ICASSP 2018 | 思必驰和上交大提出口语语义理解新方法:基于对抗多任务学习的半监督训练
机器之心专栏
作者:Ouyu Lan, Su Zhu, Kai Yu
为期 5 天 ICASSP 2018,已于当地时间 4 月 20 日在加拿大卡尔加里(Calgary)正式落下帷幕。ICASSP 全称 International Conference on Acoustics, Speech and Signal Processing(国际声学、语音与信号处理会议),是由 IEEE 主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级学术会议。今年 ICASSP 的大会主题是「Signal Processing and Artificial Intelligence: Challenges and Opportunities」,共收到论文投稿 2830 篇,最终接受论文 1406 篇。其中,思必驰-上海交大智能人机交互联合实验室最终发表论文 14 篇,创国内之最,读者可查阅思必驰专栏了解更多详细的论文。
思必驰专栏:https://www.jiqizhixin.com/topics/042301
论文:Semi-Supervised Training Using Adversarial Multi-Task Learning For Spoken Language Understanding
摘要:口语语义理解(Spoken Language Understanding, SLU)通常需要在收集的数据集上进行人工语义标注。为了更好地将无标注数据用于 SLU 任务,我们提出了一种针对 SLU 半监督训练的对抗对任务学习方法,把一个双向语言模型和语义标注模型结合在一起,这就减轻了对标注数据的依赖性。作为第二目标,双向语言模型被用于从大量未标注数据中学习广泛的无监督知识,从而提高语义标注模型在测试数据上的性能。我们为两个任务构建了一个共享空间,并为每个任务分别构建了独立私有空间。此外,对抗任务判别器也被用于获取更多任务无关的共享信息。在实验中,我们提出的方法在 ATIS 数据集上达到了最好的性能,并在 LARGE 数据集上显著提高了半监督学习性能。我们的模型使得语义标注模型更具一般性,且当标注数据显著多余无标注数据时,半监督学习方法更加有效。
研究背景

口语语义理解模块是目标导向的口语对话系统的重要部分,它把用户的语句解析为对应的语义信息。例如,句子「Show me flights from Boston to New York」可以被解析为 (fromloc.city name=Boston, toloc.city name=New York)。这通常被认为是一个语义槽填充(slot filling)任务,对句子中的每个字都分配一个预先定义的语义标签。在 In/Out/Begin (IOB) 模式下,这个例子可以被表示为:

最近关于 SLU 语义槽填充的研究关注了循环神经网络(RNN)及其扩展,比如长短期记忆网络(LSTM),encoder-decoder 模型等。这些传统的方法需要大量的标注数据,以获得较好的性能。但是由于数据标注的过程需要大量人工成本和时间成本,我们很难得到足够的领域内标注数据。当一个领域扩展或是一个新的领域生成时,只有有限的数据可以被用于监督学习。在近几年移动互联网的发展中,越来越多的口语对话系统应用发布了,比如,苹果 Siri,亚马逊 Alexa,谷歌 Home,微软 Cortana 等。缺少监督数据通常会导致一个局部最优结果。为了减轻这种局限性,半监督学习可以用于有效接触这些未见过的输入数据。
对抗多任务学习
为了更好地利用无标注数据,多任务学习框架把 SLU 模型和语言模型结合在一起。SLU 模型从有限的标注数据中学习监督知识,同时语言模型从大量无标注数据中学习一般无监督知识。如此,语言模型获取的信息可以提高 SLU 模型在测试数据上的性能。下图是应用于语义理解的简单多任务学习框架。其中,蓝色的部分为语言模型,来学习一般语言信息,虚线部分为双向语言模型所有的额外的反向语言模型;绿色的部分为 SLU 模型,来学习监督知识;黄色的部分为两个共享的空间。这两个框架分别完全分离或共享隐层空间。
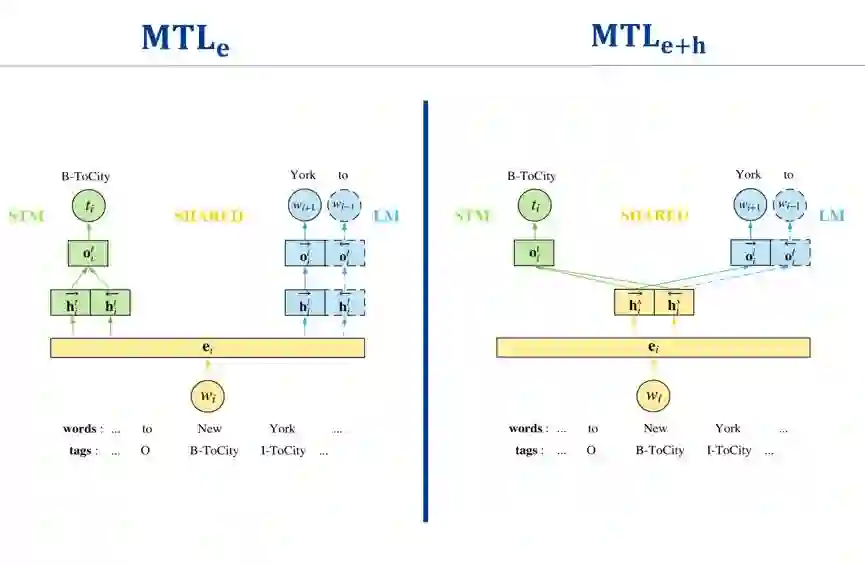
我们提出了另一种高效的多任务学习方法,共享-私有模型(shared-private model,SPM),它可以更好地改善并泛化 SLU 模型。具体地说,SLU 模型和语言模型通过一个共享空间和两个任务独立的私有空间结合在一起。此外,我们还研究了一个对抗任务判别器,作为共享隐层空间的竞争对手。任务判别器的目标是要判别共享特征是为哪个任务服务的。为了混淆任务判别器,共享空间会被驱使保存任务无关信息。任务判别器可应用于字层面或句层面,也就是说,为每个字或每句话预测任务指示的可能性。
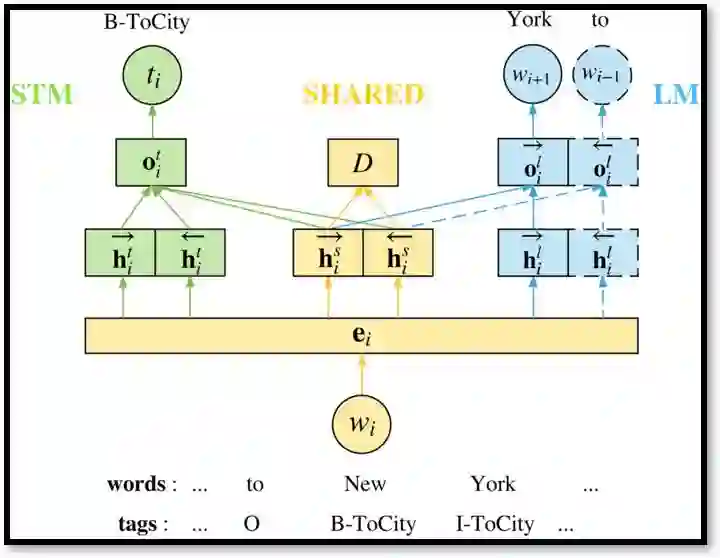
在这个模型中,第一步是把当前字 wi 映射为词向量 ei。三个隐层空间都应用 BLSTM 网络。每个 LSTM 输入前一时间的隐层状态和当前时间的词向量。任务特有的输出层估计正确标签的可能性。然后,模型可以通过最小化预测分布 oi 和真实标签的交叉熵损失来进行训练。任务判别器输入共享特征,并预测输入的训练目标任务。
实验
我们首先在 ATIS 数据集上评测提出的模型。然后在一个大规模数据集中,我们选取了不同数据量的标注语句,评测模型的半监督学习方法的有效性。实验结果表明,我们的模型在语义槽填充任务中,与传统半监督学习方法有显著提升。
ATIS 包含了一个航空领域内的 4,978 句训练数据和 893 句测试数据。不同的语义标签数有 84 个(如果算上 IOB 前缀有 127 个)。我们随机在训练数据中选取 80% 作为训练集,剩余 20% 作为验证集。不同方法测试结果如表 1 所示:

其中,双向共享-私有模型和字层面判别器取得了最好的性能,即 95.94%。之前最好的结果是由 Zhai 等提出的结果,即 95.86%。此外,配有双向语言模型的框架大多都比其对应的配有单向语言模型的框架性能更好。这意味着,同时考虑上下文信息对获取语义槽标注的泛化特征十分有帮助。
考虑到 ATIS 数据量的有限性和构建一个在多个领域上语义槽模型的必要性,我们跟随 Kurata 的工作,把 MIT Restaurant,MIT Movie 和 ATIS 数据集合并为一个大规模的数据集,记为 LARGE。这个合并的数据集包含了在三个不同领域中 30229 条训练语句和 6810 条测试语句。这些字被分配到 116 个不同的语义槽标签上(算上 IOB 前缀有 191 个)。对于半监督学习,「5k,10k,15k」条训练语句被随机选为标注数据,剩余的训练语句则为未标注数据。对于每个标注数据集,我们随机选取 80% 作为训练集,剩余 20% 作为校验集。其结果如表 2 所示。
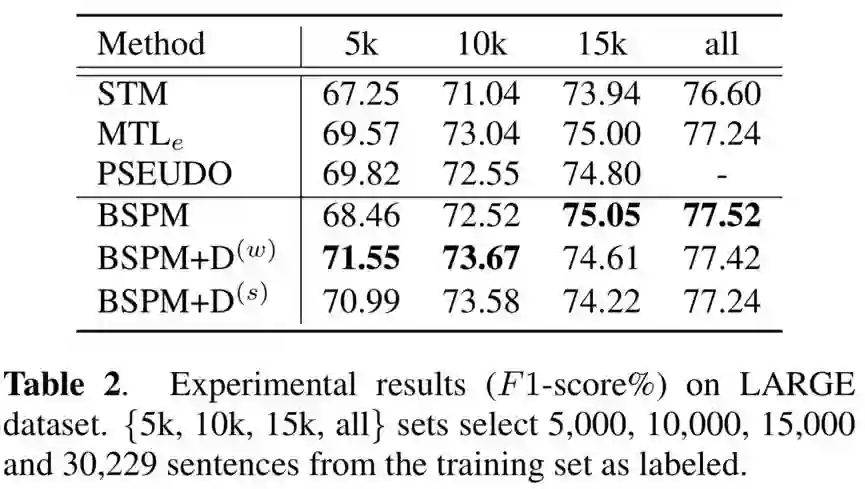
我们可以看到,提出的 BSPM 和 BSPM+D 始终比其他方法取得更好的性能结果。在全部数据集上,与传统 STM 相比,我们的方法显著提高(显著性水平 99.9%)。与简单多任务模型 MTLe 相比,我们的方法在 5k 数据集上有 99.9% 的显著性提升,在 10k 数据集上有 99.5% 的显著性提升。但是,这在 15k 数据集上的提升并不显著。相似地,与 PSEUDO 方法相比,提出的方法在 5k 和 10k 数据集有显著提升(99.8%),而在 15k 数据集上的提升并不显著(但也大于 95%)。
实验表明,当标注数据有限而无标注数据十分充足时,我们的半监督学习模型要更加有效。当语言模型学习无监督知识时,共享-私有框架和对抗训练使得语义标注模型泛化,在未见过的数据上表现更好。
结论
在这篇论文中,我们提出了一种针对 SLU 半监督训练的对抗对任务学习方法,这减轻了对标注数据的依赖性。在实验中,我们提出的方法在 ATIS 数据集上达到了最好的性能,并在 LARGE 数据集上显著提高了半监督学习性能。我们的模型使得语义标注模型更具一般性,且当标注数据显著多余无标注数据时,半监督学习方法更加有效。
点击阅读原文查看思必驰 ICASSP 2018 专栏。
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




