【机器学习理论】我所理解的 SVM(支持向量机)- 1
转自:机器学习算法与自然语言处理
前 言
众所周知 SVM 是非常强大的一种分类算法,有着媲美神经网络的分类效果,实现过程却简单得多。受限于我的能力,这篇文章不会系统地介绍 SVM(因为我并不是线性代数、凸优化等方面的专家),而是以一个学习者的角度描述 SVM 产生的过程,由于内容较长,计划分成三到四篇。
1一个好的分类是怎么样的
图中的两组数据,显然它们是线性可分(linear separable)的,图里给出的三条分界线都可以准确区分这两类数据,它们是不是一样好?如果不是,哪一条看起来更加合适?
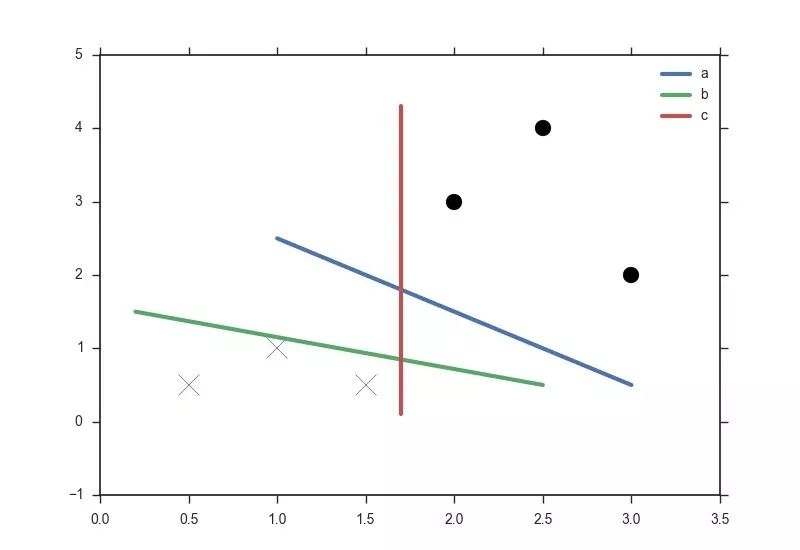
直觉告诉我们是 a。相比之下,b 和 c 离个别点太近了,我们很难拍着胸脯说“这个点在分界线下面,所以绝对是 X",因为分界线稍微挪一挪就可以改变这些点的属性,我们想要的是一个相对自信的分界线,使靠近分界线的点与分界线的距离足够大,上图中的分界线 a 就符合我们的需求。
原文链接:
https://mp.weixin.qq.com/s/n731WPpYhJAG6CmoKN2Hig
登录查看更多
相关内容

在机器学习中,支持向量机(SVM,也称为支持向量网络)是带有相关学习算法的监督学习模型,该算法分析用于分类和回归分析的数据。支持向量机(SVM)算法是一种流行的机器学习工具,可为分类和回归问题提供解决方案。给定一组训练示例,每个训练示例都标记为属于两个类别中的一个或另一个,则SVM训练算法会构建一个模型,该模型将新示例分配给一个类别或另一个类别,使其成为非概率二进制线性分类器(尽管方法存在诸如Platt缩放的问题,以便在概率分类设置中使用SVM)。SVM模型是将示例表示为空间中的点,并进行了映射,以使各个类别的示例被尽可能宽的明显间隙分开。然后,将新示例映射到相同的空间,并根据它们落入的间隙的侧面来预测属于一个类别。
Arxiv
20+阅读 · 2019年12月19日
Arxiv
19+阅读 · 2019年11月20日
Arxiv
5+阅读 · 2019年1月29日
Arxiv
8+阅读 · 2018年3月13日



相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2019年12月19日
Arxiv
19+阅读 · 2019年11月20日
Arxiv
5+阅读 · 2019年1月29日
Arxiv
8+阅读 · 2018年3月13日