预训练卷不动,可以卷输入预处理啊!

文 | 德志
编 | 小戏
目前伴随着预训练预言模型的兴起,越来越多的 NLP 任务开始脱离对分词的依赖。通过 Fine-Tune Bert 这类预训练预言模型,能直接在下游任务上取得一个很好的结果。同时也有文章探讨中文分词在神经网络时代的必要性。对于分词任务本身也是如此。
那中文分词这个任务有还意义吗?或者换句话说中文分词是不是一个已经解决的任务。那么接下来笔者将会带大家梳理目前分词的研究方向和进展。
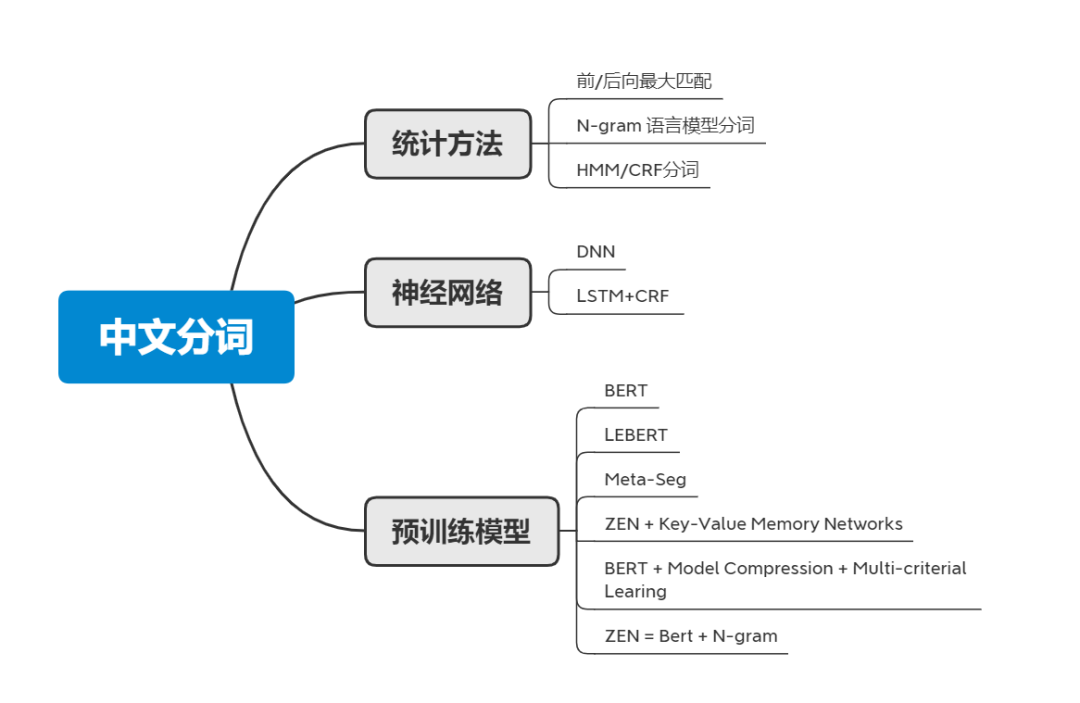
本文的思维导图如下图所示。其中,“统计方法”和“神经网络”两部分会简单介绍一下早期的传统做法,熟悉的同学可以直接跳过。主体在最后的“预训练模型”部分,会带大家梳理一下2020年以来的最前沿的一些中文分词工作。
![]() 任务描述
任务描述![]()
 任务描述
任务描述分词任务相信大家都不陌生了,其实就是给定一个句子,让后将一个句子切分成一个个的基本词。
例如:'上海浦东开发与建设同步' → ['上海', '浦东', '开发', ‘与', ’建设', '同步']。
对这个任务的解法也有很多中,比如最开始的前/后向最大匹配,后来的也有 N-gram语言模型 ,HMM/CRF 的分词方法,再到现在的基于深度学习的端到端的分词方法。总而言之,分词的方法也是跟着时代是在不断进步的。
![]() 前浪们:统计方法
前浪们:统计方法![]()
对于分词这项任务最早的方案是依靠词典匹配的方式,到后来利用统计信息进行分词,最后采用了序列标注的方案进行分词。这些方案的代表方法有:
-
前/后向最大匹配:其朴素思想就是利用词表采用贪心的方式切分出当前位置上长度最大的词作为分词结果返回。 -
N-gram 语言模型分词:其思想在于利用统计信息找出一条概率最大的路径。一般需要很大量的数据才能统计的很准。 -
HMM/CRF分词:把分词当做一个序列标注问题。序列单元是字,序列标签有B,M,E,S,分别代表词首,词中,词尾和单词。
前浪们的方法就不赘述太多了,这些方式都或多或少存在一定的局限性,当然,这些方法显著的优势是它们速度都很快。
![]() 中浪们:神经网络
中浪们:神经网络![]()
步入到深度学习时代,开始涌现出形形色色利用神经网络的分词方式。一个朴素的方案是,给定一个中文的句子, ,输出的一个 Label 序列 。
Label 序列是由{B,M,E,S}组成。其中,B 为词的开头,M 代表词的中间,E 为词的结尾,S 指的是单字。这种方案首先将句子切分成单字输入到模型中,通过序列标注的形式进行学习。
之后,中浪们开始采用了各种模型去提取字符特征,然后利用 CRF 进行序列标注的学习。比较典型的方案是 LSTM+CRF 的方式。
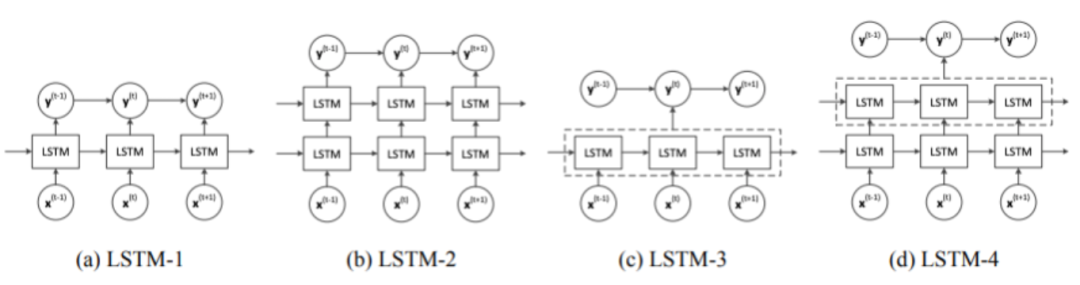
LSTM 的优势在于能够保留之前的有效信息,以及减少窗口的限制。对比传统方法而言,基于 NN 的方法效果好且对于歧义词和未登陆词有优势,虽然在速度上不如传统模型。
![]() 后浪们:预训练时代
后浪们:预训练时代![]()
后 BERT 时代。在 BERT 出现之后,分词任务也涌向利用 BERT 这种预训练预言模型进行分词。BERT 作为强特征抽取器,直接运用到分词任务上可以看到极大的提升。一个典型的方式如下:
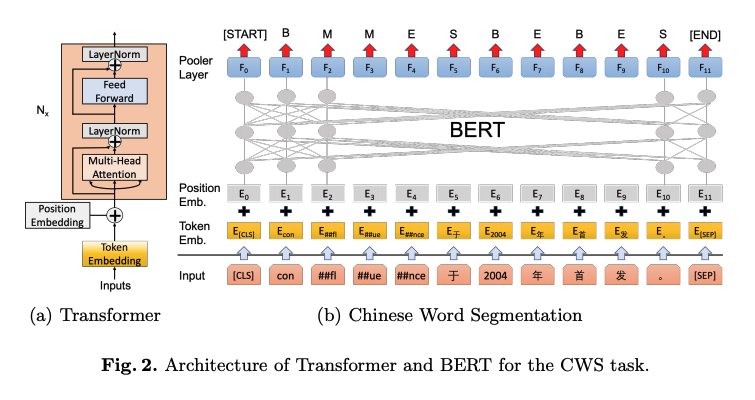
此时可能大家就会有一个疑问:是不是对于分词任务,使用一个 BERT 就好了,还有什么可以研究的方向吗?而我个人总结有如下几个研究方向。
-
如何通过不同粒度标准的分词预料联合预训练,让分词能够通过某些简单的控制能够适应不用的分词场景? -
如何在 NN 模型中融合自定义词典的功能?比如输入时融入额外的 Embedding; -
如何将 NN 分词框架和外部知识结合?比如如何结合外部的字典树等问题; -
如何大的 NN 模型蒸馏成一个小的模型?即如何将大的 BERT → 小的 CNN/LSTM/BERT?由于分词模型的场景对性能要求很高,因此把深度模型的速度提升是目前急需解决的问题。
对于以上的几个热门方向分别有如下代表方案:
LEBERT(2021 ACL)
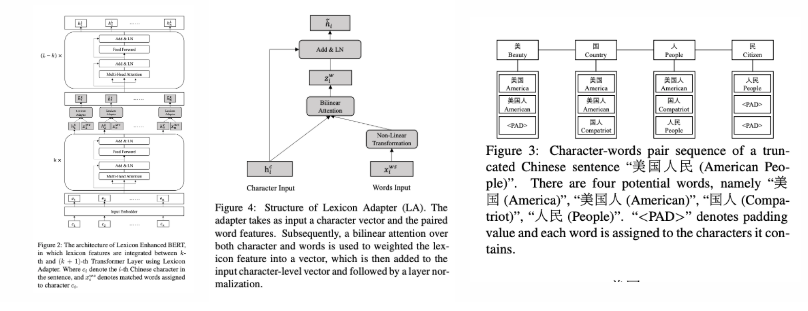
LEBERT 的主要的方案是在输入的时候需要采集句子中的字符-词语 pair ,通过词典匹配(字典树)——这个词典是由预训练的 Word-Embeding 的词组成的——然后通过 Lexicon Adapter 往 BERT 中注入词特征。采用字向量+加权求和得到融合后的词向量。词向量本身是通过额外训练的。
通过下图可以明显的看到整个 LEBERT 的整体结构。给定一个句子[美国人民],对于每个句子中的字都会有一个字符-短语的 pair,"美"->[美国,美国人,<pad>],<pad>是为了对齐。
然后在求和的时候作者设计了 Lexicon Adapter 对字向量和短语 pair 的词向量进行求和,剩下的就和原生 BERT 一致了。额外的 Word-Embeding 则是采用了腾讯 AI-Lab 开源的词向量。
论文题目:
Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter
论文链接:
https://arxiv.org/pdf/2105.07148.pdf
Meta-Seg(2021 NAACL)
Meta-Seg 构建了第一个多粒度的分词预训练语言模型。并通过元学习的方式进行多粒度的预训练。其衍生的姊妹篇文章则是通过引入 Bigram+额外的损失函数来构建多粒度的分词。共同的做法是输入端增加
论文题目:
Pre-training with Meta Learning for Chinese Word Segmentation
论文链接:
https://arxiv.org/pdf/2010.12272.pdf
ZEN + Key-Value Memory Networks(2020 ACL)
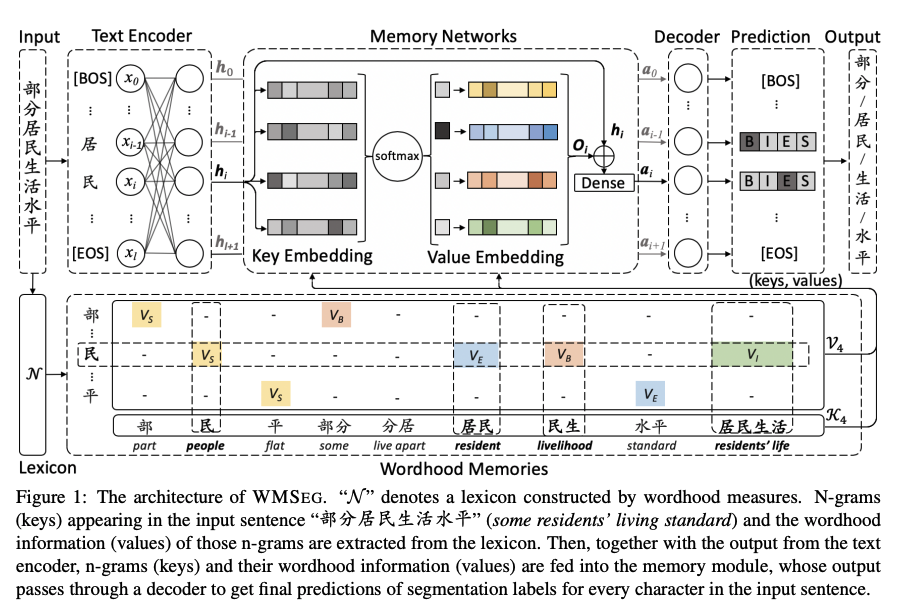
ZEN + Key-Value Memory Networks一文的核心思想是在传统的 CWS 模型上加入 Memory Networks 缓解OOV的问题。
Encoder 可以是任意的网络(BERT/ZEN),Decoder部分则是 Softmax 或者 CRF 。核心是 Wordhood Memory Networks。
Wordhood Memory Networks 可以认为是一种 Key-Value 的存储结构。该方法的核心在于首先构建一个 N-gram 的词表。然后对于每一汉字而言,所有得到所有包含该字的 N-gram 作为Key,Value则是同样的一个列表,表示的是字在 N-gram 中的位置。
给定一个词“民”, Memory 的 Key 为[民,居民。民生,居民生活],Value则是[S,E,B,I],分别代表了“民”在 N-gram 中的位置。然后用民的 Embeding 对 N-gram 的词进行点乘取 Softmax 就得到相关性。
论文题目:
Improving Chinese Word Segmentation with Wordhood Memory Networks
论文链接:
https://aclanthology.org/2020.acl-main.734v2.pdf
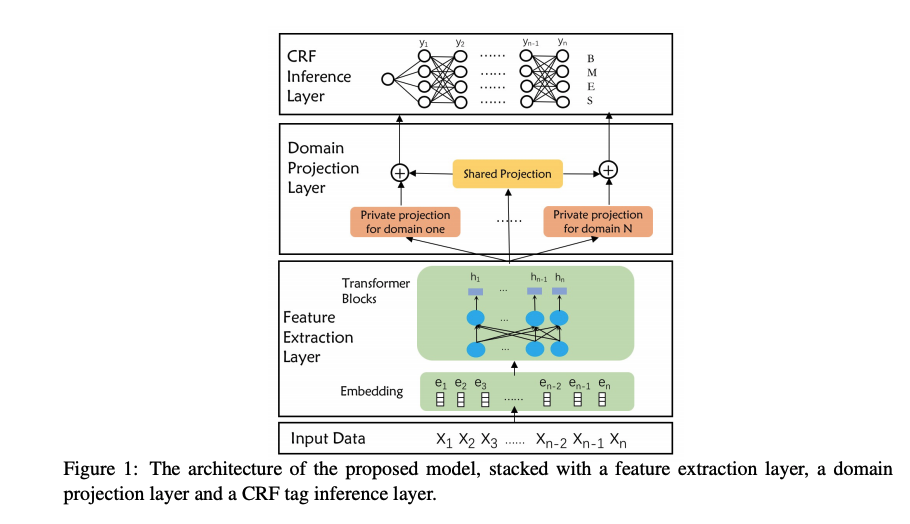
BERT + Model Compression + Multi-criterial Learing(2020 COLING)
BERT + Model Compression + Multi-criterial Learing 的想法非常简单粗暴,由于分词标注的主观性导致了现有数据集在分词粒度上会有分歧,所以想利用某种方式捕获粒度不同且能够利用共同基础知识。
方案很简单,构建一个共有的影层学习共有知识,构建一个私有隐层破获独特性,然后将两个层的结果加起来进行标签预测。而模型压缩这块还是使用了蒸馏的方式,蒸馏了一个 3 层的小 BERT 。Student 的学习是通过 Teacher-Students 损失+标签损失学习。
论文题目:
Unified Multi-Criteria Chinese Word Segmentation with BERT
论文链接:
https://arxiv.org/pdf/2004.05808.pdf
ZEN = Bert + N-gram(2020 EMNLP)
ZEN = Bert + N-gram 引入 N-gram 编码方式,方便模型识别出可能的字的组合。N-gram 的提取分成两步,首先通过语料生成 N-gram 词表,然后通过此表生成 N-gram Matrix。
N-gram Embedding 的方式则是和 BERT 的 Embeeding 一致。字 Embedding 和 N-gram Embedding 的结合方式则是直接做了矩阵相加。
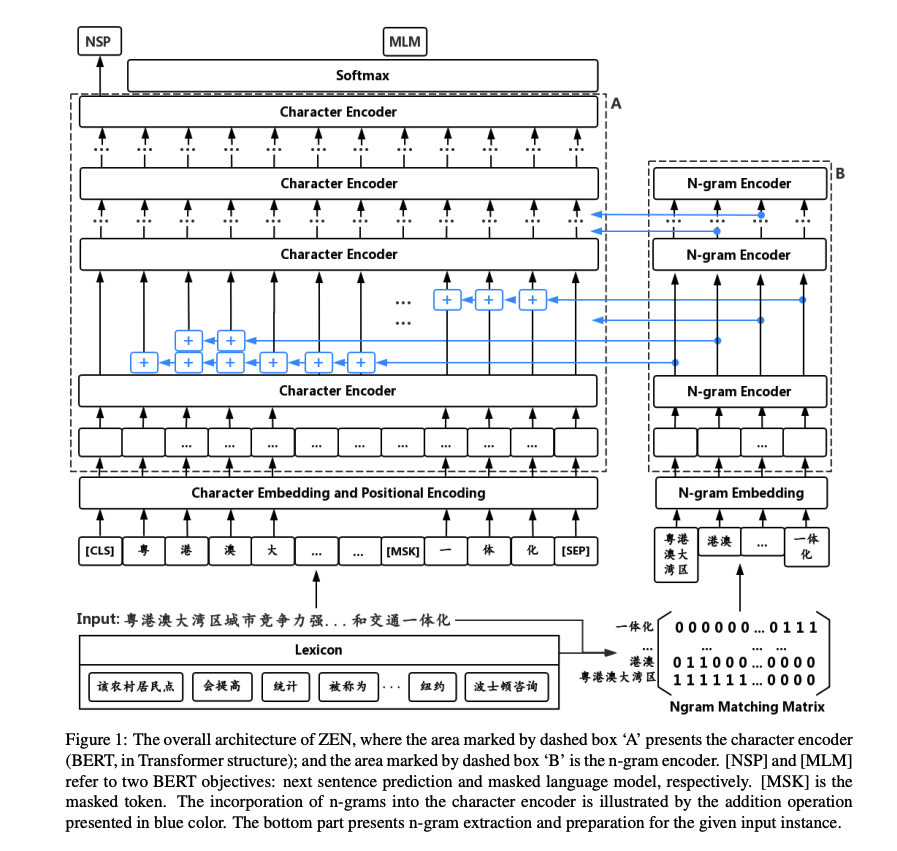
论文题目:
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations
论文链接:
https://arxiv.org/pdf/1911.00720.pdf
![]() 目前 SOTA 排行
目前 SOTA 排行![]()
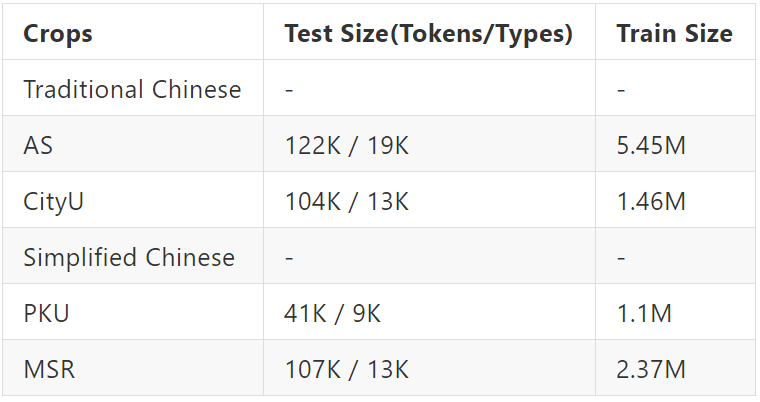
常用的数据集
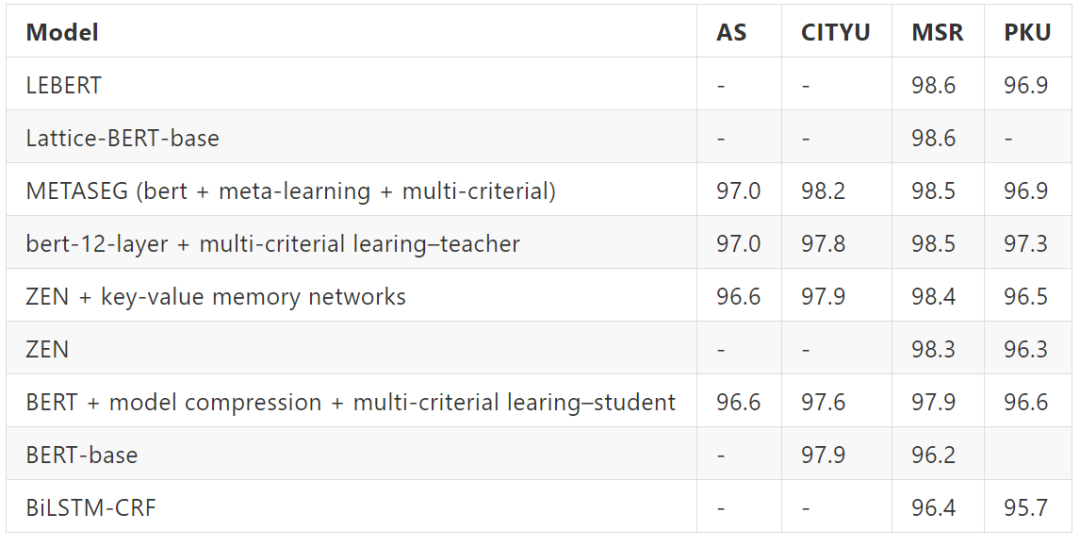
采用 F1 的评价标准
![]() 总结
总结![]()
本文回顾了分词的发展历程,以及目前的研究热点方向。总的来说分词任务其实发展至今可以看到在公开数据集上已经有了很好的效果,但是在实际运用上切词的效果总是没那么让人满意。其主要问题有:
-
实际使用上用户比较关注效率问题,比如如何提升 NN 模型的效率? -
每天有大量的新词产生,对于 OOV 的问题如何更有效的解决? -
词的界限不明确,大家对分词的标准不统一。
这三点导致了目前实际使用中分词效果大大折扣。未来分词还有很多方向需要大家探索,在 RethinkCWS 一文中也有很多对中文分词的目前看法,感兴趣的大家可以去参考查阅一下。
论文题目:
RethinkCWS: Is Chinese Word Segmentation a Solved Task?
论文链接:
https://arxiv.org/pdf/2011.06858.pdf
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter
[2] Lattice-BERT:Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Model
[3] Pre-training with Meta Learning for Chinese Word Segmentation
[4] Unified Multi-Criteria Chinese Word Segmentation with BERT
[5] Improving Chinese Word Segmentation with Wordhood Memory Networks
[6] Toward Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning
[7] ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations.
[8] A Concise Model for Multi-Criteria Chinese Word Segmentation with Transformer Encoder
[9] RethinkCWS: Is Chinese Word Segmentation a Solved Task?
[10] Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
[11] Subword Encoding in Lattice LSTM for Chinese Word Segmentation Lattice LSTM-CRF + BPE subword embeddings
[12] State-of-the-art Chinese Word Segmentation with Bi-LSTMs
[13] Neural Networks Incorporating Dictionaries for Chinese Word Segmentation.
[14] Adversarial Multi-Criteria Learning for Chinese Word Segmentation
[15] Long Short-Term Memory Neural Networks for Chinese Word Segmentation BiLSTM-CRF
[16] Ambiguity Resolution in Chinese Word Segmentation
[17] 中文分词十年回顾
[18] 中文分词十年又回顾
 后台回复关键词【
后台回复关键词【