HTTP接口进一步封装了env,使其可以部署在多台服务器上,加速样本的生成。
正在实验中的特性
-
具有可变discounts、灵活推荐触发器和可修改项目内容的 捆绑推荐新数据集正在准备中。 -
将原始特征而不是隐藏层嵌入作为离线 RL 的观察输入。 -
Model-based RL 算法。 -
奖励导向的模拟环境建设。 -
复现基于 RL 的 RS 领域提出的更多算法(RL 模型、安全探索技术等) -
支持Parametric-Action DQN,输入连接的状态-动作对并输出每对的Q值。
登录查看更多
相关内容

强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。
专知会员服务
17+阅读 · 2020年7月14日
Arxiv
0+阅读 · 2022年4月18日



相关VIP内容
专知会员服务
17+阅读 · 2020年7月14日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日