国科大提出目标检测新方法:FreeAnchor,mAP 高达 44.8!

本文转载自:新智元
【导读】中国科学院大学联合厦门大学和深圳鹏城实验室,提出一种自由锚框匹配的单阶段物体检测方法FreeAnchor。在MS-COCO数据集上显著超越了双阶段检测方法FPN,成果被 NeurIPS 2019 接收,代码已开源。
中国科学院大学联合厦门大学和深圳鹏城实验室,提出一种自由锚框匹配的单阶段(One-stage)物体检测方法FreeAnchor。
通过目标与特征的自由匹配,该方法突破了“Object as Box”, 与“Objectas Point”的建模思路,探索了Object as Distribution的新思路。
FreeAnchor在MS-COCO数据集上显著超越了双阶段(Two-stage)检测方法FPN,成果被 NeurIPS 2019 接收。
论文地址:https://arxiv.org/pdf/1909.02466
开源地址:https://github.com/zhangxiaosong18/FreeAnchor
过去几年中,卷积神经网络(CNN)在视觉物体检测中取得了巨大成功。为了使用有限卷积特征表示具有各种外观,纵横比和空间布局的物体,大多数基于CNN的检测器利用具有多尺度和多长宽比的锚框作为物体定位的参考点。通过将每个物体分配给单个或多个锚框,可以确定特征并进行物体分类和定位。有锚框的物体检测器利用空间关系,即物体和锚框的交并比(IoU),作为锚框划分的唯一标准。基于与物体边界框(Box)空间对齐的锚框(Anchor)最适合于对物体进行分类和定位的直觉,网络在每个锚框处的损失独立地监督下进行学习。然而,在下文中,我们认为这种直觉是不准确的,手工设计IoU匹配物体与特征的方法不是最佳选择。
一方面,对于“偏心”的物体,其最有判别力的特征并不靠近物体中心。空间对齐的锚框可能对应于较少的代表性特征,这会限制目标分类和定位能力。另一方面,当多个物体聚集在一起时,使用IoU标准匹配具有适当锚框/特征的物体是不可行的。亟待解决的问题是如何将锚框/特征与物体完美匹配。
本研究提出了一种学习匹配锚框的物体检测方法,目标是丢弃手工设计的锚框划分,同时优化以下三个视觉物体检测学习目标。首先,为了实现高召回率,检测器需要保证对于每个物体,至少一个锚框的预测足够准确。其次,为了实现高检测精度,检测器需要将具有较差定位(边界框回归误差大)的锚框分类为背景。第三,锚框的预测应该与非极大抑制(NMS)程序兼容,即分类得分越高,定位越准确。否则,在使用NMS过程时,可能抑制具有精确定位但是低分类分数的锚框预测。
为了实现以上目标,我们将物体-锚框匹配表示为最大似然估计(MLE)过程,从每个物体的锚框集合中选择最具代表性的锚框。定义每个锚框集合的似然概率为包中各锚框预测置信度的最大值,保证了存在至少一个锚框,对物体分类和定位都具有很高的置信度。同时,具有较大定位误差的锚框被归类为背景。在训练期间,似然概率被转换为损失函数,然后该函数同时驱动物体-锚框匹配和检测器的学习。
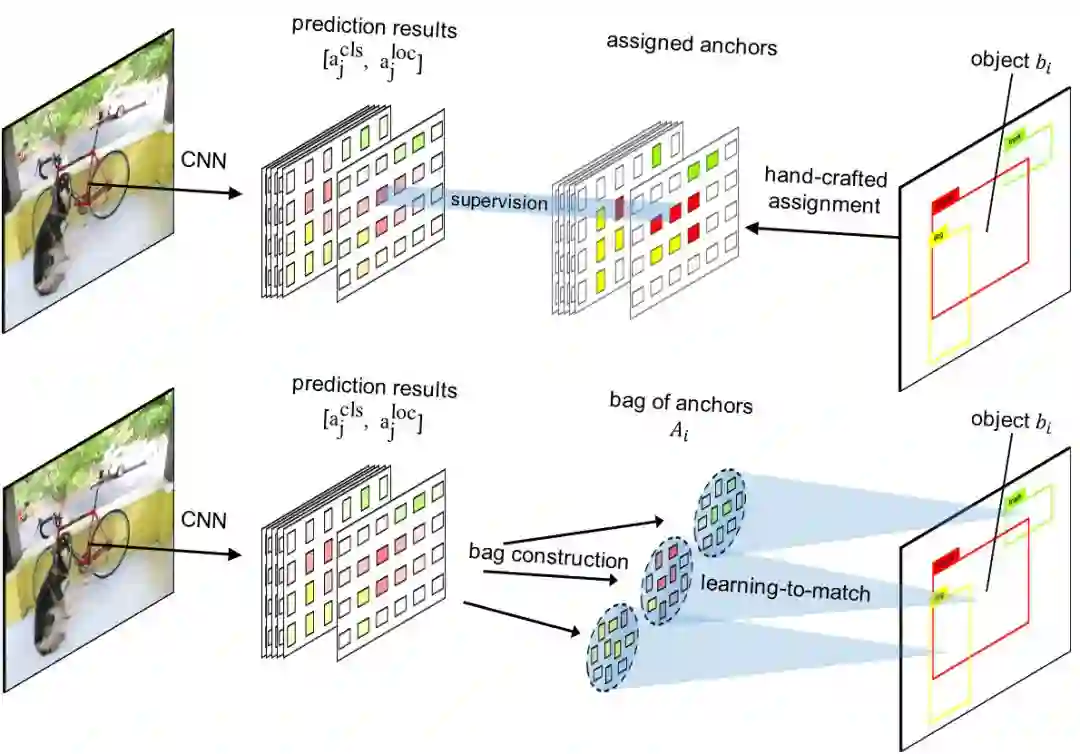
图 1 手工设计锚框划分(上图)和自由锚框匹配的对比(下图)
对于原始的单阶段检测器,给定一张输入图片,用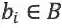
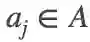
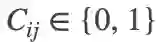
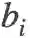
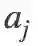
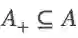
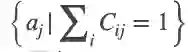
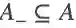
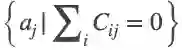
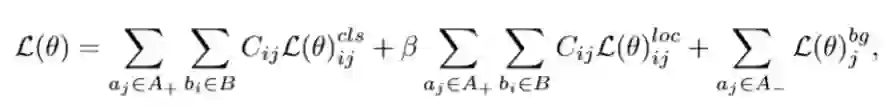
根据极大似然估计,原始的总体损失可以转化为似然概率:
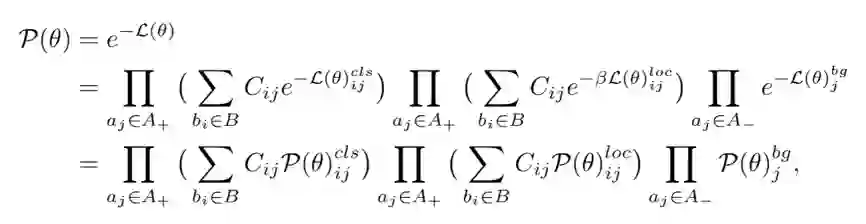
这个似然概率描述了基于CNN的目标检测框架,严格约束了锚框分类和回归的优化,却忽略了对匹配矩阵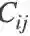
为了实现物体-锚框匹配的优化,我们引入自由锚框匹配似然概率来扩展基于CNN的检测框架。所引入的似然概率在结合检测召回率和精度的要求的同时,保证与NMS的兼容性。首先根据锚框与物体的空间关系选择n个IoU比较大的锚框为每个物体构建锚框集合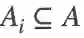
为了优化召回率,对于每个物体

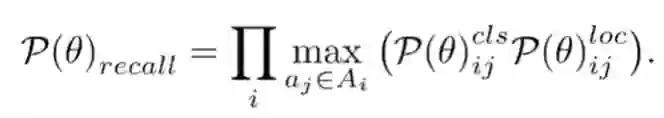
为提高检测精度,检测器需要将定位不佳的锚框分类为背景,其似然概率如下:
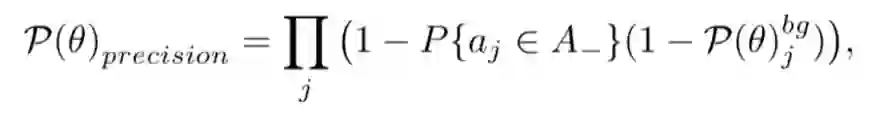
其中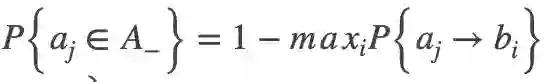
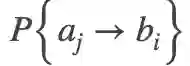
(1)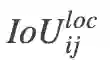
(2)
(3)对于物体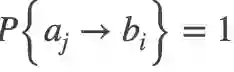
我们令
实现上面描述的三个属性,自由锚框匹配似然概率定义如下:
它结合了召回率、精确和与NMS兼容的目标。通过优化这个似然概率,我们同时最大化召回率似然和精度似然,并且在检测器训练期间实现自由的物体-锚框匹配。
为了在CNN检测框架中实现上述锚框-物体匹配方法,我们定义自由锚框匹配似然概率,并将似然概率转换为匹配损失,如下:
其中max函数用于为每个物体选择最佳锚框。在训练期间,从一个锚框集合A中选择单个锚框,然后使用该锚框来更新网络参数θ。但在训练早期,对于随机初始化的网络参数,所有锚框的置信度都很小,具有最高置信度的锚框不一定合适。因此,我们使用Mean-max函数选择锚框,定义如下:
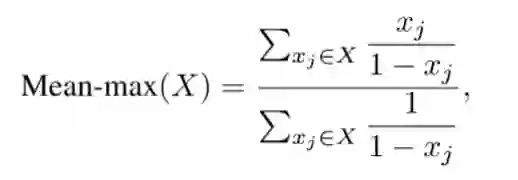
当训练不充分时,如图 2所示,Mean-max函数将接近平均功能,这意味着锚框集合中的几乎所有锚框都用于训练。随着训练的进行,一些锚框的置信度增加,并且Mean-max函数更接近max函数。当充分训练网络后,Mean-max函数可以从锚框集合中为每个物体选择一个最佳锚框。
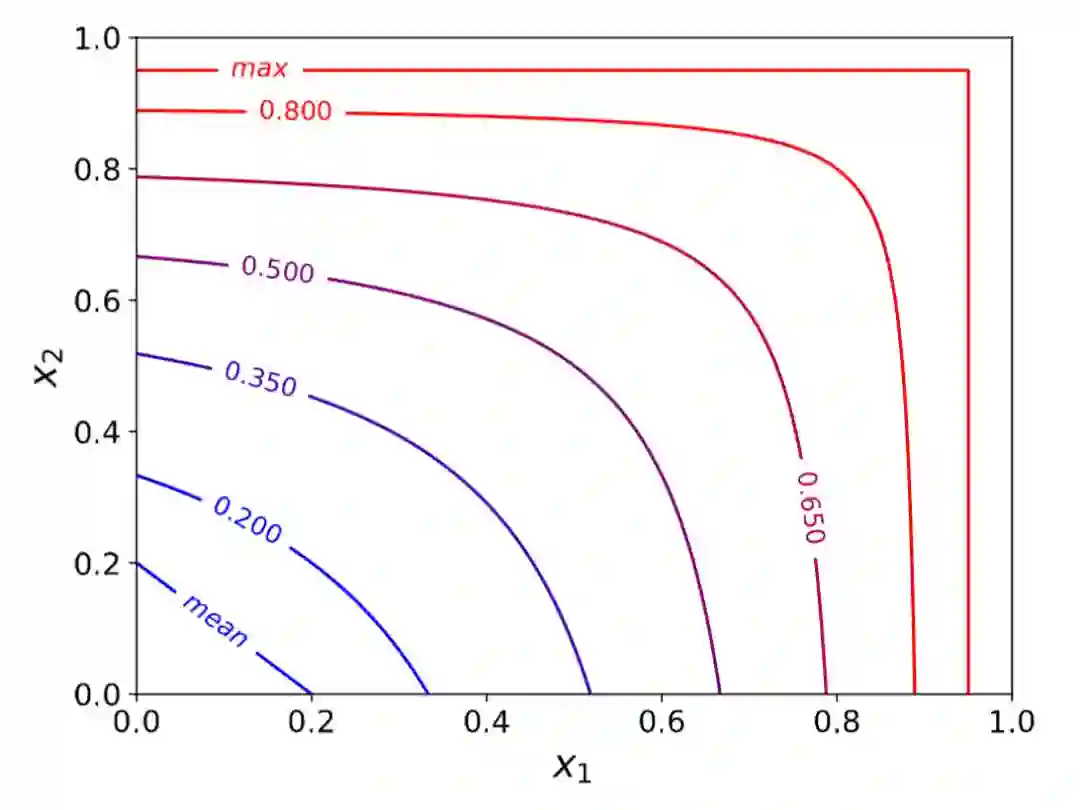
图 2 Mean-max 函数
最终,用Mean-max函数替换检测定制损失中的max函数,增加平衡因子w1 w2,并将Focal Loss应用于损失的第二项,结果如下:
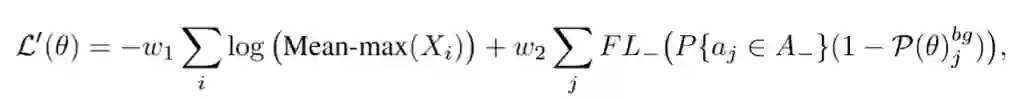
其中 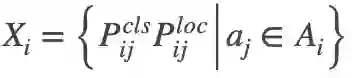
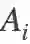
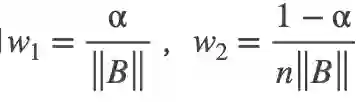
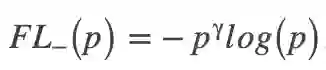
FreeAnchor基于先进的单阶段检测器RetinaNet实现,通过将上述的自由锚框匹配损失替换RetinaNet中的损失,我们把RetinaNet 更新为自由锚框匹配检测器FreeAnchor。
1. 学习锚框匹配:所提出的学习匹配方法可以选择适当的锚框来表示感兴趣的物体,如图3所示:

图 3 为“笔记本电脑”学习匹配锚框(左)与手工设计锚框分配的比较(右),红点表示锚中心。较红的点表示较高的置信度。为清楚起见,我们从所有50个锚框中选择了16个长宽比为1:1的锚框。
手工设计的锚框分配在两种情况下失败:物体特征偏心和拥挤场景。FreeAnchor有效地缓解了这两个问题。对于容易出现特征偏心的细长物体类别,如牙刷,滑雪板,沙发和领带,FreeAnchor显著优于RetinaNet基线,如图4所示。对于其他物体类别,包括时钟,交通信号灯和运动球FreeAnchor的性能相当与RetinaNet。其原因在于,学习匹配过程驱动网络激活每个物体的锚框集合内的至少一个锚框,以便预测正确的类别和位置。激活的锚框没有必要与物体空间对齐,只需要有对物体分类和定位的最具代表性的特征。
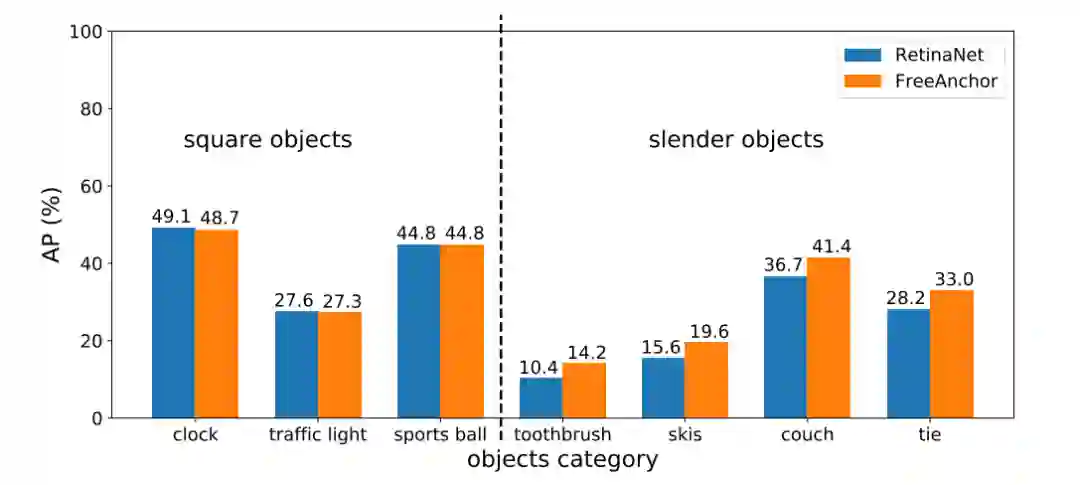
图 4 方形和细长类别物体的性能对比
我们进一步比较了RetinaNet和FreeAnchor在拥挤场景中的表现,如图5所示。随着单个图像中物体数量的增加,FreeAnchor对RetinaNet的提升变得越来越明显。这表明FreeAnchor具有学习匹配锚框的能力,可以在拥挤的场景中为物体选择更合适的锚框。
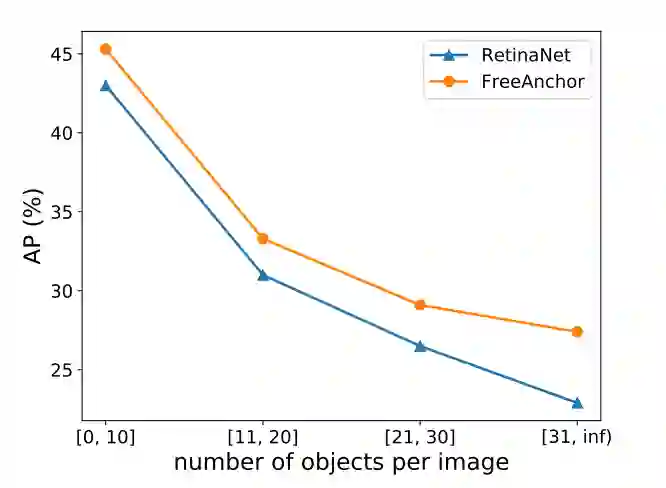
图 5 拥挤场景的性能对比
2. 保证与NMS的兼容性:为了评估锚框预测与NMS的兼容性,我们将NMS召回率(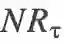

表 1 COCO验证集上的NMS召回率(%)比较
检测性能
表2将FreeAnchor与RetinaNet基线进行比较。FreeAnchor通过可忽略不计的训练和测试时间成本将AP提升至3.5%左右,这对具有挑战性的通用物体检测任务来说是一个显著提升。
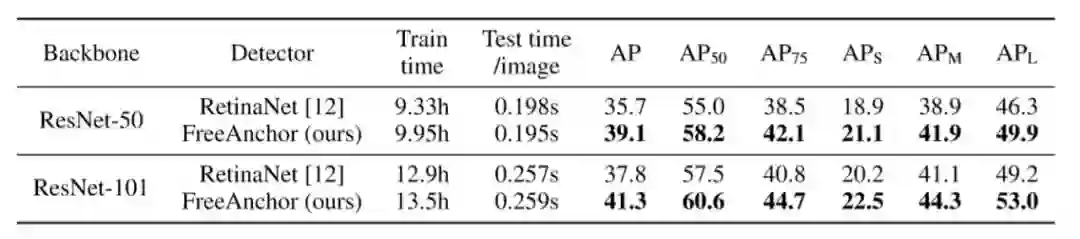
表 2 FreeAnchor和RetinaNet(基线)的检测性能比较
在表 3中FreeAnchor和其他方法进行了对比。它显著超出了Two-stage的FPN方法,也优于最新的基于点检测方法。在使用更少的训练迭代(135K vs 500K)和更少的网络参数(96.9M vs210.1M)前提下,FreeAnchor超过了CornerNet。
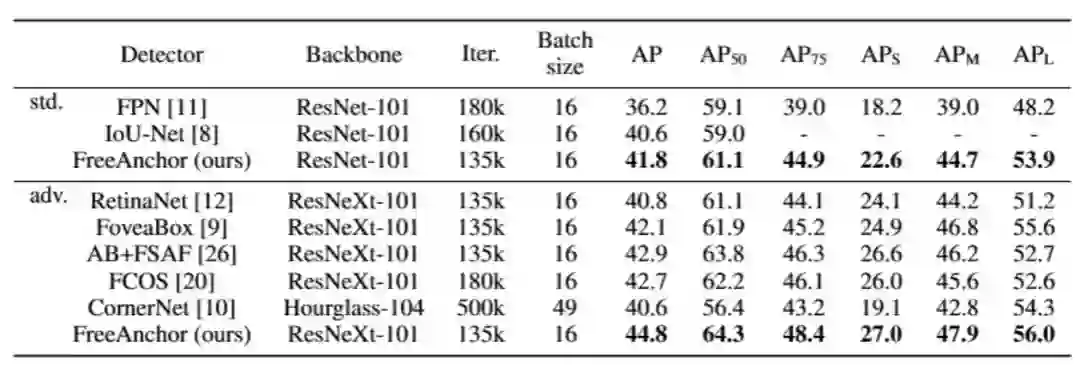
表 3 FreeAnchor与其他方法的检测性能比较
FreeAnchor的本质是通过目标与特征的自由匹配,实现为每个物体选择适合的锚框,其本质为每个物体选择合适的CNN特征。FreeAnchor突破了“Object as Box”, 与“Object as Point”的建模思路,通过极大似然估计对物体范围内的特征分配不同的置信度建立起一个无参数的分布,探索了“Object as Distribution”的新思路。
论文地址:https://arxiv.org/pdf/1909.02466
开源地址:https://github.com/zhangxiaosong18/FreeAnchor
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测交流群,同时还可以加入目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!
