学界 | 结合主动学习与迁移学习:让医学图像标注工作量减少一半
选自arXiv
作者:Zongwei Zhou, Jae Y. Shin, Suryakanth R. Gurudu, Michael B. Gotway, 梁建明
机器之心编译
参与:Panda
和普通图像的标注不一样,生物医学图像的标注需要有专业知识和技能的人来做,因此难以获得大型的有标注数据集供卷积神经网络学习。近日,IEEE 一篇论文提出可以将主动学习和迁移学习结合起来降低标注任务的工作量,实验结果也证明了这种方法的有效性。机器之心对该论文进行了编译介绍,详细的数学过程和结果分析请参阅原论文。
在 ImageNet 和 Places 等大规模有标注数据集的帮助下,卷积神经网络(CNN)已经为计算机视觉领域带来了革命性的发展。正如 IEEE TMI 专刊 [4] 和最近的两本书 [5,6] 谈到的那样,人们对在生物医学图像分析中应用 CNN 有着广泛且浓厚的兴趣;但由于生物医学领域缺乏如此大量的有标注数据集,所以 CNN 在这一领域的成功之路还有所阻碍。标注生物医学图像不仅耗时耗力,而且需要高成本的、特定专业的知识和技能,这些都不易取得。因此,我们希望解答这个重要问题:如何显著降低将 CNN 应用于生物医学图像的标注成本;另外我们也想解答一个附属问题:给定一个有标签数据集,如何确定它充分覆盖了不同的相关对象。为此,我们提出了一种名为 AFT* 的全新方法,可以自然地将主动学习(active learning)和迁移学习(transfer learning)整合成单一一个框架。我们的 AFT* 方法首先会使用一个预训练 CNN 来寻找未标注数据中的「显著」样本来进行标注,然后这个(经过微调的)的 CNN 会根据新标注的样本以及所有误分类的样本而持续得到调整改进。我们在三种不同的应用上评估了我们的方法,其中包括结肠镜检查帧分类、息肉检测和肺栓塞(PE)检测;结果表明标注成本至少可以减少一半。
这种出色表现主要得益于一个简单而又强大的观察结果:为了提升 CNN 在生物医学图像上的表现,通常会通过数据增强方法为每个候选数据自动生成多个图块(patch);这些根据同一候选数据生成的图块具有同样的标签,所以当它们被放入训练集中时,自然能够预见当前 CNN 会为它们给出相似的预测结果。因此,它们的熵和多样性能提供有关候选数据的「能力」的有用指标,从而可帮助提升当前 CNN 的表现。但是,自动数据增强无可避免地会为某些候选数据生成「困难的」样本,注入有噪声的标签;因此,为了显著增强我们的方法的稳健性,我们会根据当前 CNN 的预测结果,通过选择每个候选数据的一小部分图块来计算熵和多样性。

算法 1:AFT*——使用混合数据进行主动且持续的微调
有些研究已经表明对生物医学图像分析 CNN 进行微调是有用的,但这些研究只执行了一次微调,也就是说,只使用所有可用的训练样本对预训练的 CNN 进行一次微调,而不涉及任何主动选择过程。就我们所知,我们提出的方法是首次以连续的方式将主动学习整合到 CNN 的微调中,可以使 CNN 对生物医学图像分析更加友好,实现极大降低标注成本的目标。算法 1 给出了我们的方法的概览;与传统的主动学习相比,我们的方法有 8 项优势:
从全空的有标签数据集开始,不需要任何初始的有标签候选数据;
通过持续的微调而非反复的再训练来逐步提升学习器的表现;
通过自然地利用每个候选数据中图块之间的预期一致性来主动选择信息最丰富和最有代表性的候选数据;
在每个候选数据中的少量图块上局部地计算选择标准,从而能节省可观的计算时间;
通过多数选择(majority selection)自动处理有噪声标签;
自动平衡不同类的训练样本;
将新选择的候选数据与误分类的候选数据结合到一起,去除简单样本以提升训练效率,重点关注困难样本以防止灾难性遗忘(catastrophic forgetting);
将随机性纳入主动选择过程,以在探索(exploration)和利用(exploration)之间达到接近最优的平衡。
更重要的是,我们的方法有望对使用生物医学成像的计算辅助诊断(CAD)产生重要影响,因为当前法规要求 CAD 系统必须部署在「封闭」环境中,其中所有的 CAD 结果都要经过放射科医生的检查,如有错误就会得到纠正;由此,所有的假正例结果都应该被移除,所有的假负例结果都应该补充上来,这是一种即时的在线反馈,也许能让 CAD 系统能够具备自我学习能力并且可能能在我们的方法的持续性微调能力的帮助下在部署之后继续改进。
3 我们提出的方法
AFT* 是在生物医学成像计算机辅助诊断(CAD)的背景下设计的。CAD 系统通常有一个候选数据生成器,可以快速生成一个候选数据集合,其中有些是真正例,有些是假正例。在生成候选数据之后,任务目标是训练一个分类器来尽可能地去除假正例结果同时尽可能地保留真正例结果。为了训练分类器,必须对每个候选数据进行标注。我们假设每个候选数据都要取多个可能标签中的一个。为了提升用于 CAD 系统的 CNN 的表现,通常要通过数据增强为每个候选数据自动生成多个图块;这些根据同一候选数据生成的图块会继承该候选数据的标签。换句话说,所有标签都是在候选数据层面上获取的。
但是,AFT* 是通用型的,可以应用于计算机视觉和图像分析领域中的很多任务。为了说明清楚,我们将使用 Places 数据库在自然图像中的场景解读任务上阐述 AFT* 背后的思想,其中不需要候选数据生成器,因为每张图像都可以直接被当作是候选数据。为了说明简单同时不失一般性,我们将其限制到了 3 种类别(厨房、客厅和办公室),并且将每一类中的 Places 图像都分成了训练集(14 000 张图像)、验证集(1000 张图像)和测试集(100 张图像),这三个子集之间没有重叠。
设计主动学习算法涉及两个关键问题:(1)如何确定一个标注候选数据的「价值度(worthiness)」;(2)如何更新分类器/学习器。
3.1 主动候选数据选择
图 3 给出了用于多类分类的主动候选数据选择过程,同时为了便于理解,表 1 用二元分类情况对其进行了阐述。如表 1 第 1 行所示,二元分类情况有 7 种典型预测模式。

图 3:在第 10 步时(经过了 3000 个图像标签查询后),两张图像(A 和 B)以及由 CNN 在主导类别上根据预测结果列出的增强后的图像图块。
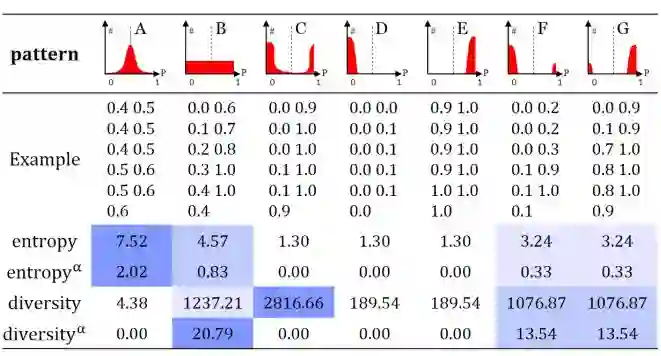
表 1:主动候选数据选择的 7 种预测模式和 4 种方法之间的关系。
3.2 寻找有价值的候选数据
主动学习的关键是开发用于确定标注候选数据「价值度」的指标。我们的标准基于一个简单而强大的观察结果:所有根据同一候选数据增强得到的图块都具有同样的标签;预计当前 CNN 对它们的预测也相似。因此,它们的熵和多样性能提供有关候选数据的「能力」的有用指标,从而可帮助提升当前 CNN 的表现。直观上讲,熵代表了分类的确定性——更高的不确定性值表示更高程度的信息(比如,表 1 中的模式 A);而多样性是指在一个候选数据的多个图块上所得到的预测的一致性——多样性值更高说明预测不一致性程度更高(比如,表 1 中的模式 C)。
3.3 通过多数选择处理噪声标签
自动数据增强对提升 CNN 的表现而言至关重要,但却无可避免地会为某些候选数据生成「困难的」样本(如图 4(c) 所示),注入有噪声的标签;因此,为了显著增强我们的方法的稳健性,我们会根据当前 CNN 的预测结果,通过选择每个候选数据的一小部分图块来计算熵和多样性。
3.4 将随机性注入主动选择
如 [41] 中讨论的那样,简单的随机选择在一开始时的表现可能优于主动选择,因为主动选择依赖于当前模型来选择用于标注的范例;因此,在早期阶段做出的糟糕选择可能会对后续选择的质量造成不良影响;而随机选择则更不易受到糟糕假设的约束。也就是说,主动选择重在利用从已获得的标签中取得的知识以探索决策边界,而随机选择则重在探索,所以能够定位到特征空间中分类器表现糟糕的区域。因此,有效的主动学习策略必须找到探索和利用之间的平衡。为此,我们通过根据采样概率主动选择而向我们的方法中注入了随机性。
3.5 比较多种学习策略
根据上面的讨论,可以推导出几种主动学习策略,如表 2 所示。我们对这些策略进行了全面的比较,结果表明:(1)AFT' 不稳定;(2)AFT'' 需要仔细调整参数;(3)AFT 与 AFT' 和 AFT'' 相比是最可靠的,但需要在每一步使用所有目前可用的有标注样本从一开始就对原始模型进行微调。为了克服这个短板,我们开发了一种优化版本 AFT*,可以使用新标注的候选数据以及被误分类的候选数据来持续优化当前模型。有些研究者已经证明微调能带来更好的表现,而且比从头开始训练更加稳健。此外,我们的实验表明 AFT* 的收敛速度比反复微调原来的预训练的 CNN 更快,从而可以节省训练时间;AFT* 还能通过去除简单样本,重点关注困难样本,防止灾难性遗忘来提升性能。

表 2:主动学习策略
图 2(a) 比较了使用 Places 数据库的 AFT* 和 RFT。RFT 通过系统性的随机采样生成了 6 个不同的序列。最后的曲线是根据 6 次运行的平均结果绘制的。如图 2(a) 所示,在 AUC(曲线下面积)方面,仅使用了 2906 个候选数据查询的 AFT* 可以实现使用了 4452 个候选数据查询的 RFT 的表现;同时 AFT* 仅使用 1176 个候选数据查询就能实现使用全部 42000 个候选数据的完全训练(full training)的表现。因此,AFT* 相比于 RFT 能节省 34.7% 的标注成本,相比于完全训练能节省 97.2% 的标注成本。当使用了大约 100% 的训练数据时,其表现仍然在继续增长;因此,考虑到 GoogLeNet 架构有 22 层,所以这个数据集的大小还是不够。AFT* 是一种通用算法,不仅可用于生物医学数据集,而且也能用于其它数据集;AFT* 可用于有很多类别的问题。
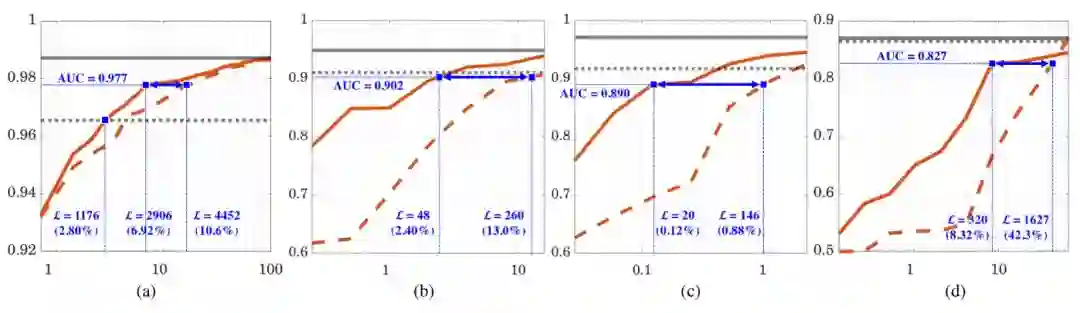
图 2
4 应用
我们将我们的 AFT 和 AFT* 方法应用到了三种应用上,包括结肠镜检查帧分类、息肉检测和肺栓塞(PE)检测。
4.1 结肠镜检查帧分类
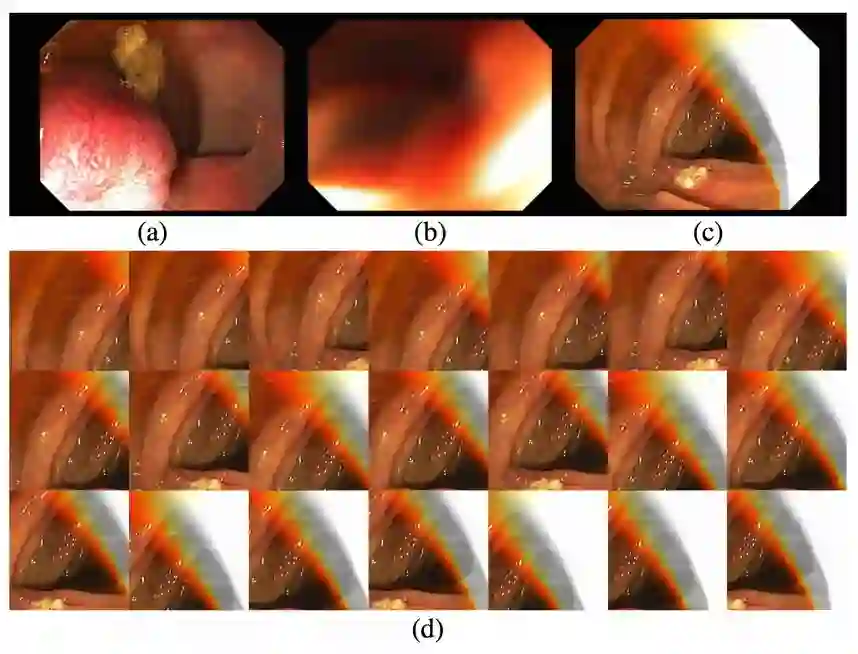
图 4:三种结肠镜检查示例:(a)有信息的、(b)无信息的、(c)不明确但标记为「有信息的」——因为专家根据整体质量标注帧:如果某帧(即该应用中的候选数据)中有超过 75% 是清晰的,那么就认为它是有信息的。因此,不明确的候选数据中同时包含清楚和模糊的部分,并且会根据自动数据增强生成图块层面的噪声标签。比如帧(c)整个都被标注为「有信息的」,但并非与该帧相关的所有图块(d)都是「有信息的」,尽管它们都继承了「有信息的」标签。这是我们的 AFT* 方法中使用多数选择的主要动机。
4.2 息肉检测
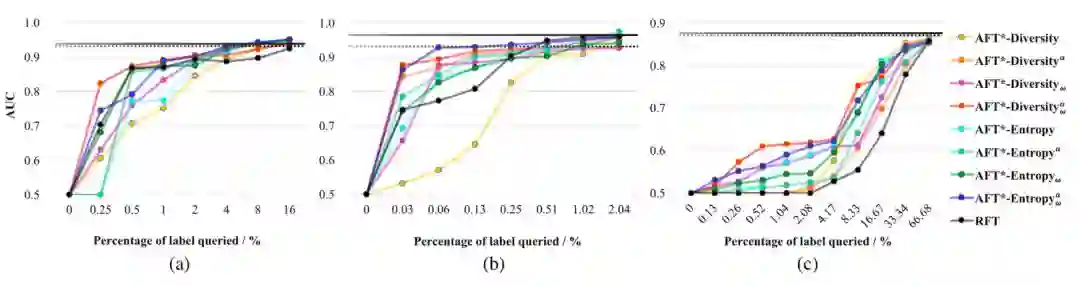
图 5:使用 AlexNet 在测试数据集上比较用于 3 种医学应用的 8 种主动选择策略。(a)结肠镜检查帧分类、(b)息肉检测和(c)肺栓塞检测。黑色实线是使用了全部训练数据的微调方法的当前最佳表现,黑色虚线是使用全部训练数据从头开始训练的表现。
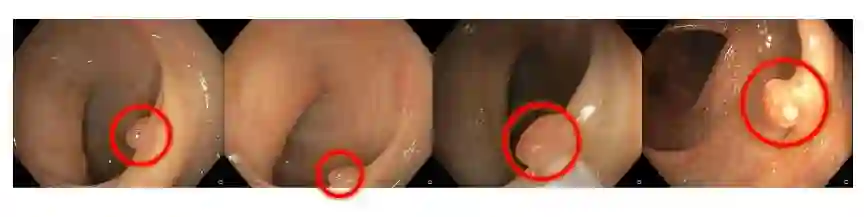
图 6:结肠镜检查视频中具有不同形状和外观的息肉。
4.3 肺栓塞检测
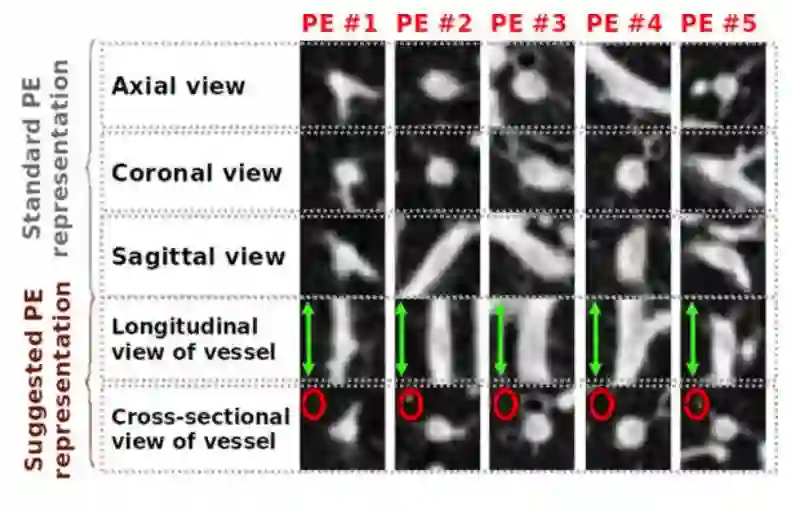
图 7:用标准 3 通道表示以及 2 通道表示 [56] 得到的 5 种不同的 PE 图像,本研究使用它的原因是能实现更好的分类准确度和加速 CNN 训练的收敛。
4.4 比较所有方法
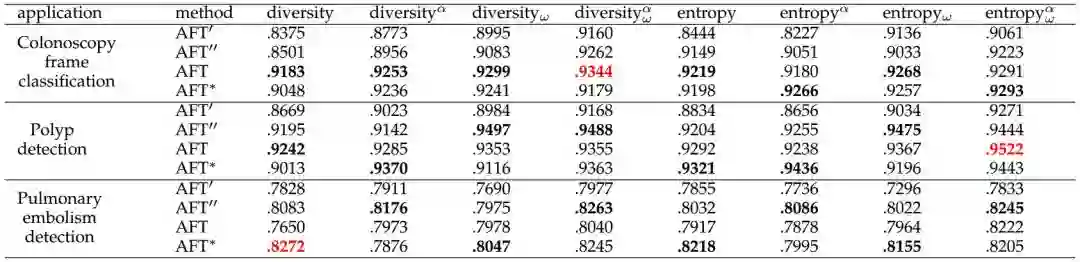
表 3:所有方法的比较。结肠镜检查帧分类的基准表现是 RFT(ALC=.8991),息肉检测的基准表现是 RFT(ALC=.9379)和肺栓塞(PE)检测的基准表现是 RFT(ALC=.7874),使用的都是 AlexNet。加粗的值是其中表现最好的使用了特定主动选择标准的学习策略(见表 2),红色的值是同时使用了两种学习策略和主动选择标准所得到的最佳表现。
4.5 在所选模式上的观察结果
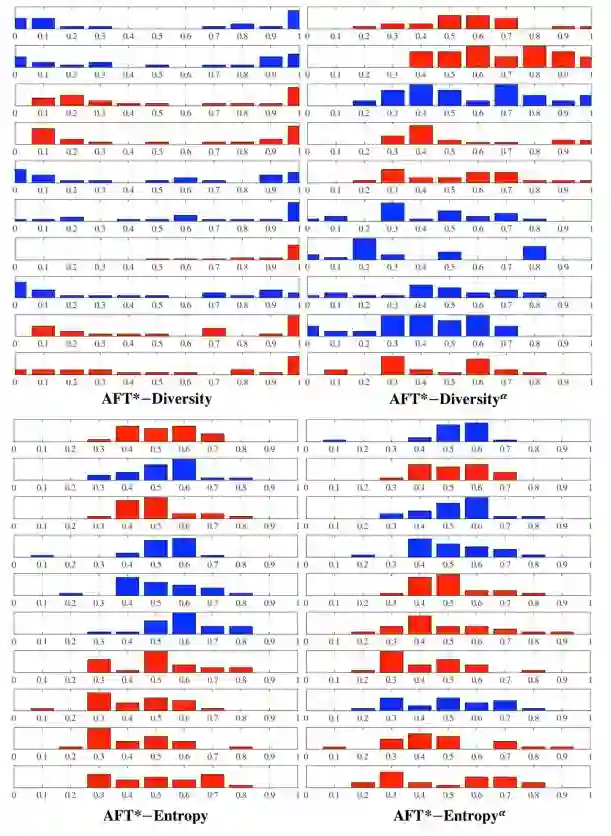
图 8:在结肠镜检查帧分类的第 3 步通过 4 种 AFT* 方法选择出的前 10 个候选数据。正例候选数据用红色表示,负例候选数据用蓝色表示。
4.6 正例-负例比例的自动平衡
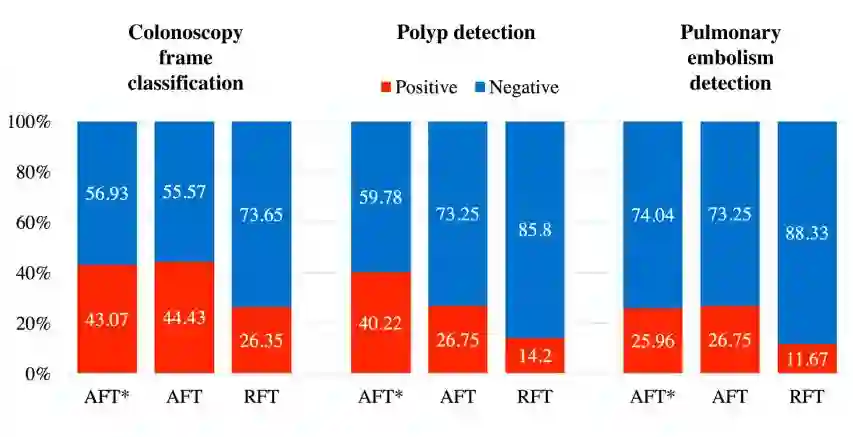
图 9:AFT*、AFT 和 RFT 所选择的候选数据中的正例-负例比例。注意,RFT 的比例大致能代表整个数据集的比例。
4.7 AFT* 在 CNN 架构中的泛化性
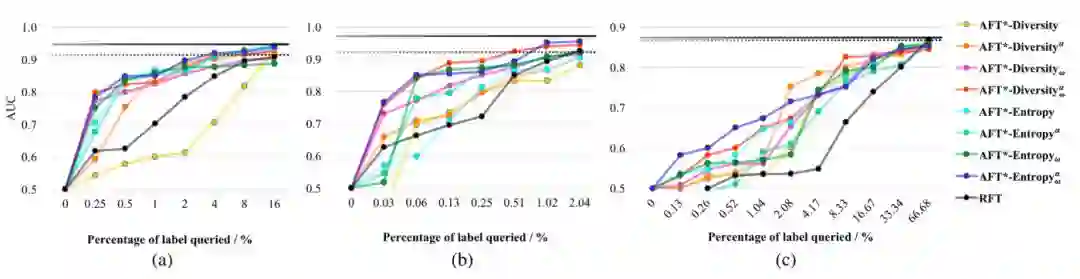
图 10:基于三种应用,在 GoogLeNet 上比较 AFT* 和 AFT 的表现。(a)结肠镜检查帧分类、(b)息肉检测和(c)肺栓塞检测。结果表现出了与 AlexNet(见图 5)一样的模式。
AFT*:整合主动学习与迁移学习以减少标注工作(Integrating Active Learning and Transfer Learning to Reduce Annotation Efforts)

论文地址:https://arxiv.org/abs/1802.00912
卷积神经网络(CNN)在计算机视觉领域的辉煌成功很大程度上可以归功于大型有标注数据集的可用性,比如 ImageNet 和 Places。但是,在生物医学成像领域,创建如此大型的有标注数据集是非常艰难的,因为标注生物医学图像不仅枯燥费力和费时,而且需要高成本的专业技能,这并不容易取得。为了大幅降低标注成本,本论文提出了一种用于将主动学习和迁移学习(微调)自然地整合成一个单一框架的全新方法 AFT*。该方法首先是使用一个预训练的 CNN 来为标注寻找「有价值的」样本,然后通过持续性的微调来增强(微调过的)CNN。我们在三种不同的生物医学成像应用中评估了我们的方法,结果表明与之前最佳的方法相比,这至少可以降低一半的成本。这种表现得益于我们方法的先进的主动连续学习能力的多种优势。尽管 AFT* 最初是在生物医学成像中的计算机辅助诊断背景中设计的,但这种方法是通用的,可用于计算机视觉和图像分析中的很多任务;我们使用 Places 数据库在自然图像的场景解读任务上阐释 AFT* 背后的关键思想。

注:据机器之心了解,本文作者之一梁建明是AI医疗创业公司体素科技的研究开发副总裁,美国亚利桑那州立大学(ASU)副教授,美国梅奥医学中心首届入驻教授,发表了超过70篇论文并获得13项专利。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




