AAAI 2018 | 港中文-商汤联合论文:自监督语义分割的混合与匹配调节
机器之心发布
作者:Xiaohang Zhan、Ziwei Liu、Ping Luo、Xiaoou Tang、Chen Change Loy
这篇文章介绍了香港中大-商汤科技联合实验室的新论文「Mix-and-Match Tuning for Self-supervised Semantic Segmentation」,该论文被 AAAI 2018 录用为 Spotlight。
用于语义分割的卷积神经网络通常需要大量的标注数据来进行预训练,例如 ImageNet 和 MS-COCO。自监督学习最近被提出来,主要用来减少标注工作量,它的预训练过程中无需任何人工标注。此项研究已经在图像分割领域中得到了应用(Zhang, Isola, and Efros 2016a;Larsson, Maire, and Shakhnarovich 2016; 2017)。其关键在于,在此过程中引入了一个无监督的「预训练任务」,这个任务可以在无标注数据上执行,用来学习图像的描述。然而,很多预训练任务缺乏能够对目标任务进行有效区分的监督信号,导致最终的结果比有监督的初始化要低很多。在本文的研究中,我们通过引入「混合与匹配」的机制来解决这个局限性。这个机制可以兼容很多自监督与训练方法,相比于原来的方案无需更多的标注数据。利用了「混合与匹配」机制的自监督初始化模型,其最终结果可以匹敌甚至超越全监督的初始化模型。
自监督学习通常分为两个步骤:无监督的预训练和对目标任务的微调。预训练步骤不只需要数据本身,而无需数据的标注结果。它需要设计一个预训练任务,利用从数据本身到的的监督信号来训练。例如,图像上色任务(Larsson, Maire, and Shakhnarovich 2017),利用了图像可分解成亮度和色彩这样的特点,通过输入图像亮度,来预测图像的颜色。在此过程中学习到带有某种程度语义的图像描述子,并将之通过微调应用在最终的语义分割任务上。自监督学习展现出其强大的学习能力,即使在没有标注的数据上,也能获得不错的初始化效果,大大超越了随机初始化的模型。
尽管自监督学习很有前景,但目前其表现结果还远不如有监督的初始化。例如,使用 VGG-16 网络,用图像上色来进行预训练,在 PASCAL VOC2012 上能得到 56.0% mIoU 的结果,大大超过随机初始化的 35.0% mIoU 的结果。但用 ImageNet 分类任务来初始化,则可以达到 64.2%。这说明自监督预训练和有监督预训练之间还有较大的差距。
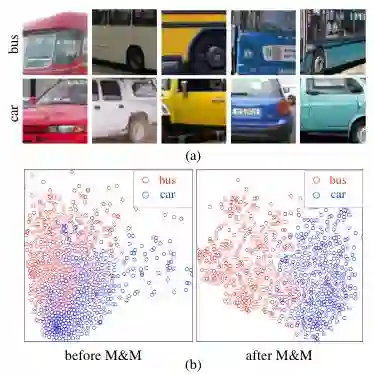
图一:(a)展示了来自「汽车」和「巴士」两个类别的图像块,它们具有非常相近的色彩分布。(b)展示了这两个类别的深层特征分布,执行过「混合与匹配」的特征对于这两个类别有更好的区分性。
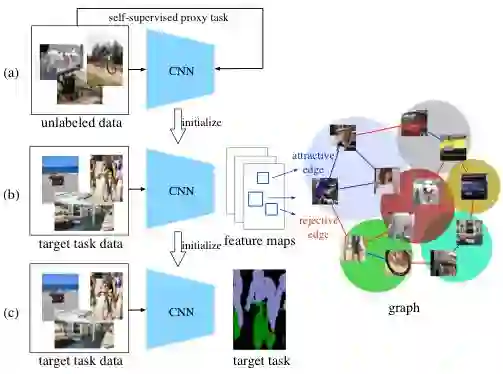
图二:我们提出的方法的整体流程图。我们的方法在自监督预训练任务与最终目标任务之间插入了「混合与匹配」过程。
我们认为这个差距的主要原因在于,自监督预训练任务和最终的目标任务在语义层次上有较大的区别。例如对于图像上色来说,这个任务中网络能学到对颜色分布比较敏感的图像描述子,这样的描述子对图像上色很有帮助,但对更高的语义层次,其作用会弱很多。例如,在图一(a)中,汽车和巴士的颜色分布非常接近,因此基于图像上色得到的图像描述子,对于汽车和巴士会有大范围的重合,难以区分,见图一(b)。
要提升自监督图像分割的表现,需要让图像描述子对目标任务有更好的区分能力。然而这个目标并不容易,因为图像分割的数据集通常很小,其标注数量很少,一般来说只有几千张图片。现有的方法一般用」Softmax」损失函数来利用这些标注,对于初始化得很好的有监督初始化网络,它是足够有效的,但对于初始化较差的自监督初始化网络,「Softmax」是不够的。我们认为,利用以像素为单位的图像分割的标注,」Softmax」并不是唯一的方式。
在这项研究中,我们提出了一个新的策略,叫「混合与匹配」(Mix-and-Match),来更好地利用有限的标注信息,从而提升自监督初始化网络的性能。见图二,「混合与匹配」紧接自监督预训练任务之后,作为一个中间过程用来弥补预训练任务和目标任务之间的差距。值得注意的是,此过程只使用了目标任务的数据和标注,并不需要额外的数据或标注。
此过程分为「混合」与「匹配」两个步骤。在「混合」步骤中,我们从目标任务图像中随机抽样了大量的局部图像块并混合在一起。这些图像块跨越了多张图像,因而能够减弱图像内部的相关性,从而无偏地反映目标图像的分布。由这些图像块组成的大量的三元组也能够为优化提供稳定的梯度。在「匹配」过程中,我们构建了一个无向图,它的节点即图像块的深层特征。它有两种类型的边,如果两个图像块属于同一类,那么我们定义为「相吸边」,反之,则定义为「相斥边」。我们通过迭代的方式构建的图可以确保同类的节点组成一个连通子图,见图三。在此方式构建的图中,我们可以获得更加鲁棒的三元组,能够让网络学会将同类的图像块映射到同一个点上,或者说优化的过程中使得它们的描述子在欧几里得空间中构成单个中心,而非多个中心,并且使得不同类之间具有较大的距离。我们抽样三元组的方式和以往的工作具有非常大的不同。
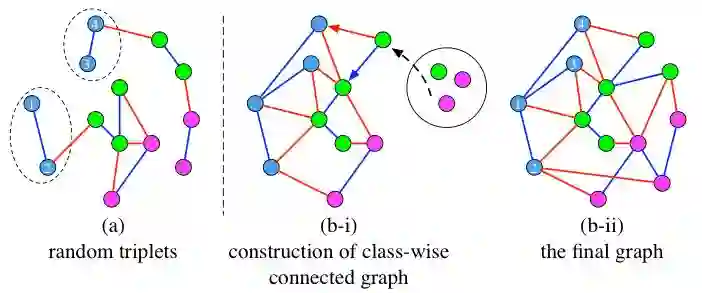
图三:此图展示了不同的构建三元组的方式。节点的颜色代表其类别。蓝色和红色的边分别代表「相吸边」和「相斥边」。(a)是随机选择的三元组(Schroff, Kalenichenko, and Philbin 2015),其中来自相同类的节点不能构成一个连通图。(b-i)和(b-ii)是我们通过构建无向图来构建三元组的方法。我们构建的无向图中,每一类都分别构成一个连通子图。
我们的工作的贡献主要有:1. 我们提出了「混合与匹配」的调节机制,首次让自监督预训练的模型超过了有监督预训练的模型。具体来说,在 PASCAL VOC2012 数据集上,在 VGG-16 网络上,使用图像上色作为预训练任务,我们的方法获得了 64.5% mIoU 的性能,超过了 ImageNet 分类作为预训练任务的模型,64.2%。在 CityScapes 数据集上,我们得到了 66.4% 的性能,匹敌 ImageNet 预训练的结果,67.9%。此提升极具显著性,考虑到我们的方法是基于无监督预训练的。2. 除了利用图像上色作为预训练任务,我们还利用基于图像内容的自监督方法——Jigsaw Puzzles,获得了较大的提升。3. 使用随机初始化,在不同网络结构和不同数据集上,我们的方法也获得了显著的提升。这使得随机初始化训练语义分割成为可能。4. 我们提出的一种新的基于类内连通图的三元组抽样方案,相比于传统的三元组抽样方案更加鲁棒。
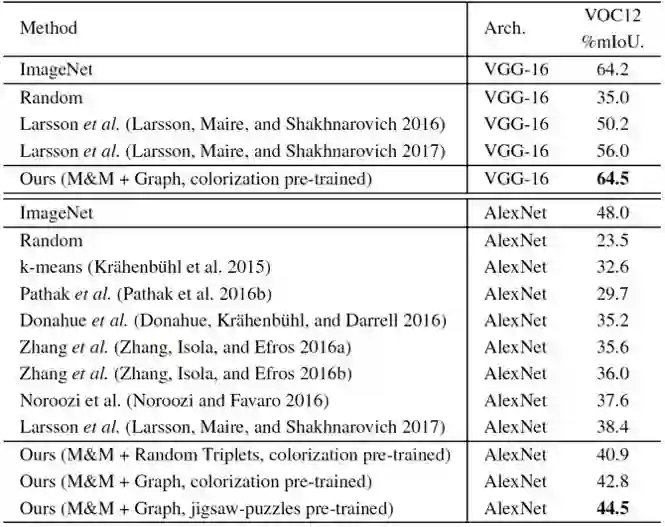
表一:在此数据集是公认的语义分割数据集,PASCAL VOC2012 数据集上的结果对比。我们的方法同时在 VGG-16 和 AlexNet 上大幅度超过了目前最好的基于自监督初始化的方法,并且在 VGG-16 上超过了 ImageNet 初始化的方法。

表二:PASCAL VOC2012 上单类语义分割结果。

图四:此图展示了使用了我们的方法之后,图像特征分布的变化。

表三:此表格展示了不同数据集下,用不同网络结构,和不同预训练任务(包括随机初始化),我们的方法获得的提升效果。

图五:结果可视化。






