【收藏】支持向量机原理详解+案例+代码!【点击阅读原文下载】
或许你已经开始了自己的探索,听说过线性可分、核心技巧、核函数等术语。支持向量机(SVM)算法的核心理念非常简单,而且将其应用到自然语言分类任务中也不需要大部分复杂的东西。【数据+代码下载请点击阅读原文】
(原理部分来自机器之心:
https://mp.weixin.qq.com/s/5tUQ9B5juP-Vg8z-gp60rg)
SVM 是如何工作的?
支持向量机的基础概念可以通过一个简单的例子来解释。让我们想象两个类别:红色和蓝色,我们的数据有两个特征:x 和 y。我们想要一个分类器,给定一对(x,y)坐标,输出仅限于红色或蓝色。我们将已标记的训练数据列在下图中:
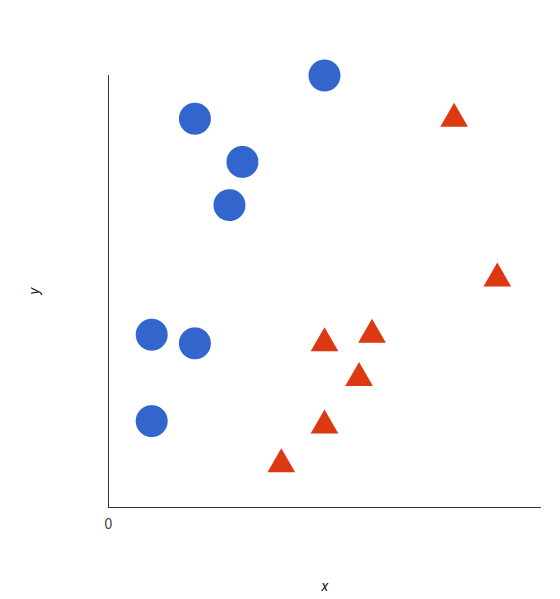
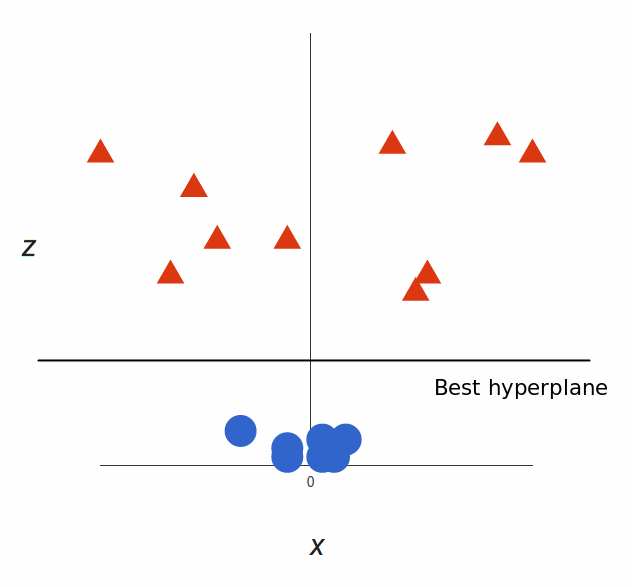
支持向量机会接受这些数据点,并输出一个超平面(在二维的图中,就是一条线)以将两类分割开来。这条线就是判定边界:将红色和蓝色分割开。
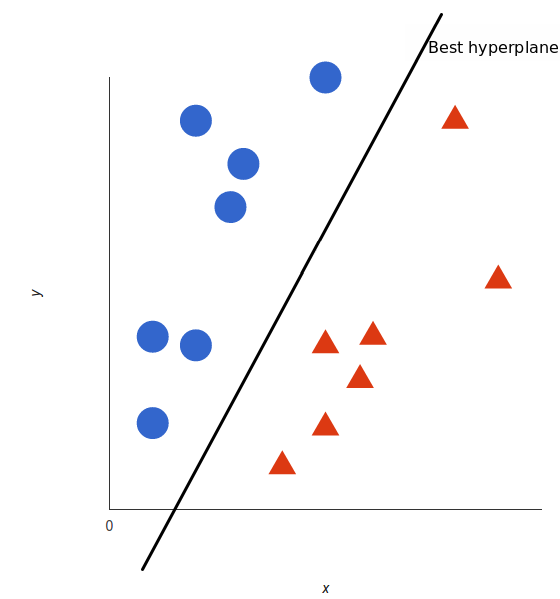
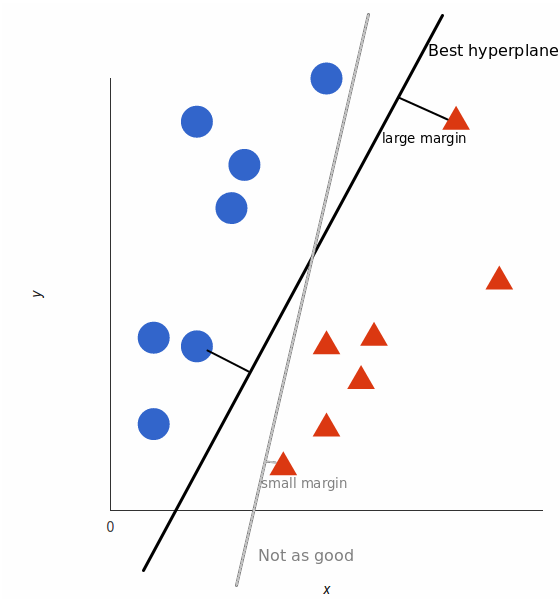
但是,最好的超平面是什么样的?对于 SVM 来说,它是最大化两个类别边距的那种方式,换句话说:超平面(在本例中是一条线)对每个类别最近的元素距离最远。
线性数据
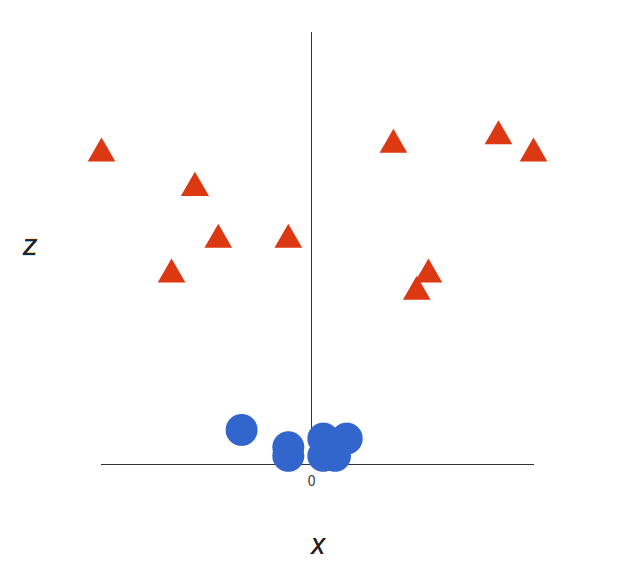
上面的例子很简单,因为那些数据是线性可分的——我们可以通过画一条直线来简单地分割红色和蓝色。然而,大多数情况下事情没有那么简单。看看下面的例子:
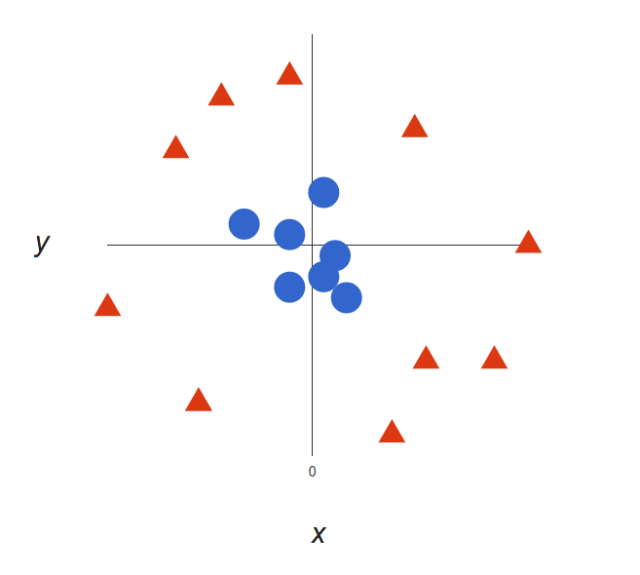
很明显,你无法找出一个线性决策边界(一条直线分开两个类别)。然而,两种向量的位置分得很开,看起来应该可以轻易地分开它们。
这个时候我们需要引入第三个维度。迄今为止,我们有两个维度:x 和 y。让我们加入维度 z,并且让它以直观的方式出现:z = x² + y²(没错,圆形的方程式)
于是我们就有了一个三维空间,看看这个空间,他就像这样:
支持向量机将会如何区分它?很简单:
太棒了!请注意,现在我们处于三维空间,超平面是 z 某个刻度上(比如 z=1)一个平行于 x 轴的平面。它在二维上的投影是这样:
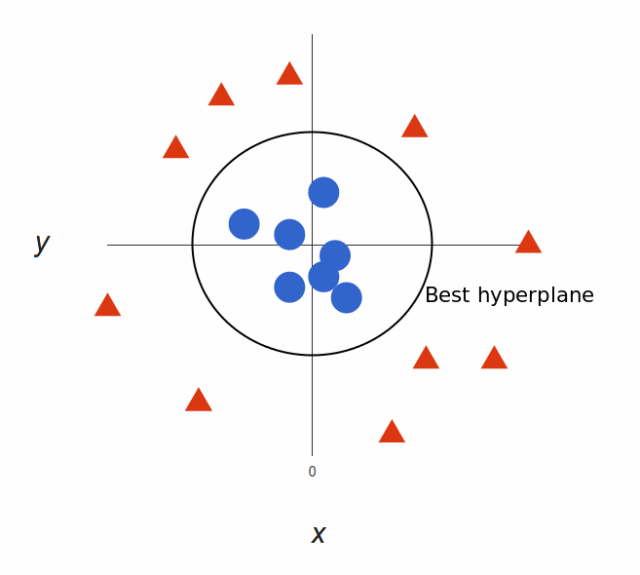
于是,我们的决策边界就成了半径为 1 的圆形,通过 SVM 我们将其成功分成了两个类别。
核函数
在以上例子中,我们找到了一种通过将空间巧妙地映射到更高维度来分类非线性数据的方法。然而事实证明,这种转换可能会带来很大的计算成本:可能会出现很多新的维度,每一个都可能带来复杂的计算。为数据集中的所有向量做这种操作会带来大量的工作,所以寻找一个更简单的方法非常重要。
还好,我们已经找到了诀窍:SVM 其实并不需要真正的向量,它可以用它们的数量积(点积)来进行分类。这意味着我们可以避免耗费计算资源的境地了。我们需要这样做:
想象一个我们需要的新空间:
z = x² + y²
找到新空间中点积的形式:
a · b = xa· xb + ya· yb + za· zb
a · b = xa· xb + ya· yb + (xa² + ya²) · (xb² + yb²)
让 SVM 处理新的点积结果——这就是核函数
这就是核函数的技巧,它可以减少大量的计算资源需求。通常,内核是线性的,所以我们得到了一个线性分类器。但如果使用非线性内核(如上例),我们可以在完全不改变数据的情况下得到一个非线性分类器:我们只需改变点积为我们想要的空间,SVM 就会对它忠实地进行分类。
注意,核函数技巧实际上并不是 SVM 的一部分。它可以与其他线性分类器共同使用,如逻辑回归等。支持向量机只负责找到决策边界。
支持向量机如何用于自然语言分类?
有了这个算法,我们就可以在多维空间中对向量进行分类了。如何将它引入文本分类任务呢?首先你要做的就是把文本的片断整合为一个数字向量,这样才能使用 SVM 进行区分。换句话说,什么属性需要被拿来用作 SVM 分类的特征呢?
最常见的答案是字频,就像在朴素贝叶斯中所做的一样。这意味着把文本看作是一个词袋,对于词袋中的每个单词都存在一个特征,特征值就是这个词出现的频率。
这样,问题就被简化为:这个单词出现了多少次,并把这个数字除以总字数。在句子「All monkeys are primates but not all primates are monkeys」中,单词 mokey 出现的频率是 2/10=0.2,而 but 的频率是 1/10=0.1。
对于计算要求更高的问题,还有更好的方案,我们也可以用 TF-IDF。
现在我们做到了,数据集中的每个单词都被几千(或几万)维的向量所代表,每个向量都表示这个单词在文本中出现的频率。太棒了!现在我们可以把数据输入 SVM 进行训练了。我们还可以使用预处理技术来进一步改善它的效果,如词干提取、停用词删除以及 n-gram。
选择核函数
现在我们有了特征向量,唯一要做的事就是选择模型适用的核函数了。每个任务都是不同的,核函数的选择有关于数据本身。在我们的例子中,数据呈同心圆排列,所以我们需要选择一个与之匹配的核函数。
既然需要如此考虑,那么什么是自然语言处理需要的核函数?我们需要费线性分类器吗?亦或是数据线性分离?事实证明,最好坚持使用线性内核,为什么?
回到我们的例子上,我们有两种特征。一些现实世界中 SVM 在其他领域里的应用或许会用到数十,甚至数百个特征值。同时自然语言处理分类用到了数千个特征值,在最坏的情况下,每个词都只在训练集中出现过一次。这会让问题稍有改变:非线性核心或许在其他情况下很好用,但特征值过多的情况下可能会造成非线性核心数据过拟合。因此,最好坚持使用旧的线性核心,这样才能在那些例子中获得很好的结果。
Python实现
题目:
模式识别中著名的数据集。本实验通过花萼(sepal)和花瓣(petal)的长和宽,建立SVM分类器来判断样本属于山鸢尾(Iris Setosa)、变色鸢尾(Iris Versicolor)还是维吉尼亚鸢尾(Iris Virginica)。请按要求完成实验。
数据集:
文件iris.txt为该实验的数据集,包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征(按顺序分 鸢尾花数据集(Iris data set)是模别为花萼长度、花萼宽度、花瓣长度、花瓣宽度)和样本的类别信息(Iris Setosa、Iris Versicolor、Iris Virginica中的一种)。
文件列表如下:(所有数据+代码下载请点击阅读原文)
iris.txt 原始数据集
iris_train.txt 训练数据集
iris_test.txt 测试数据集
SVM.py 未采用pca降维的SVM分类器
SVM_PCA.py 采用pca降维的SVM分类器
SVM.py代码如下:
1#!/usr/bin/python
2#-*- coding: utf-8 -*-
3from numpy import *
4import matplotlib.pyplot as plt
5import matplotlib.animation as ai
6import numpy as np
7import time
8
9def loadData(): #加载函数
10 dataMat = []
11 labelMat1 = []
12 labelMat2 = []
13 labelMat3 = []
14 ylabel = []
15 fr = open('iris_train.txt')
16 for line in fr.readlines():
17 lineArr = line.strip().split(',')
18 dataMat.append([float(lineArr[0]), float(lineArr[1]), float(lineArr[2]), float(lineArr[3])])
19 if(lineArr[4]=='Iris-setosa'):
20 labelMat1.append(float(1))
21 else:
22 labelMat1.append(float(-1))
23 if(lineArr[4]=='Iris-versicolor'):
24 labelMat2.append(float(1))
25 else:
26 labelMat2.append(float(-1))
27 if(lineArr[4]=='Iris-virginica'):
28 labelMat3.append(float(1))
29 else:
30 labelMat3.append(float(-1))
31 ylabel.append(lineArr[4])
32 return dataMat,labelMat1,labelMat2,labelMat3,ylabel
33
34def loadData_test():
35 dataMat = []
36 ylabel = []
37 fr = open('iris_test.txt')
38 for line in fr.readlines():
39 lineArr = line.strip().split(',')
40 dataMat.append([float(lineArr[0]), float(lineArr[1]), float(lineArr[2]), float(lineArr[3])])
41 ylabel.append(lineArr[4])
42 return dataMat,ylabel
43
44
45def pca(dataMat, topNfeat):
46 meanVals = mean(dataMat, axis = 0) #求平均值
47 meanRemoved = dataMat - meanVals #去平均值
48 covMat = cov(meanRemoved,rowvar=0) #计算协防差矩阵
49 eigVals, eigVects = linalg.eig(mat(covMat))
50 eigValInd = argsort(eigVals)
51 #从小到大对N个值排序
52 eigValInd = eigValInd[: -(topNfeat + 1) : -1]
53 redEigVects = eigVects[:, eigValInd]
54 #将数据转换到新空间
55 lowDDataMat = meanRemoved * redEigVects
56 #reconMat = (lowDDataMat * redEigVects.T) + meanVals
57 return lowDDataMat
58
59def selectJrand(i,m):
60 j=i #排除i
61 while (j==i):
62 j = int(random.uniform(0,m))
63 return j
64
65def clipAlpha(aj,H,L):
66 if aj > H:
67 aj = H
68 if L > aj:
69 aj = L
70 return aj
71
72def smoSimple(dataMatrix, classLabels, C, toler, maxIter):
73 labelMat = mat(classLabels).T
74 b = -1; m,n = shape(dataMatrix)
75 alphas = mat(zeros((m,1)))
76 iter = 0
77 while (iter < maxIter):
78 alphaPairsChanged = 0 #alpha是否已经进行了优化
79 for i in range(m):
80 # w = alpha * y * x; f(x_i) = w^T * x_i + b
81 # 预测的类别
82 fXi = float(multiply(alphas,labelMat).T*dataMatrix*dataMatrix[i,:].T) + b
83 Ei = fXi - float(labelMat[i]) #得到误差,如果误差太大,检查是否可能被优化
84 #必须满足约束
85 if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
86 j = selectJrand(i,m)
87 fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
88 Ej = fXj - float(labelMat[j])
89 alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy()
90 if (labelMat[i] != labelMat[j]):
91 L = max(0, alphas[j] - alphas[i])
92 H = min(C, C + alphas[j] - alphas[i])
93 else:
94 L = max(0, alphas[j] + alphas[i] - C)
95 H = min(C, alphas[j] + alphas[i])
96 if L==H: #print "L==H";
97 continue
98 # Eta = -(2 * K12 - K11 - K22),且Eta非负,此处eta = -Eta则非正
99 eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
100 if eta >= 0: #print "eta>=0";
101 continue
102 alphas[j] -= labelMat[j]*(Ei - Ej)/eta
103 alphas[j] = clipAlpha(alphas[j],H,L)
104 #如果内层循环通过以上方法选择的α_2不能使目标函数有足够的下降,那么放弃α_1
105 if (abs(alphas[j] - alphaJold) < 0.00001): #print "j not moving enough";
106 continue
107 alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
108 b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
109 b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
110 if (0 < alphas[i]) and (C > alphas[i]): b = b1
111 elif (0 < alphas[j]) and (C > alphas[j]): b = b2
112 else: b = (b1 + b2)/2.0
113 alphaPairsChanged += 1
114 if (alphaPairsChanged == 0): iter += 1
115 else: iter = 0
116 return b,alphas
117
118def calcWs(alphas,dataMatrix, labelMat):
119 m,n = shape(dataMatrix)
120 w = zeros((n,1))
121 for i in range(m):
122 w += multiply(alphas[i]*labelMat[i],dataMatrix[i,:].T)
123 return w
124
125def pred(dataMat, labelMat, w1, b1,w3,b3):
126 dataMat = mat(dataMat)
127 sum1 =0
128 m,n = shape(dataMat)
129 for i in range(m):
130 if(dataMat[i]*w1 + b1 > 0.0 and labelMat[i]=='Iris-setosa'):
131 sum1 +=1
132 elif(dataMat[i]*w3 + b3 > 0.0 and labelMat[i]=='Iris-virginica'):
133 sum1 +=1
134 elif(dataMat[i]*w3 + b3 < 0.0 and dataMat[i]*w1 + b1 < 0.0 and labelMat[i]=='Iris-versicolor'):
135 sum1 +=1
136 m = float(sum1)/float(m)*100
137 print "正确率为: " , m
138
139
140xdata,ydata1,ydata2,ydata3,ylabe = loadData()
141xdata_test, ylabe_test = loadData_test()
142xdata = mat(xdata)
143xdata_test = mat(xdata_test)
144b1 , alphas1 = smoSimple(xdata,ydata1,0.8,0.0001,40)
145#b2 , alphas2 = smoSimple(X,ydata2,0.8,0.0001,40)
146b3 , alphas3 = smoSimple(xdata,ydata3,0.8,0.0001,40)
147w1 = calcWs(alphas1,xdata,ydata1)
148#w2 = calcWs(alphas2,X,ydata2)
149w3 = calcWs(alphas3,xdata,ydata3)
150pred(xdata_test, ylabe_test, w1, b1, w3, b3)




