【重磅】网易开源RL4RS,一个强化学习推荐系统工业数据集(RL for Recommender System)
深度强化学习实验室
近日,由网易伏羲研究团队和伏羲TTG技术团队联合发布的强化学习推荐系统工业数据集RL4RS,正式在Github开源社区开放下载。在之前的2021年年中,该工作曾与IEEE BigData 2021大会合办了网易伏羲第一届大数据竞赛,IEEE BigData Cup 2021: RL-based RecSys,吸引了国内外高校近百支队伍的参赛以及多达7篇的参赛中稿论文,并在大会上成功举办了主题WorkShop。
数据与代码入口:
https://github.com/fuxiAIlab/RL4RS
关于RL4RS的详细情况,可参见已提交至arXiv的相关论文, 论文链接:
https://arxiv.org/pdf/2110.11073.pdf

一、背景信息
基于强化学习的推荐系统(RL-based RS)是指将商品推荐问题转化为多步决策问题,并使用强化学习算法来求解的技术。近年来,随着深度强化学习在Atari游戏、围棋、星际争霸等游戏控制任务上带来的突破性进展,其在聊天机器人、推荐系统等应用场景中崭露出巨大的应用潜力,逐渐迈向实用化的阶段。而推荐系统应用发展到今天,所涌现出来的Slate Recommendation(瓦片式商品推荐),Bundle Recommendation(礼包推荐)等新型应用场景也急需新技术解决一系列问题。作为推荐系统和应用强化学习的重要分支,强化学习推荐系统是备受关注的一个研究方向。
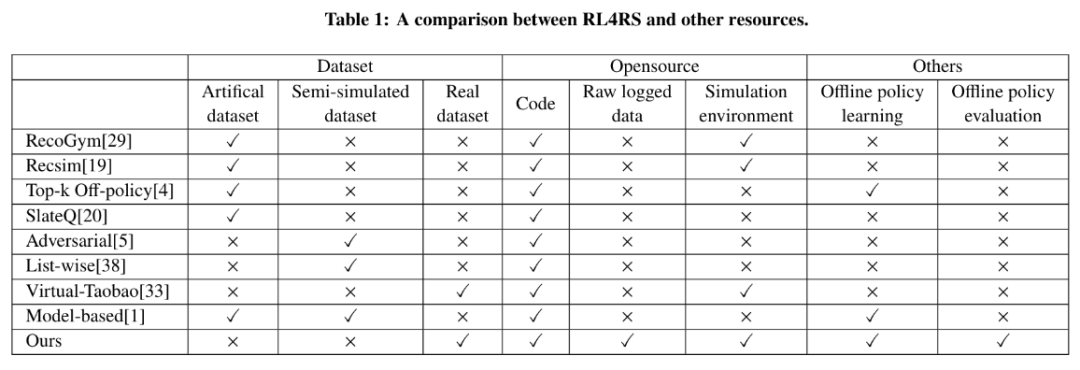
在学术界大力发展应用强化学习的同时,高质量强化学习推荐场景与数据的短缺让缺少相关实验场景的研究人员只能在传统商品推荐数据集上下功夫,特别是需要对传统推荐数据集进行大量有争议的人工转化以符合强化学习问题格式,这使得相关研究难以准确评估。虽然不少业界公司如阿里巴巴,发展了虚拟淘宝VirtualTaobao等贴近业务的模型,但都并没有开源原始的训练数据,所开源的预训练环境模型往往也只有十几维特征维度,且来源于传统的商品推荐场景。为了汇集更多的智慧、推进强化学习推荐系统技术的普及与发展,首个开源原始数据的高质量工业界数据集RL4RS应运而生。RL4RS提供了两个真实数据集,来自于天然适合使用强化学习建模的交互式解锁推荐场景,今年还会进一步增加礼包推荐场景的真实数据集。RL4RS 的诞生致力于降低强化学习推荐系统道路上的数据门槛,为高校、传统推荐场景的研究者们敞开强化学习推荐系统研究的大门。
二、项目主页
论文:https://arxiv.org/pdf/2110.11073.pdf
数据主页:https://github.com/fuxiAIlab/RL4RS
BigData2021 Cup: http://bigdataieee.org/BigData2021/BigDataCupChallenges.html
Kaggle比赛:https://www.kaggle.com/c/bigdata2021-rl-recsys/overview
三、数据集信息
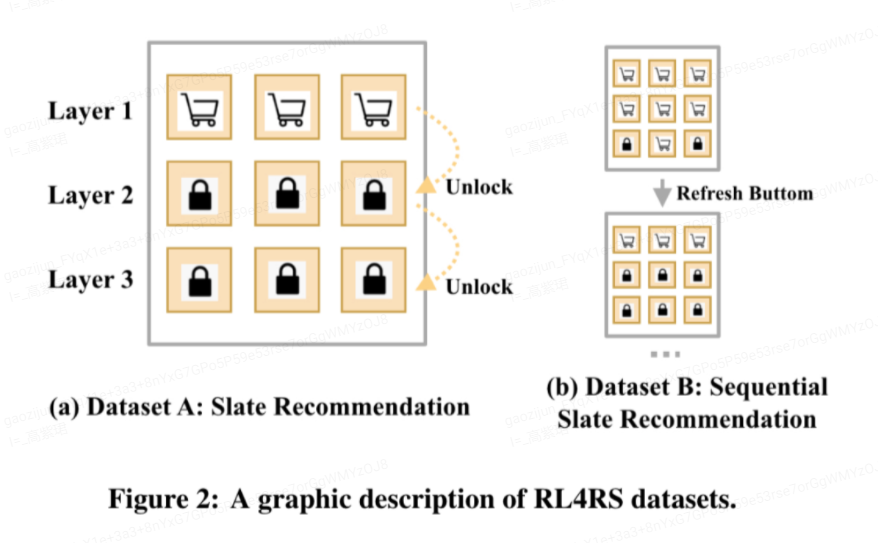
RL4RS包含两个数据集构成,其中每个数据集分别提供了强化学习策略部署前和部署后的用户反馈原始数据。数据集来源于网易游戏的某个交互式解锁商品推荐场景,该场景每次推荐三层商品,每层3个商品,即共推荐9个商品。其交互式解锁规则体现在,用户必须在购买完第k层商品的基础上才能购买下一层的商品。显然,这是一个天然的多步决策场景,用户对单个商品的购买决策不仅受到这个商品的影响,还受到这个商品之后各层商品的影响(是否为了解锁下一层而购买当前商品)。
在RL4RS中,Dataset A和Dataset B分别包含了来自15w用户的172w条和96w条Session数据。其中Dataset A只考虑如何对用户进行单次推荐,负责建模同一个页面商品间的相互影响。Dataset B则是对用户进行多次推荐,需要同时考虑同一页面商品间和多次推荐交互(跨页面)的相互影响。为方便研究者们快速进行实验,我们在原始数据(商品曝光、商品信息、用户反馈)外,提供了预训练好的强化学习环境模型文件。
四、实验结果
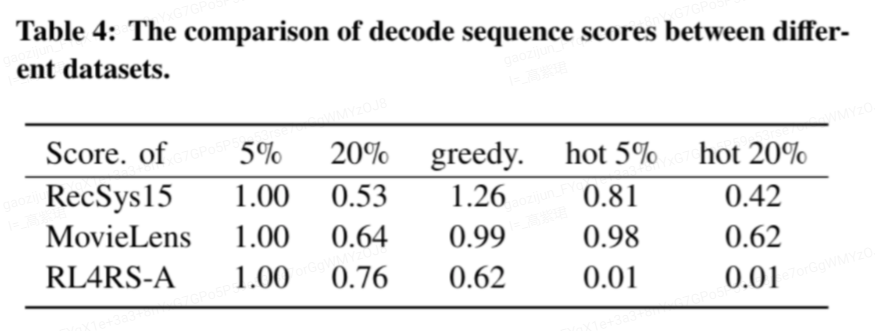
为了验证数据相比于传统推荐数据集的优越性,我们以RL4RS为实验数据,基于最新的强化学习技术TrajectoryTransformer搭建了数据集MDP特性分析工具进行验证。可以看到对于一般的传统推荐数据集,如Recsys15和Movielens数据集,单步贪婪的推荐策略已经足够的好。而在我们的RL4RS数据集上,单步贪婪的推荐策略显著差于多步决策最优(图表中的Score of 5%)的结果。主客观实验均表明,该数据集符合强化学习推荐系统建模的需求,数据库质量达标。除了提供验证数据集是否适合建模为RL问题的MDP特性分析工具之外,我们还提供了大量基准算法的代码,在支持流行强化学习库RLlib和离线强化学习库d3rlpy基础上,新增了支持item mask、支持原始特征作为observation、item embedding作为连续动作、环境模型支持批量推断、http-env以分布式部署环境模型等功能。
五、未来展望
强化学习推荐系统在Offline Policy Evaluation、Batch RL等方面还存在很多研究热点,RL4RS提供了强化学习策略部署前后的两份数据,便于各位研究者们研究。
RL4RS将在今年新增一份同样来自真实工业界的礼包推荐场景数据集。
六、致谢
感谢某神秘游戏制作组提供的实验场景和伏羲用户画像组策划团队的努力和付出。
感谢各位推荐系统和应用强化学习的热爱者们,期待RL4RS在你们手中发挥出更大的作用,连接学术界研究与工业界落地。



