论文推荐 | 单目标跟踪D3S,超越现有SOTA
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:知乎 作者:零维
链接: https://zhuanlan.zhihu.com/p/95842960 本文已由作者授权转载,未经允许,不得二次转载。

论文链接:https://arxiv.org/pdf/1911.08862.pdf
这篇论文是2019年挂靠arxiv上的新作,粗略扫了一眼,在各个评测数据集的表现可以用“爆炸”形容。论文对比的几个真.SOTA的追踪器,在VOT数据集上远不及D3S。不出意外,这篇论文八成是投递了CVPR 2020的一篇单目标追踪新作,下面来讲一下是本文如何做到这么优秀的跟踪结果的。
文章指出,当前基于模板匹配的方法因为具有较高的鲁棒性,因此主导了单目标的追踪领域,但是因为有矩形框的限定,降低了这些追踪的精度(框不准)。D3S致力于缩小目标追踪与目标分割的差距,利用单一网络,分支出两个互补的模型。一个模型负责追踪物体的非刚性形变,另一个模型负责实现高鲁棒性的在线目标分割。模型的输入为第一帧的一个实例分割的mask,实验效果达到了追踪数据集上的top,且在视频分割benchmark上与SOTA算法持平,在速度上快出一个数量级。
基于模板匹配的方法当物体的宽高比发生变化,或者物体旋转时由于语义信息的缺乏会变得不准确,并且基于轴对称的矩形框并不能代表部分非轴对称物体的表征特性,当物体非常细长、形变大的情况,最准确的定位位置的方法其实是对于周围像素的前景背景mask分割。D3S通过用两个视觉编码模型解决了上述说明的问题,其中一个分支称为GEM,具有自适应性与高辨别性,受限于欧几里得运动约束,而另一个称为GIM,用于探索更广范围内的目标状态转移情况。GIM牺牲了空间上的关系,追踪目标潜在的形变状态,而GEM仅仅预测位置。D3S也在多个数据集上证明了其SOTA的水平,并且不同的数据集之间不需要重新训练finetune,具有强大的普适性。
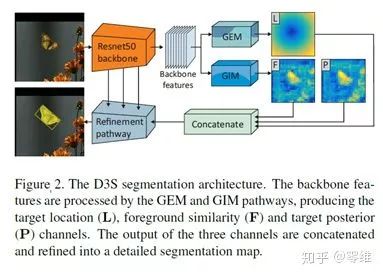
从网络骨干中可以看出,GEM分支负责位置的预测L,GIM分支负责前景的相似度F和目标后验P的检测。最终三个通道的输出串联到一个分割的map中。下面具体来讲一下GIM和GEM的实现过程。
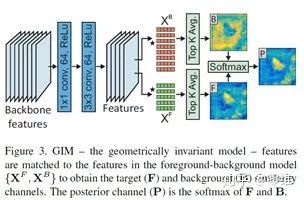
GIM的目的是分割出目标物体的轮廓。由于backbone的特征缺少精细的划分,首先通过1*1的卷积后降维,再通过一层3*3的卷积,这两层的目的是调整网络参数使得分支划分得到最佳的效果。在跟踪过程中,将在搜索区域计算前景与背景的相似度map,对于F来说,通过归一化的点积(与周围的点)在像素i的位置产生特征Sij,最终的Fi为前景最相似的top K个,背景相似度遵循同样的法则。后续的F与B的分支通过softmax引导到后通道P中,作为物体的mask认知。
GIM可以很好将目标与背景分离,但无法区分与目标物体相似的实例,导致了鲁棒性的下降。作者借鉴相关滤波的思想,采用最新的DCF相关追踪器ATOM中的公式,引入了带有几何约束的欧几里得模型GEM。如下图所示,GEM模块从backbone的特征中经过1*1的卷积核降维,之后通过通道数为64的DCF滤波进行相关操作,再经过PeLU的非线性生成相关滤波响应map。

由此可见,GIM与GEM形成了互补的像素级信息估计。GEM对位置信息敏感,GIM的输出显示出目标的更对细节特征。作者将GIM与GEM结合生成最终的分割结果,Refinement过程如下图所示。F、P、L的像素级map经过concatenate连接后首先经过3*3的卷积核+ReLU,变成64通道的feature map。通过backbone与feature map的三个upscaling操作将分辨率扩大。
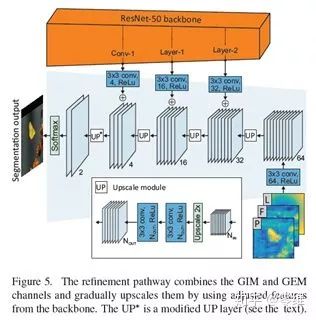
模型的backbone是预训练的resnet-50,搜索区域设置为384*384像素。模型在3471个YouTube-VOS数据集上的视频序列训练而成,仍然是以50帧间距内的成对样本作为训练。一批设置64对样本,训练40个Epoch,损失采用交叉熵损失。在单GPU下20小时即可完成训练,对比之前SOTA的追踪器可谓极其高效。速度方面,在单1080卡上可达到25fps的实时速度。
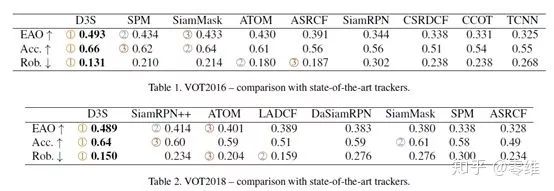
实验效果非常震撼。用20小时单卡训练出的模型,在不finetune超参数的情况下可以在精度、鲁棒性上完全压制当前最新的SiamRPN++、SiamMask等方法,VOT2018惊人的达到了0.489的EAO。
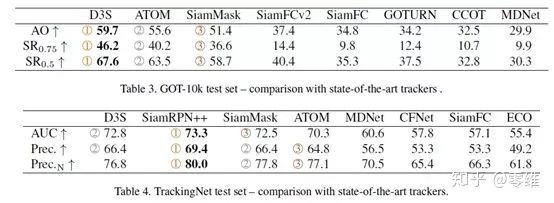
在GOT-10k、TrackingNet的表现上也可圈可点。
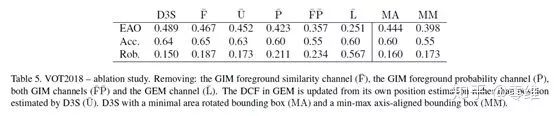
通过消融实验证明了GEM模块能够对追踪效果产生巨大的提升,尤其是鲁棒性的提升。没有GEM模块的追踪器仅仅在VOT2018上达到0.25的分数。
纵观2019年下半年,不难发现基于孪生网络的单目标追踪有一种趋势,即从“基于Detection的Tracking”思维中摆脱,采用多分支多通道拟合目标的位置、姿态等信息。从网络的训练配置和实验效果的双方面衡量,这篇文章的work无疑是相当成功的。
-END-
点击 阅读原文,可跳转浏览本文内所有网址链接
*延伸阅读
PS:新年假期,极市将为大家分享计算机视觉顶会 ICCV 2019 大会现场报告系列视频,欢迎前往B站【极市平台】观看,春节也学习,极市不断更,快来打卡点赞吧~
https://www.bilibili.com/video/av83518299
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~





