【IJCAI2019】Part.2:10篇推荐系统相关论文阅读
导读
本文继续简要介绍10篇IJCAI2019会议最新推荐算法相关论文,涉及session-based推荐,序列推荐,异构网络HIN,图神经网络,对抗学习算法等。
编译 | Xiaowen

01
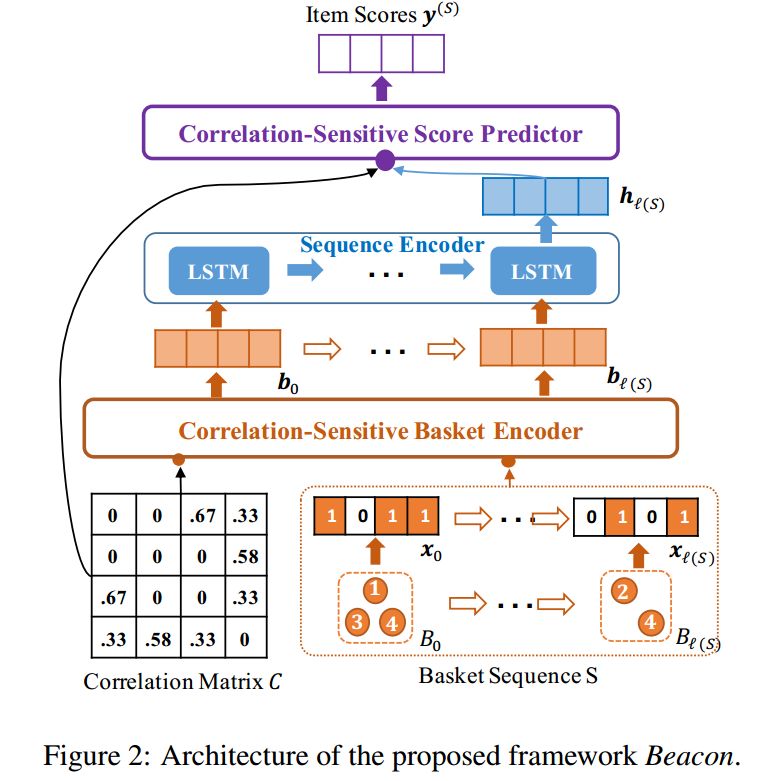
02

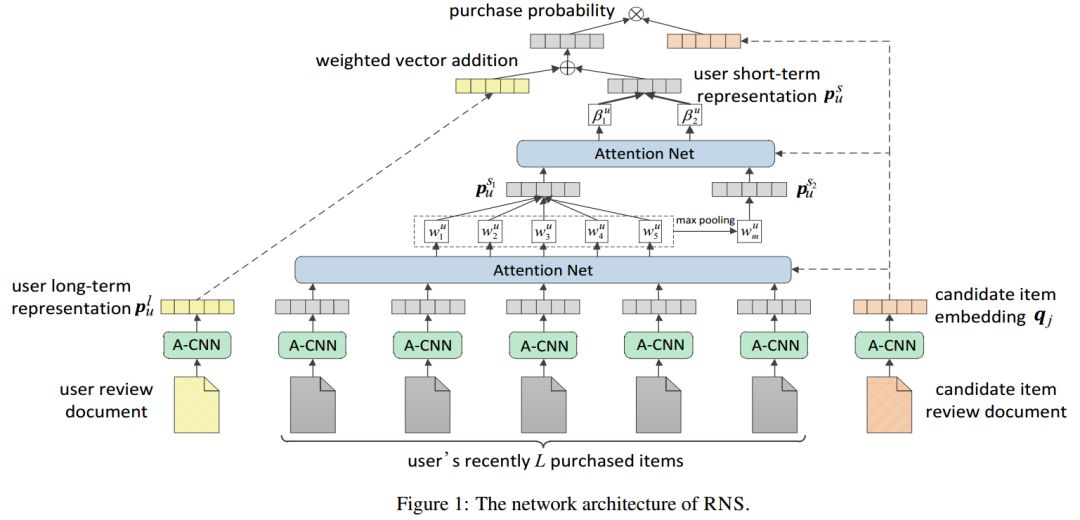
03

Recommendation
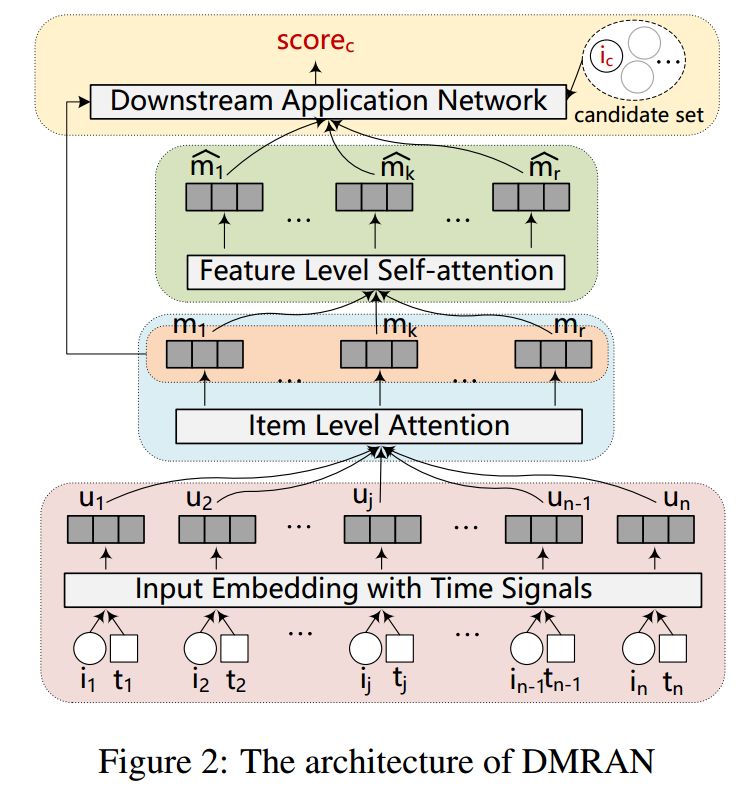
04

via Mixture-Channel Purpose Routing Networks
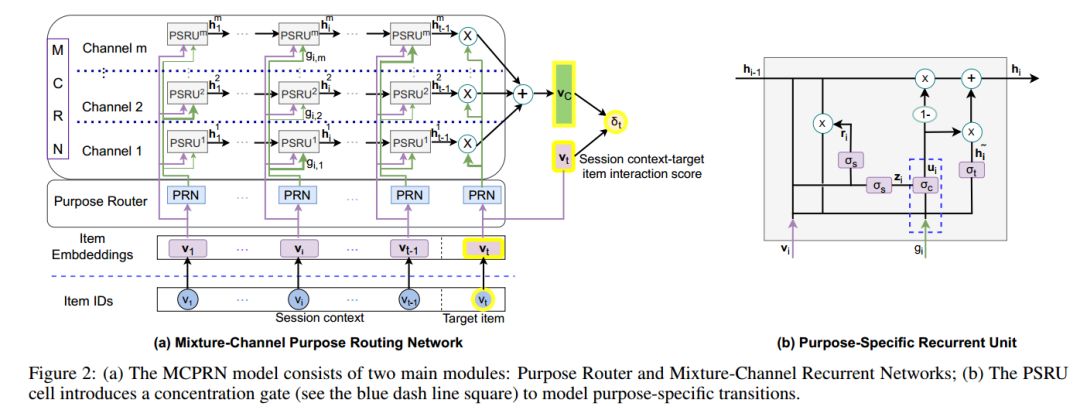
05

Personalized Recommendation
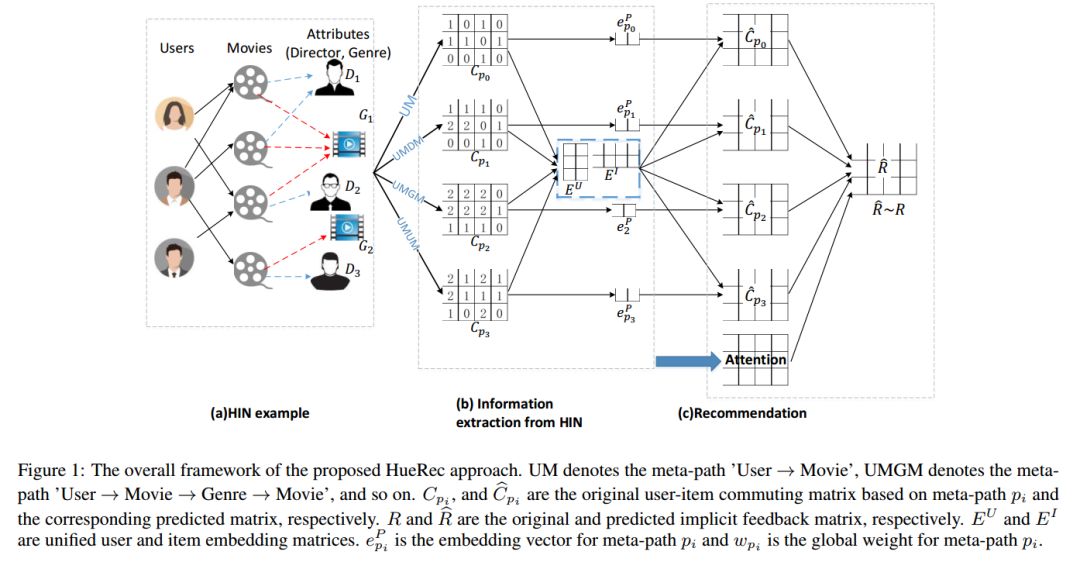
06

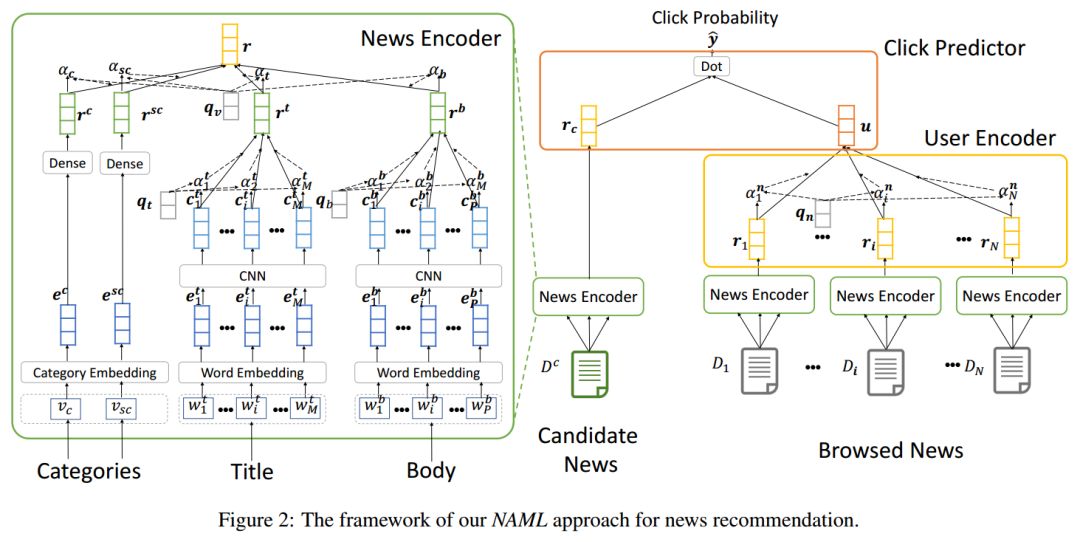
07

Recommendation
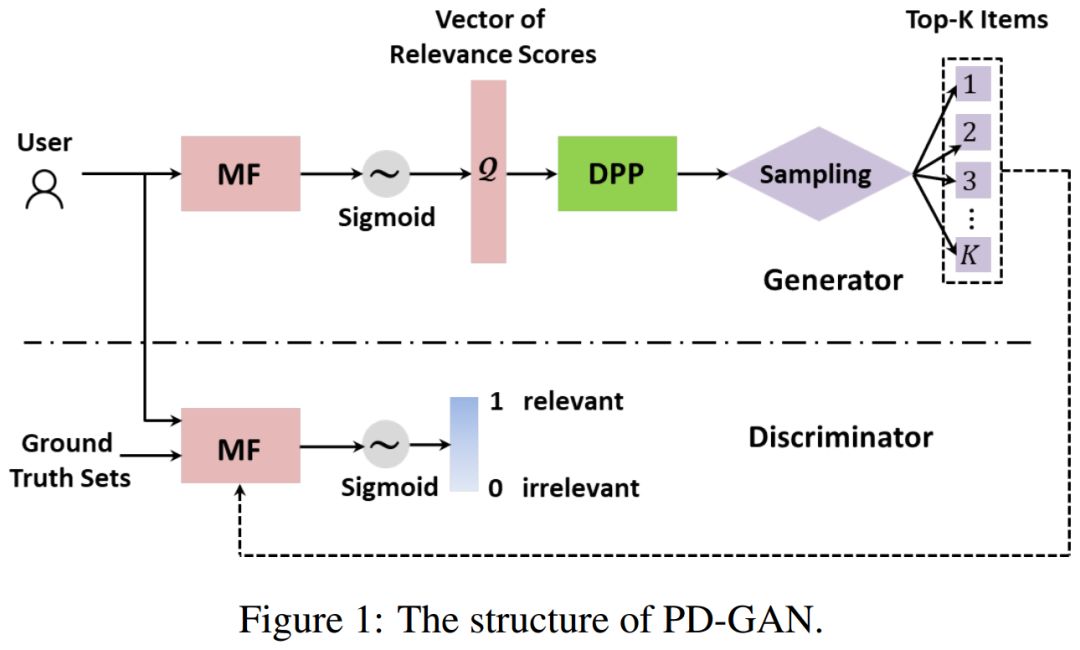
08

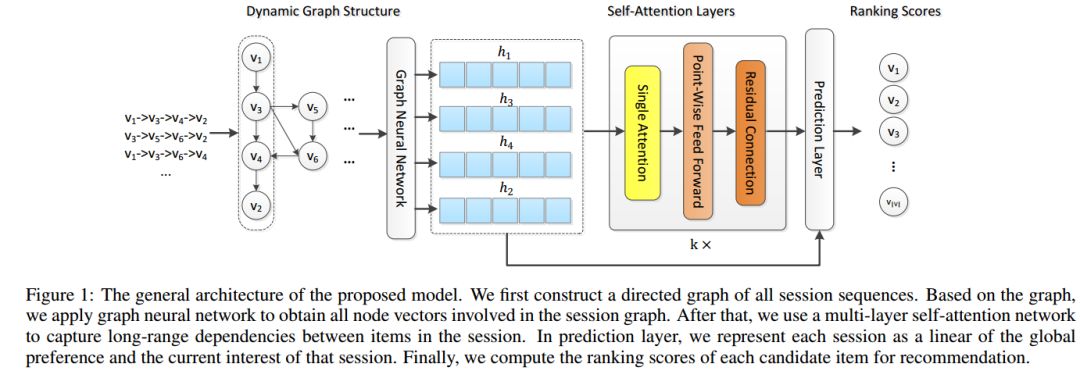
09

Transferring Rating Patterns
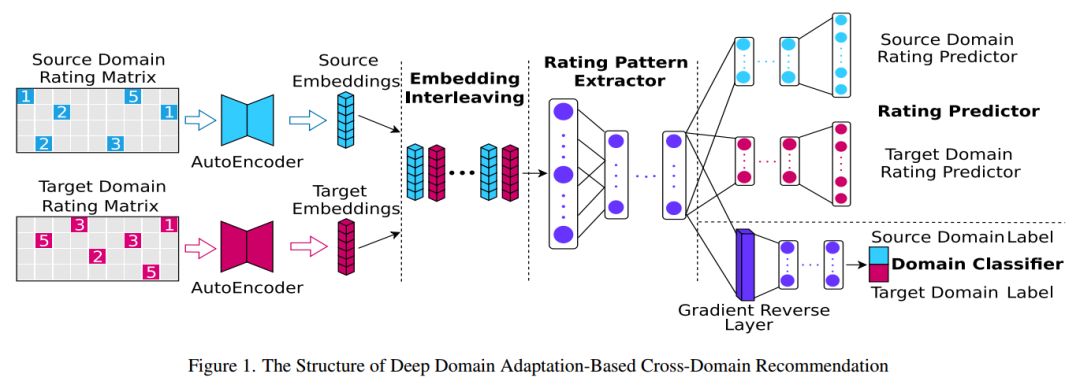
10

Recommender Systems
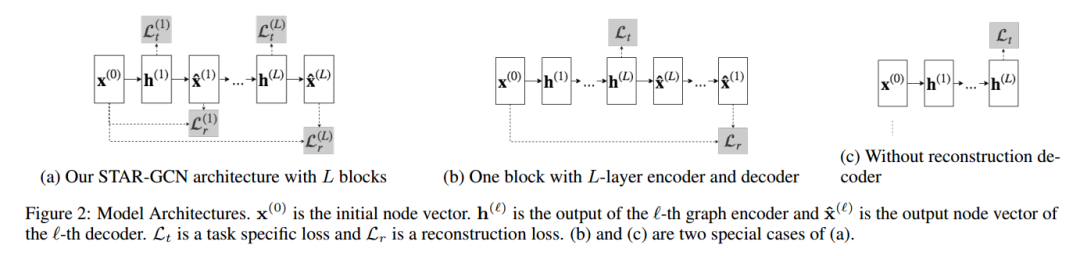





登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文