ICLR'21 | GNN联邦学习的新基准
联邦学习尽管最近在视觉和语言领域取得了进展,但还没有合适的平台用于 GNNs 的 FL。基于此本文提出 FedGraphNN,an open FL benchmark system。FedGraphNN 基于图联邦学习,包含了来自不同领域的数据集、被广泛应用的 GNN 模型和 FL 算法,并有安全和高效的系统支持。FedGraphNN 收集预处理了来自 7 个领域的 36 个数据集。
本文揭示了图联邦学习中的重大挑战:在大多数 no-IID 分割的数据集中,联邦 GNN 的表现比传统 GNN 差;在集中训练中获得最佳结果的 GNN 模型在联邦学习中可能无法保持其优势。这意味着需要更多的研究工作对图联邦学习进行探索。FedGraphNN 系统在计算上是高效的,对大规模图数据集是安全的。
1. Motivation
联邦学习(Federated Learning,FL)是一种分布式学习范式,解决了数据孤岛问题。在联邦学习中,训练是多个客户端之间的协作行为,不需要集中客户端的本地数据。FL 还没有被广泛地应用于图数据的机器学习领域。这其中有多种原因:
缺乏对各种图联邦学习目标和任务的统一描述;
缺乏具有标准化的开放数据集和相应 GNN 和 FL 算法实现的 benchmark;
缺乏为不同的 GNN 模型和 FL 算法定制的模块化联合训练系统。
基于此本文提出了一个开放的 GNN 的 FL benchmark system,FedGraphNN,它包含了来自不同领域的各种图数据集,便于训练和评估各种 GNN 模型和 FL 算法。
2. Federated Graph Neural Networks (FedGraphNN)
图联邦学习有两种情况:单个图被分割或多个图被分散在多个边缘服务器上。由于隐私或监管限制,这些服务器上的数据不能集中进行训练。但是分散数据可以进行协作训练。
假设图数据分散在 
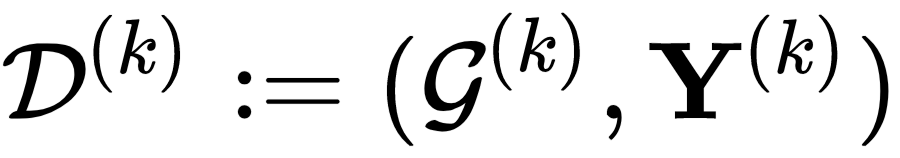
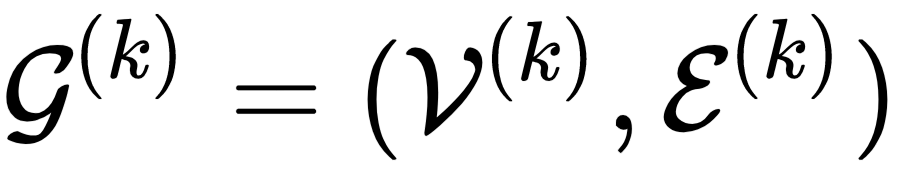
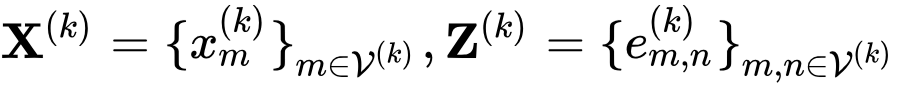
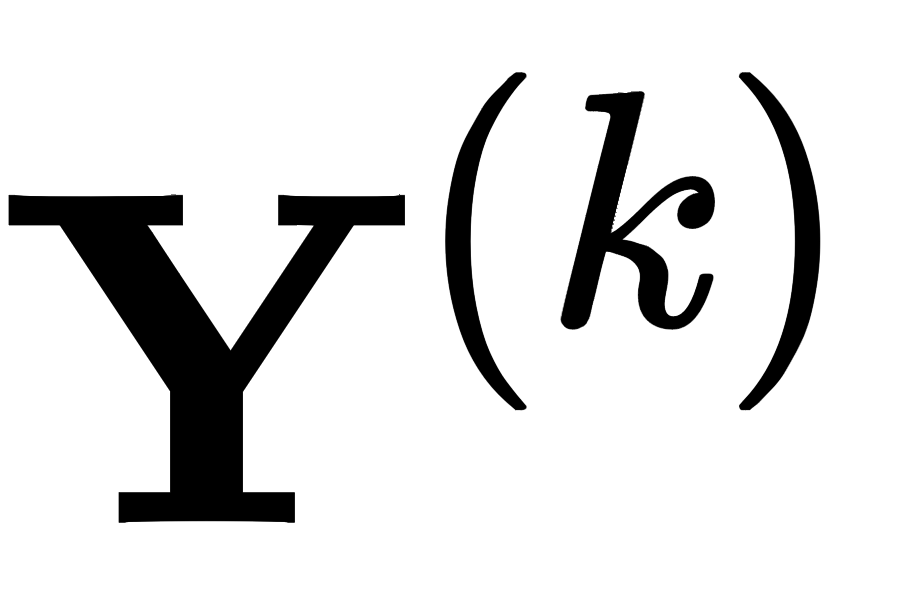
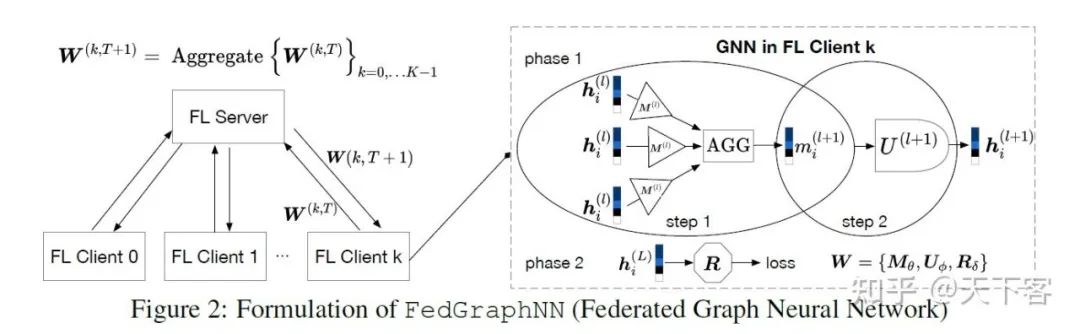
其中 GNN 仍然以消息传递框架(Message Passing Neural Network (MPNN))概括,因此 GNN 的前向传播主要分为两个步骤:message-passing phase 和 readout phase:
GNN phase 1: Message-passing (same for all tasks)
模型收集并转换邻居的信息(Gathers and transforms the neighbors’messages)
模型使用聚合的消息来更新节点的隐藏状态(Uses aggregated messages to update the nodes’hidden states)
三个重要的部分:
代表信息聚合函数,对于 GCN 模型来说就是简单的 SUM 算子;
代表特征传播机制,当前节点和邻居节点的特征传播(扩展加入边的特征);
隐层状态更新函数,代表性的机制是 MLP 进行模型训练。
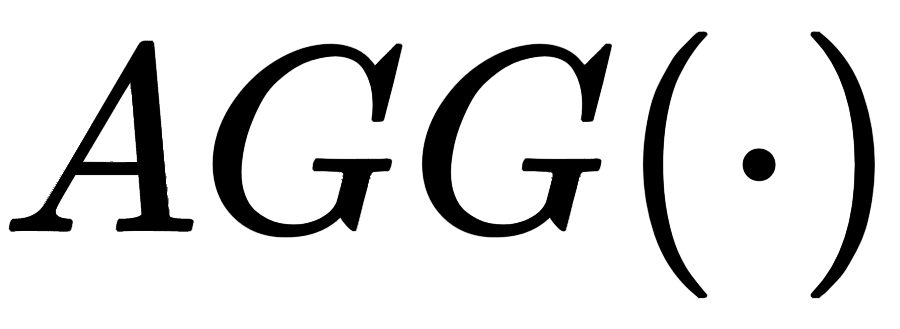 代表信息聚合函数,对于 GCN 模型来说就是简单的 SUM 算子;
代表信息聚合函数,对于 GCN 模型来说就是简单的 SUM 算子;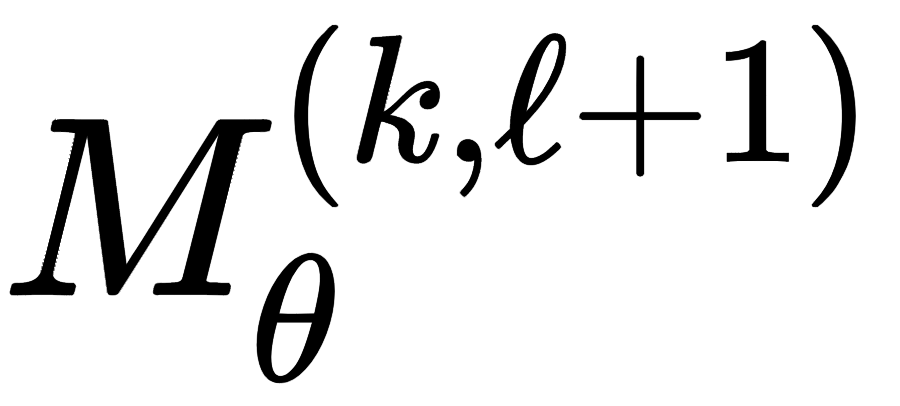 代表特征传播机制,当前节点和邻居节点的特征传播(扩展加入边的特征);
代表特征传播机制,当前节点和邻居节点的特征传播(扩展加入边的特征);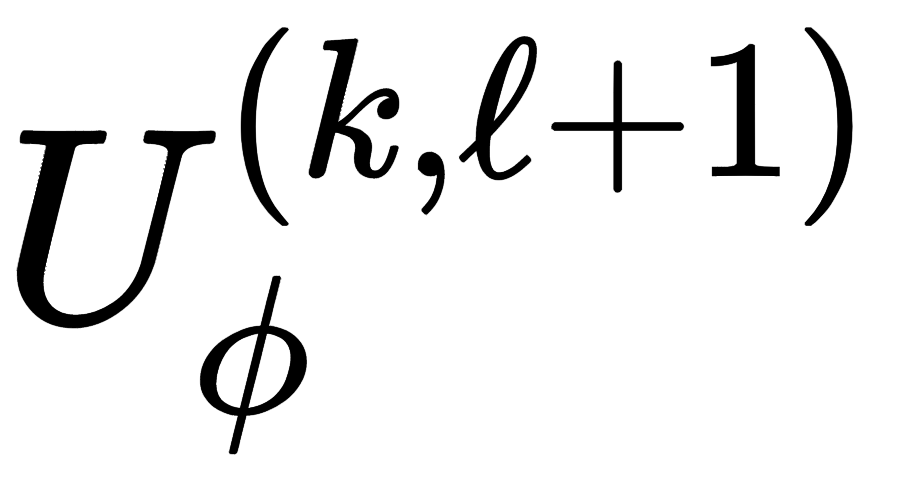 隐层状态更新函数,代表性的机制是 MLP 进行模型训练。
隐层状态更新函数,代表性的机制是 MLP 进行模型训练。GNN phase 2: Readout (different across tasks)
根据任务类型不同,利用节点 embedding 进行适当的转换用于下游任务:
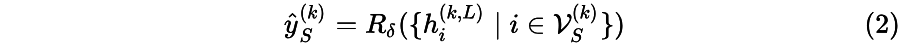
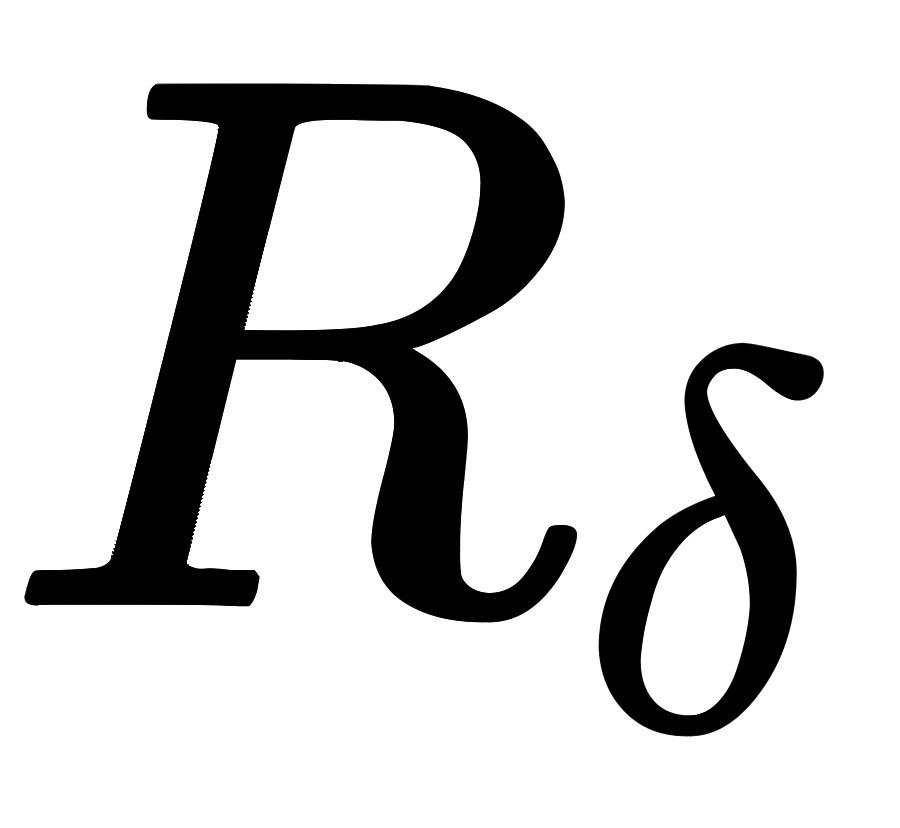
GNN with FL
从全局角度定义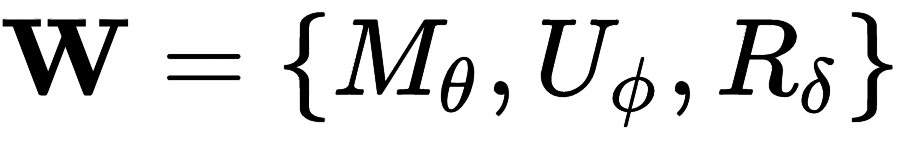
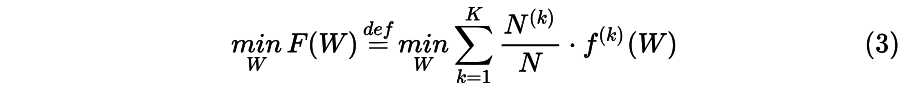
其中,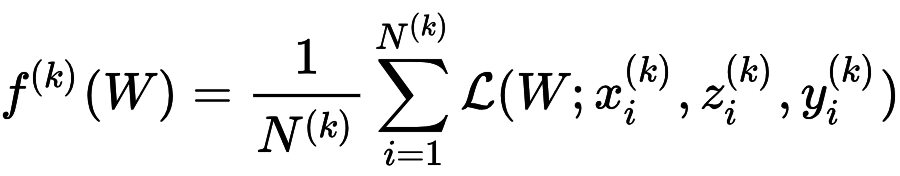
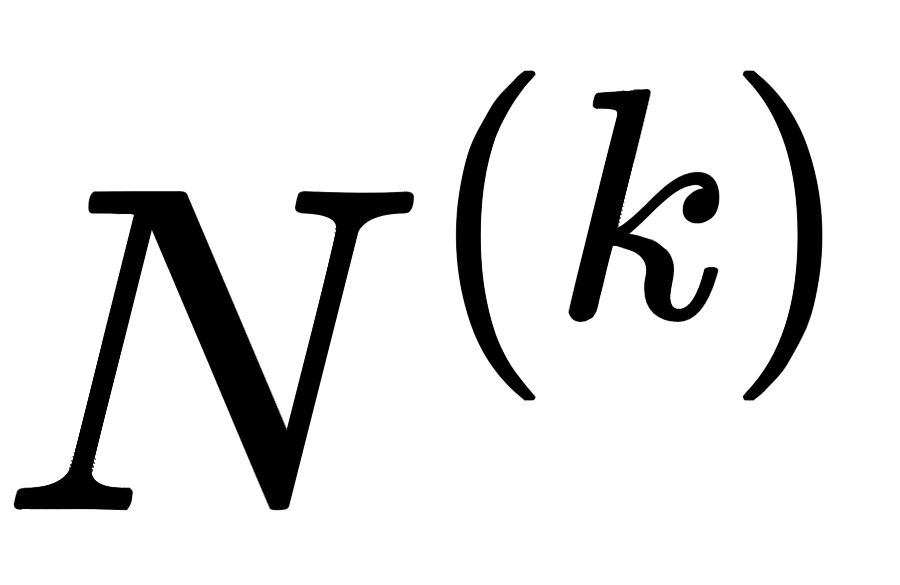
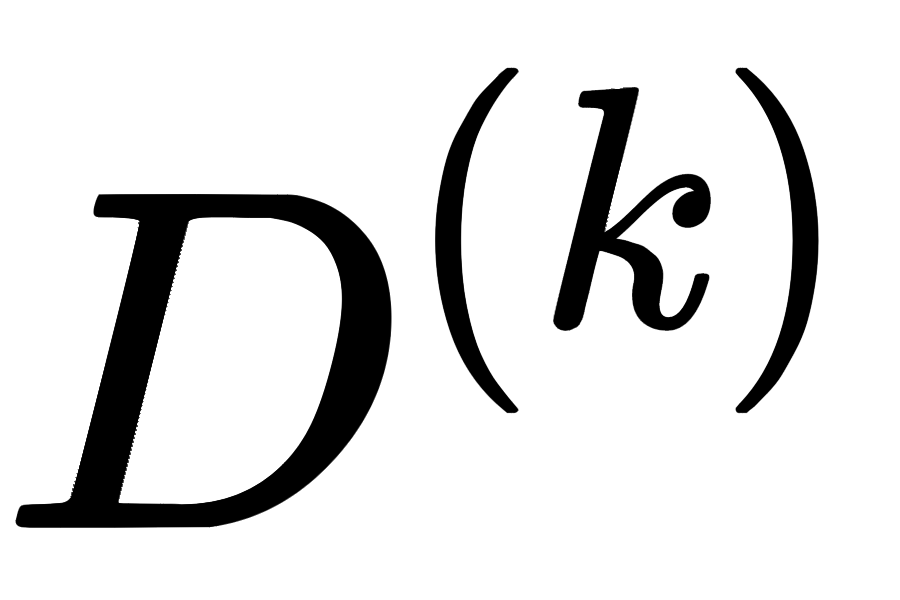
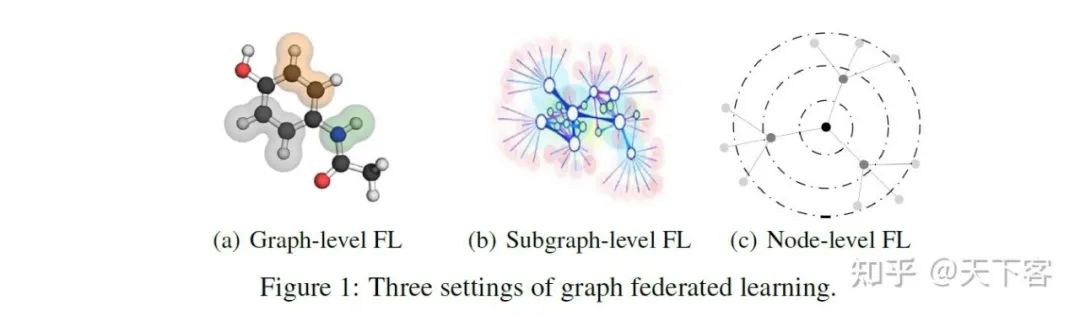
之后根据下游任务不同,划分为三种图联邦学习:
Graph-level FedGraphNN:
每个客户端持有一组图,其中典型的任务是图分类/回归。
现实世界的场景包括分子试验、蛋白质发现等,在这些场景中,由于昂贵的实验,每个机构可能持有一组有限的具有真实标签的图。
Subgraph-level FedGraphNN:
每个客户端持有一个更大的全局图的子图,其中典型的任务是节点分类和链接预测。
现实世界的场景包括推荐系统、知识图谱完成等,其中每个机构可能持有一个用户-物品交互数据或实体/关系数据的子集。
Node-level FedGraphNN:
每个客户端持有一个或多个节点的 ego-networks,其中典型的任务是节点分类和链接预测。
现实世界中的场景包括社会网络、传感器网络等,其中每个节点只看到其 k-hop 邻居和他们在大图中的连接
FedGraphNN 现在所支持的 GNN 和 FL 算法如下:
GNN Model:GCN、GAT、GraphSage、SGC、GIN(PyTorch Geometric)
FL:FedAvg、FedOPT (FedML)
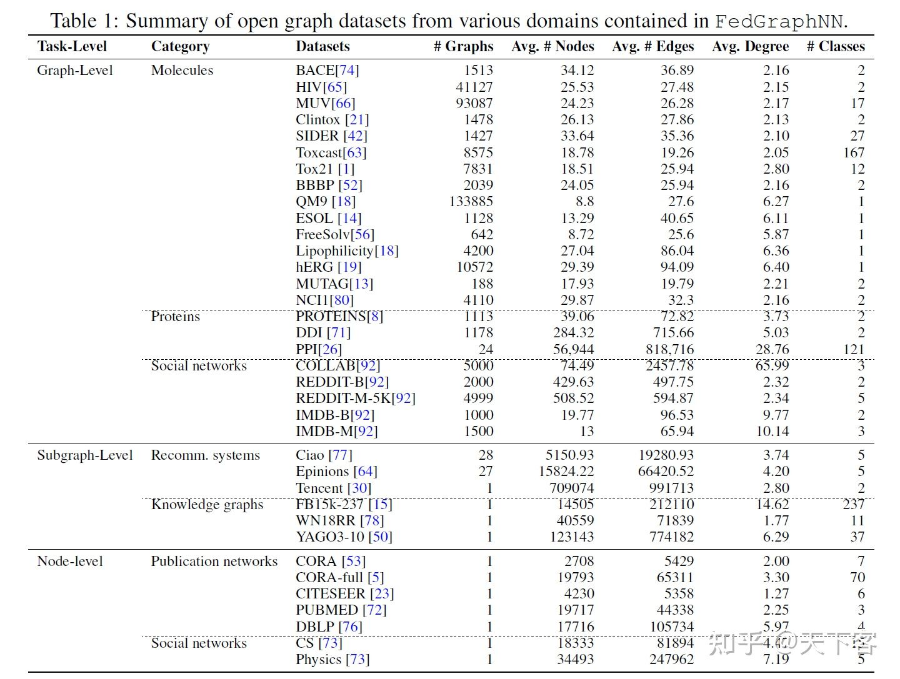
3. FedGraphNN Open Datasets
FedGraphNN 以三类图联邦学习为中心,基于现实世界场景中图数据的分布方式,涵盖大部分领域,包括来自 7 个领域的 36 个数据集,如分子、蛋白质、知识图谱、推荐系统、引文网络和社交网络。
Graph-level Setting:
在现实世界中,生物医学机构可能拥有自己的图数据集,如分子和蛋白质,而社交网络公司可能拥有自己的社区图数据集。
这些图可能构成 GNN 训练的大型和多样化的数据集,但它们不能直接共享。
为了模拟这样的场景,FedGraphNN 利用来自分子机器学习、生物信息学和社会计算领域的数据集,并引入一个新的大规模数据集 hERG,用于联合药物发现。
Subgraph-level Setting:
Subgraph-level 联邦学习的第一个现实场景是推荐系统,用户可以与不同商店或部门拥有的物品进行交互,这使得每个数据所有者只持有全局用户-物品交互图的一部分。
为了模拟这样的场景,FedGraphNN 使用了来自公开来源和内部来源的推荐数据集,这些数据集有高质量的元数据信息。
另一个现实的场景是知识图谱,不同的组织或部门可能只拥有整个知识的一个子集,这是因为在特定领域有不同的重点。
FedGraphNN 整合了FB15k-237、WN18RR 和 YAGO3-10 数据集,其中可以根据关系类型建立子图,以区分专业领域或社区,以区分重点实体。
Node-level Setting:
在社交网络中,每个用户的个人数据可能是敏感的,因此只对他/她的 k-hop 邻居可见。
因此,考虑社交网络中的 Node-level 联邦学习是很自然的,客户持有用户的 ego-networks。
为了模拟这种情况,FedGraphNN 使用社交网络和出版网络,并将其划分为 ego-networks 的集合。
基于三种任务类型,划分三大基本任务:
Graph Classification:
根据图的结构和整体信息对不同类型的图进行分类。
与其他任务不同的是,这需要对整个输入图的属性进行描述。
这项任务在 Graph-level 联邦学习中非常重要,真实的例子有分子属性预测、蛋白质功能预测和社交社区分类。
Link Prediction:
估计图中任何两个节点之间的链接概率。
在 Subgraph-level 联邦学习中很重要,例如在推荐系统和知识图谱中,前者的交互概率是预测的,后者的关系类型是预测的。
在 Node-level 中不太可能,但仍然可行,例如在用户的 ego-networks 中可以尝试朋友建议和社会关系分析。
Node Classification:
预测图中单个节点的标签。
在 Node-level 的联邦学习中比较重要,比如根据一个作者的 k-hop 合作者预测其活跃的研究领域,或者根据一个用户的 k-hop 好友预测其习惯。
在 Subgraph-level 的联邦学习中也可能很重要,比如根据分散在多个医疗机构的病人网络来协同预测疾病的感染情况。
Generating Federated Learning Datasets
不同于传统的 ML 标记数据集,图数据集和现实世界的图可能会由于结构和特征异质性等来源而表现出 no-IID。在联邦学习背景下,多种来源的 no-IID 无法区分。因此 FedGraphNN 的重点是如何产生可重复的和统计的(基于样本的)no-IID。为了产生基于样本的 no-IID,使用非平衡分区算法 (Latent Dirichlet Allocation(LDA))对数据集进行分区,这种方法可以在任何数据领域应用。深度解耦和量化联合 GNN 中的 no-IID 仍然是一个开放的问题。
综上所述,FedGraphNN 为图联邦学习的数据收集和 benchmark 的几个挑战提供了全面的研究和解决方案
收集、分析和分类大量公共的、真实世界的数据集,并将其归入不同的联邦学习 GNN 背景环境(Graph-level、Subgraph-level、Node-level),对应图上的基本任务(Graph Classification、Link Prediction、Node Classification);
通过提供一种新的分割方法并关联元数据,使所有图结构数据集的 no-IID 数据分布的合成程序标准化。
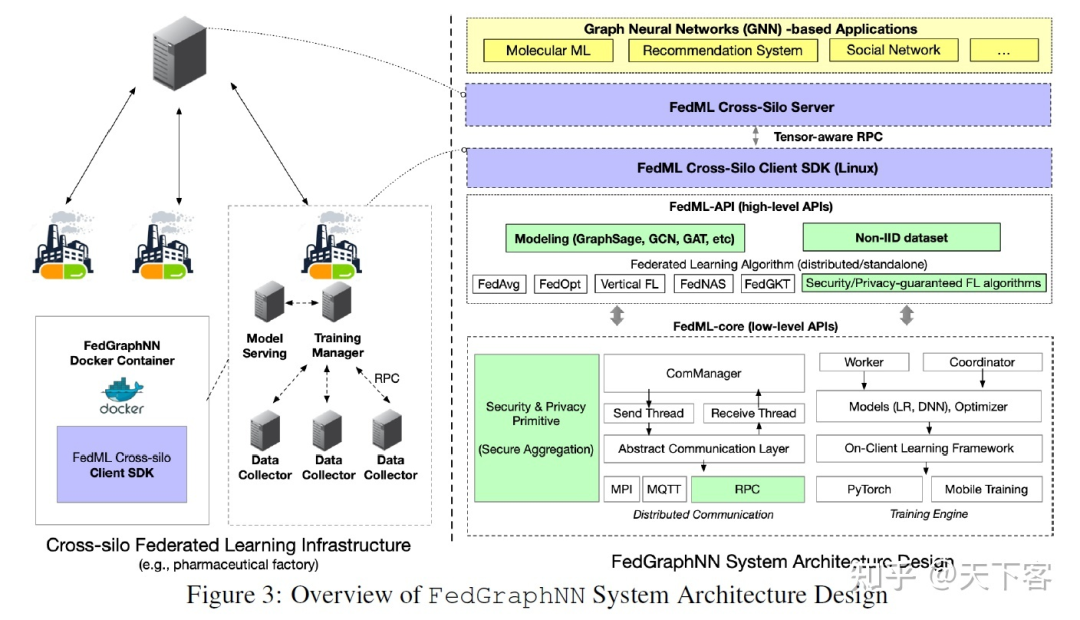
4. FedGraphNN Benchmark System: Efficient, Secure, and Modularized (系统设计部分略)
5. FedGraphNN Empirical Analysis
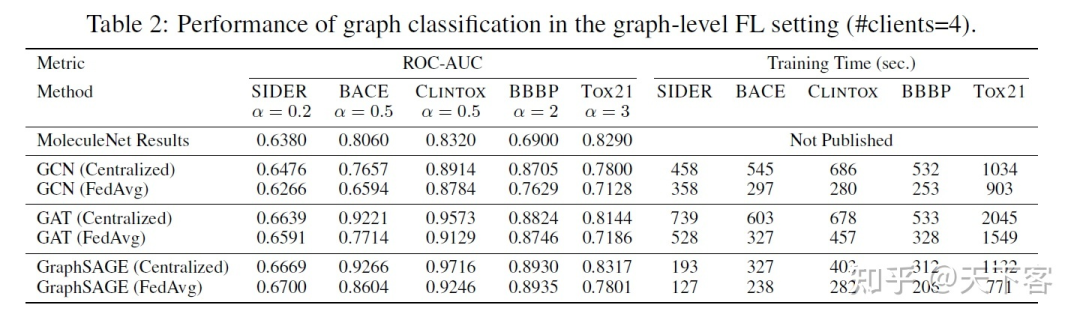
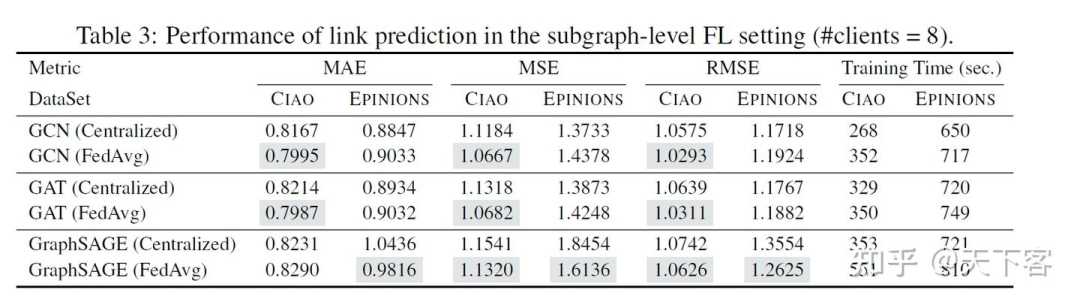
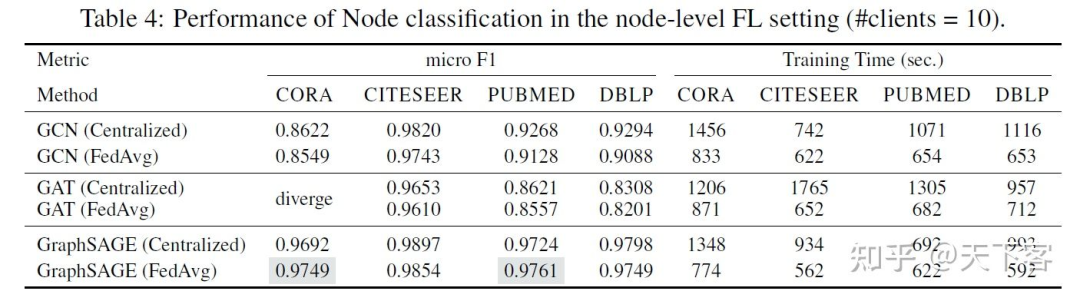
FedGraphNN 实验是在多个 GPU 服务器上进行的,每个服务器配备了 8个NVIDIA Quadro RTX 5000(16GB GPU内存)。实验结果中包含图分类的 ROC-AUC 指标和图回归的 RMSE和 MAE,链接预测的 MAE、MSE 和 RMSE,以及节点分类的 micro-F1 等结果。
下图展示了通过最广泛使用的 FL 算法 FedAvg 训练的几个流行的 GNN 模型的实验结果,以检验 FedGraphNN 的效果。调参后,在表 2、表 3 和表 4 中展示了效果和运行时间。