![]()
作者 | Johann Zhou
编辑 | 陈大鑫
今天介绍的是一篇已被ECCV 2020接收的论文,这篇论文中提出了一种全新的通用框架,利用共享的主干网络,同时解决音频-视觉学习的两大主流问题:视觉信息引导的声源分离和立体声重构。
本文的核心在于将双声源分离问题看作双通道立体声重构的特殊情况,从而得以充分利用单通道音频,利用声源分离的训练丰富网络对更丰富数据的处理能力,提升立体声重构的效果。
以下是本文提供给会议的长视频介绍,文章的立体声重构和声源分离的效果在视频后半部分。
完整版视频:https://hangz-nju-cuhk.github.io/projects/Sep-Stereo
论文链接:https://arxiv.org/pdf/2007.09902.pdf
开源代码:https://github.com/SheldonTsui/SepStereo_ECCV2020
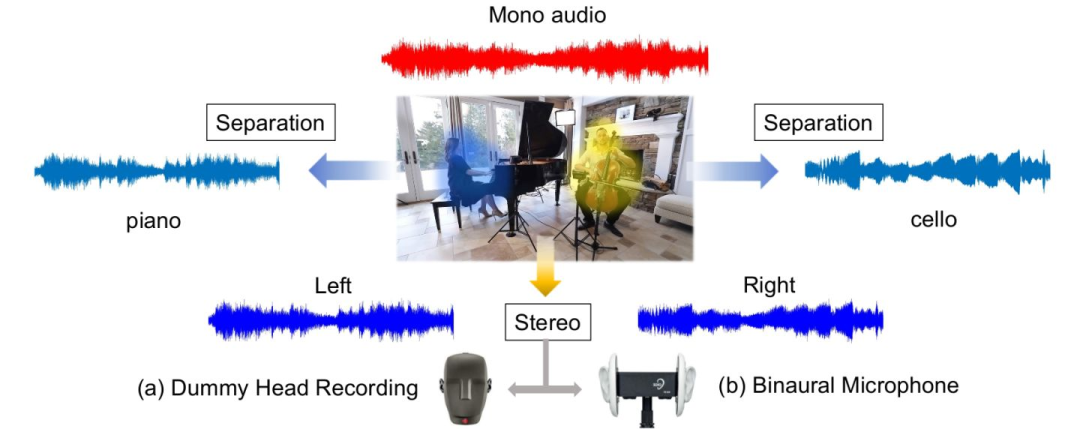
得益于双耳效应,人类仅凭声音就可对声源位置有准确的感知。所以当用户观看视频,尤其是音乐演奏时,视听信息的和谐对于提升用户体验非常重要。视觉信息对应的立体声效果。由此出发,之前的研究者们提出了用数据驱动的方式,通过视觉信息恢复立体声的方法[1][2]。他们的核心思想,都是先将录制好的立体声(多通道音频)数据,还原成单通道音频,再使用神经网络学习单通道到多通道的映射。然而这些基于深度学习的方法依赖专业设备(见下图a,b)采集的视频与立体声数据,所以数据的缺乏限制了目前学术界的发展。
与此同时,有单通道音频的视频却很好收集,在视觉引导的声源分离领域(请见近期发展review),这种数据已经被大规模得用于神经网络的训练。而基于观察,声源分离和立体声重构问题都需要找到声源形象在视觉信息中的位置,并将其与音频中对应的乐器音色对应起来。甚至立体声重构可以看做将声源进行分离后的重组,这启发作者将这两个任务进行统一。 ![]()
本文的核心在于把双声源的分离问题,看作左右声道立体声重构的一个特殊问题,从而把声源分离和立体声重构统一进一个框架。具体来说,我们可以将同时演奏的两个声源,人为的放在人类视野的最左端和最右端,并认为两个声源中间的空间一无所有。在此情况下,我们认为人的左耳只能听到左边声源的声音,右耳只能听到右边声源的声音,从而将声源分离问题转化为立体声重构问题。
将两个任务统一的学习过程类似 Multi-task Learning。而我们的动机更多是在于通过声源分离,使得更多类型的音频经过主干网络,从而使用大量的单通道音频,提高主干网络在进行立体声重构任务时对不同输入的泛化能力和建模能力(capacity)。
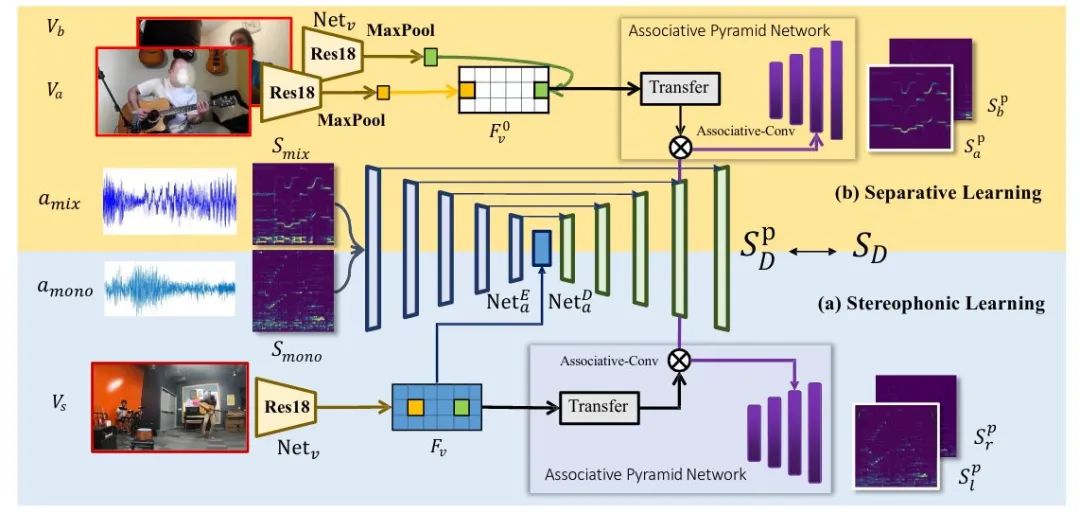
本文方法的整体框架如上图所示,在训练中可以被分为立体声学习和分离学习两部分。
立体声学习在上图下半部分,在网络中的输入是单通道的音频的短时傅里叶变换(STFT)频谱和一张参考图像,网络预测的目标是立体声左右两通道分别的STFT频谱。主干网络我们follow Mono2Binaural[1],使用了和他们一样的UNet,并保留了和他们一样的损失函数,作为立体声学习的基础。相似地,直接预测频谱是比较困难的事,所以我们预测的是目标频谱相对于输入频谱的Mask。
分离学习在上图上半部分,网络的视觉信息输入是两段独立的单人演奏视频,音频信息则是将两段音频混合得到的单通道结果。网络预测的目标是这两段独立音频分别的频谱。在这种场景下,分离学习和立体声学习的音频输入输出维度得到了统一,都是单通道—>双通道音频,所以分离中的独立音频a和b可以和立体声中的左耳(l)和右耳(r)频谱放在同等位置。
联合金字塔网络(Associative Pyramid Network,APNet)
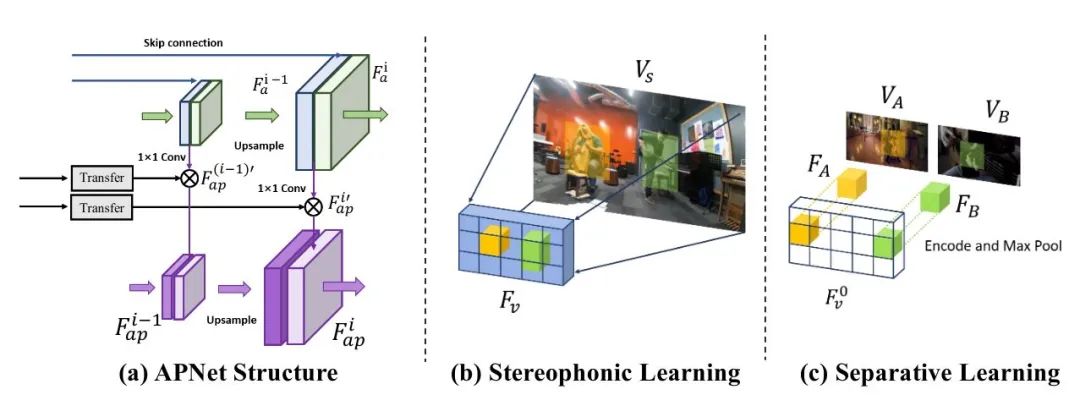
对于立体声学习,我们需要音频信息与视觉网络抽取的视觉特征中不同位置的信息相互作用。于是我们设计了联合金字塔网络(APNet),一个依赖主干UNet的侧枝网络,通过coarse-to-fine的方式把视觉和音频信息联系起来。网络设计的理念是假设立体声来源于各个视觉特征位置所对应的音频信息的组合,所以网络的作用在于引导不同位置的视觉特征与频谱的特征分别进行融合,生成与位置信息强相关的新层,从而希望网络自然地从不同位置的视觉特征中学出显著特征(乐器)所在的位置和类别。
具体的操作如下图(a)所示,对于视觉网络直接encode的(b)每个位置的视觉特征,我们将其变为一个1x1卷积核的每个channel,用其对音频网络的各层进行加权组合成新的APNet网络中的层。从不同尺度UNet获得的APNet的特征再通过upsample操作进行积累。最后一层APNet特征代表了不同位置视觉特征对应的音频频谱响应,所以我们最终使用两个卷积将其统一为要预测的左右通道频谱的Mask。
立体声学习和分离学习的最重要的区别在于视觉信息的应用。对于立体声学习,网络需要预测每个显著特征(乐器)在空间中的相对位置和类别;而对分离学习,只有类别信息是最重要的,位置信息不起作用。我们的做法是手动对视觉特征进行操作,将两个视频的视觉特征进行Max Pooling操作,并希望以此找到视觉特征中最重要的部分(乐器),然后人为的将其放在一个空白的视觉特征的最两侧,如上图(c)所示。如此一来,我们假设人的视野中只有最左和最右两侧可以看到物体,而中间部分是完全没有意义的空间。这一假设与我们APNet的motivation也可以完美结合,此时对左右通道有贡献的只有视觉信息的最左和最右部分,从而可以假设左耳只能听到左边的乐器而右耳只能听到右边乐器的声音。
通过APNet和视觉信息的重排列,我们可以将分离学习和立体声学习完全统一到同一个网络的训练中。不过在我们自己对结果进行复现的过程中发现如果完全使用共享的网络参数,网络会很难收敛,所以最终版本的分离学习和立体声学习共享整个音频主干UNet网络和视觉信息的encoder,而两支分别用两个独立的APNet作为Head。
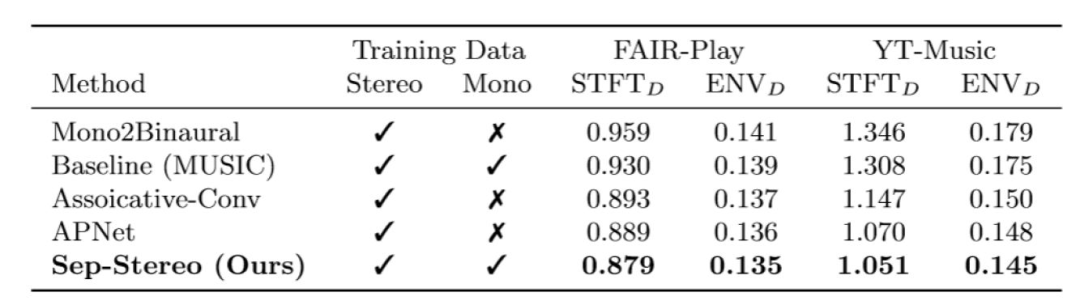
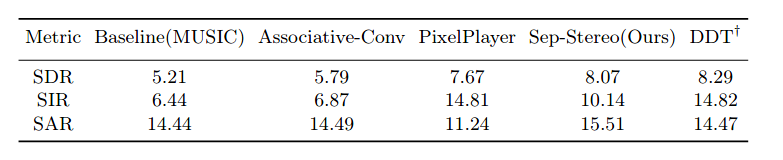
在立体声重构的数值结果上,我们超过了之前的方法Mono2Binaural[1],同时验证了我们方法各个模块的有效性。在声源分离实验上,我们也取得了和专攻分离的论文相似的结果。不过自然,生成相关的paper只看数值结果没有说服力,我们推荐大家戴上耳机去听我们提供的视频。
![]()
![]() 我们还根据视觉特征的激活程度,展示了网络在视觉信息中所关注的位置。更多详细得分析和方法的细节还请参见论文和补充材料。
本文把视觉引导的声源分离任务和立体声重构任务结合,统一到我们的Sep-Stereo框架内,并因此利用了大量的单通道音频,提升了立体声重构的效果。这篇工作在两个任务上都展示了很强的结果,并提高了双通道立体声重构的SOTA。不过这篇工作还有很多问题没有解决:(1)人工重排列的视觉特征和真实encode得的视觉特征之间存在明显的domain gap,使得网络在真实场景中的泛化能力依然有限。(2)应用场景受限于音乐数据,距离实际应用距离甚远。希望这篇文章能引起大家对这个领域的科研兴趣,可以有更多人向更深的层次探索。
[1] Gao, R., Grauman, K.: 2.5 d visual sound. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019).
[2] Morgado, P., Nvasconcelos, N., Langlois, T., Wang, O.: Self-supervised generation ofspatial audio for 360 video. In: Advances in Neural Information Processing Systems. (NeurIPS 2018).
[3] Zhou, H., Xu, X., Lin, D., Wang, X., Liu, Z.: Sep-stereo: Visually guided stereophonic audio generation by associating source separation. In: Proceedings of the European Conference on Computer Vision (ECCV 2020).
知乎专栏:
https://zhuanlan.zhihu.com/p/162689191?utm_source=wechat_session&utm_medium=social&utm_oi=540650933827309568
我们还根据视觉特征的激活程度,展示了网络在视觉信息中所关注的位置。更多详细得分析和方法的细节还请参见论文和补充材料。
本文把视觉引导的声源分离任务和立体声重构任务结合,统一到我们的Sep-Stereo框架内,并因此利用了大量的单通道音频,提升了立体声重构的效果。这篇工作在两个任务上都展示了很强的结果,并提高了双通道立体声重构的SOTA。不过这篇工作还有很多问题没有解决:(1)人工重排列的视觉特征和真实encode得的视觉特征之间存在明显的domain gap,使得网络在真实场景中的泛化能力依然有限。(2)应用场景受限于音乐数据,距离实际应用距离甚远。希望这篇文章能引起大家对这个领域的科研兴趣,可以有更多人向更深的层次探索。
[1] Gao, R., Grauman, K.: 2.5 d visual sound. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019).
[2] Morgado, P., Nvasconcelos, N., Langlois, T., Wang, O.: Self-supervised generation ofspatial audio for 360 video. In: Advances in Neural Information Processing Systems. (NeurIPS 2018).
[3] Zhou, H., Xu, X., Lin, D., Wang, X., Liu, Z.: Sep-stereo: Visually guided stereophonic audio generation by associating source separation. In: Proceedings of the European Conference on Computer Vision (ECCV 2020).
知乎专栏:
https://zhuanlan.zhihu.com/p/162689191?utm_source=wechat_session&utm_medium=social&utm_oi=540650933827309568
AI科技评论联合博文视点赠送周志华教授“森林树”十五本,在“周志华教授与他的森林书”一文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在“周志华教授与他的森林书”一文留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。
阅读原文,直达“ KDD”小组,了解更多会议信息!