【强化学习】强化学习的应用场景、基本概念、数学模型和交易中的应用
作者:Aishwarya Srinivasan
翻译:Cream
校对:王雨桐
本文介绍了强化学习的应用场景、基本概念和数学模型。
DeepMind开发的AlphaGo(用于下围棋的AI系统)的出现引起了强化学习的热潮。从那之后,许多公司开始投入大量的时间、精力来研究强化学习。目前,强化学习是深度学习领域中的热点问题之一。大多数企业都在努力寻找强化学习的应用实例或者将其应用在商业中的方法。目前来说,此类研究只在零风险、可观测并且易模拟的领域展开。所以,类似金融业、健康行业、保险业、科技咨询公司这样的行业不愿冒险去探索强化学习的应用。此外,强化学习中的“风险管理”部分给研究带来了很大压力。Coursera的创始人Andrew Ng曾表示:“强化学习在机器学习中,对数据的依赖远超过有监督学习。我们很难获得足够多的数据来应用强化学习算法。因此,将强化学习应用到商业实践中仍有许多工作要完成。”
基于这样有些悲观的想法,本文的第1部分将从技术层面深入地探讨强化学习。在第2部分,我们将介绍一些潜在的商业应用。基本上,强化学习是一种复杂的算法,用于将观察到的实际情况和度量(累计奖励)映射到动作集合中,以实现短期或长期的奖励最优化。强化学习的智能体(agent)通过和环境的互动不断学习策略,策略一个动作(以奖励为导向的)序列。事实上,强化学习关注的是即时奖励和随后步骤的奖励(延迟的奖励),因为奖励值是决定智能体改变策略的主要依据。
强化学习的模型包含一个智能体(agent),该智能体在每个环境状态下,通过执行一个动作,改变其状态,这个动作产生的影响用奖励函数来表示。该智能体的目标是要实现长期累计的奖励最大化,在每一个动作执行后,将反馈传递给智能体,智能体可以评估在当前环境最优的下一个动作。通过历史相似情况下的最佳行动,系统会从中学习经验。
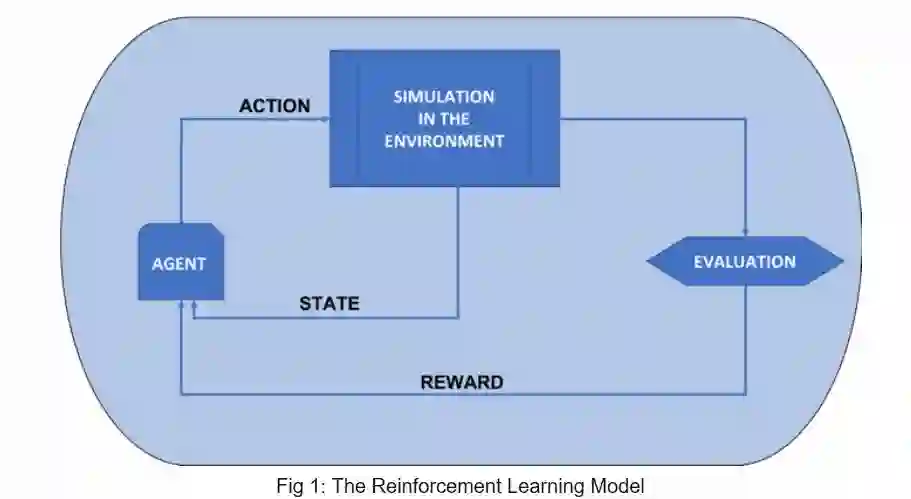
图 1 强化学习模型
从数学的角度,我们可以把强化学习看作一个状态模型,特别是一个完全可观测的马尔可夫决策过程(MDP)。为了理解MDP背后的概率理论,我们首先要了解马尔可夫的性质,如下:
“未来只依赖于当前,与过去无关。”
此性质用于这样的环境:不同行为产生的结果的概率与历史状态无关,只依赖于当前状态。有人用“无记忆性”来描述这个性质。在需要用过去状态来推测未来结果的情形下,马尔可夫性质不适用。
这个模型的环境是有限的随机过程,输入智能体的动作,以产生的奖励为输出。总奖励函数(长期累积奖励函数)包含即时奖励和长期折扣的奖励两部分。即时奖励是在智能体执行了一个动作到达某种状态所得到的量化的奖励。长期折扣奖励表示的是这个动作对未来状态的影响。
长期折扣奖励采用折扣因子γ,0<γ<1。折扣因子越大,这个系统越倾向于长期奖励;折扣因子越小,这个系统倾向于即时奖励。Χt表示t时刻的状态,At表示t时刻智能体的动作。
状态转移概率函数:智能体在当前状态Χt-1,执行动作A,产生的状态之间的转移概率:
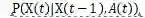
智能体是模拟为一个随机过程的有限状态的机器,输入当前状态,输出下一步执行的动作。St是t时刻的状态,是t-1时刻执行了At动作后达到的状态。At是在长期累计奖励最大化的策略模型下t时刻的策略。
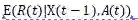
状态转换函数:智能体向一个状态的转变是与环境互动的结果。也就是说智能体某一时刻的状态是关于上一时刻状态、奖励、动作的函数。
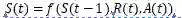
策略函数:策略是在状态St下,以奖励最优化为目标,要执行的动作。
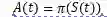
智能体的目标是找到满足长期累计折扣奖励最大化的策略Ppi
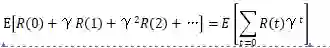
智能体在马尔可夫决策过程中试图从当前状态出发,获得最大的总奖励期望。因此,需要得到最优值函数。Bellman方程用于值函数,分解为当前奖励和下一个状态值的贴现值。
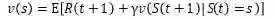
希望你们能够从本文中获得关于强化学习的技术知识!!
原文标题:
Reinforcement Learning: The Business Use Case, Part 1
原文链接:
https://www.kdnuggets.com/2018/08/reinforcement-learning-business-use-case-part-1.html
译者简介

王power,求职狗,在香港科技大学学习大数据科技。感觉数据科学很有难度,也很有意思,还在学(tu)习(tou)中。一个人肝不动的文献,来数据派follow大佬一起肝。
强化学习的商业应用
作者:Aishwarya Srinivasan, Deep Learning Researcher
翻译:赵雪尧
较对:丁楠雅
本文介绍了强化学习在交易中的应用。
在上一篇文章中,我着重于从计算和数学视角理解强化学习,以及我们在业务中使用算法时面临的挑战。
在本文中,我将探讨强化学习在交易中的应用。金融行业一直在探索人工智能和机器学习的应用,但金融风险让人们不愿这么做。近年来,传统的算法交易得到了发展,如今高计算能力的系统已经实现了任务的自动化,但交易员们仍然要负责制定交易决策。一个股票购买算法模型可能会基于一份估值和增长指标条件清单,来定义一个“买入”或“卖出”信号,然后由交易员定义的某些特定规则触发。
例如,这个算法可能很简单,只要在收盘时观察标准普尔指数比过去30天的高点还要高,就买入,或者该指数比过去30天的低点还低,就平仓。这些规则可以是趋势跟踪、反趋势或基于自然界的模式。不同的技术分析师不可避免地会对模式和确认条件有不同的定义。
为了使这种方法系统化,交易员必须指定精确的数学条件,以清楚地确定是否形成了头肩顶模式(译者注:头肩顶(Head & Shoulders Top)是股票价格和市场指数最为常见的倒转形态图表之一。头肩顶形态为典型的趋势反转形态,是在上涨行情接近尾声时的看跌形态,图形以左肩、头部、右肩及颈线构成[1]。),以及确定确认该模式的精确条件。
在当前金融市场的先进机器学习领域,我们可以看看在2017年10月亮相的EquBot公司的AI型交易所交易基金(AI-based Exchange Traded Funds ETFs )。EquBot将这些ETFs 自动化,收集来自数千家美国公司的市场信息、超过100万个市场信号、季度新闻文章和社交媒体帖子。
一个给定的ETF可能会选择30到70家有很高市场升值机会的公司,它将从每笔交易中继续学习。另一个知名的市场参与者Horizons也推出了类似的主动AI全球ETF (Active AI Global ETF),这款ETF利用包括交易员制定策略在内的监督机器学习技术开发而成。使用监督学习方法,人工交易员帮助选择阈值、解释延迟、估计费用等等。
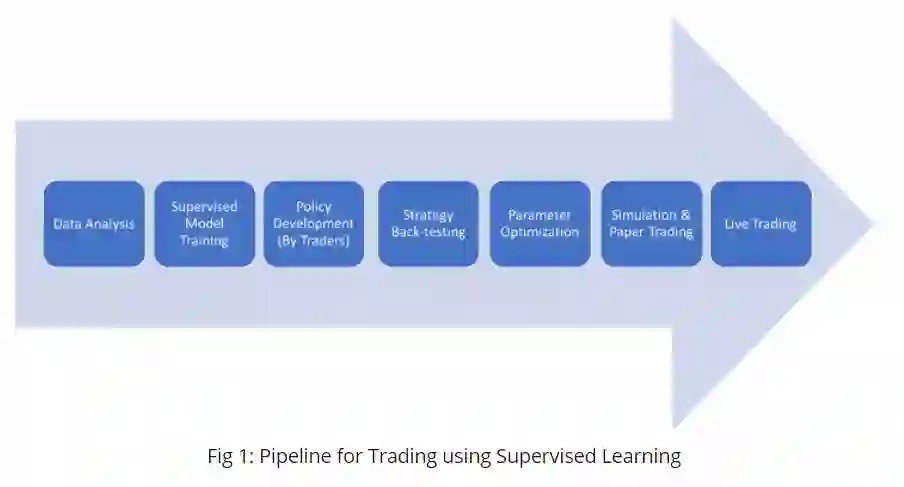

Fig1:使用监督学习技术的交易流程图(译者注:纸交易(paper trading),即在模拟账户中进行交易[2]。)
当然,如果要完全自动化,人工智能驱动的交易模型必须比预测价格做得更多。它需要一个基于规则的策略,将股票价格作为输入,然后决定是买入、卖出还是持有。
2018年6月,摩根士丹利(Morgan Stanley)任命宾夕法尼亚大学(University of Pennsylvania)的计算机科学家迈克尔•卡恩斯(Micheal Kearns)担任首席执行官,以扩大人工智能的应用。在接受彭博社采访时,卡恩斯博士指出,“虽然标准的机器学习模型对价格进行预测,但它们没有具体说明行动的最佳时间、交易的最佳规模或交易对市场的影响。” 他补充说:“通过强化学习,你正在学习如何预测你的行为对市场状况的影响。”
强化学习允许端到端优化和最大化回报。至关重要的是,强化学习模型本身会调整参数,以使其接近最优结果。例如,我们可以想象,当下跌超过30%时,会产生巨大的负面回报,这迫使模型考虑使用另一个策略。我们也可以建立模拟来改善在关键情况下的反应。例如,我们可以在强化学习环境中模拟延迟,以便为模型生成负面激励。这种负面回报反过来又迫使模型学习应对延迟的变通方法。类似的策略允许模型随着时间的推移自动调整,不断地使其更强大和适应性更强。
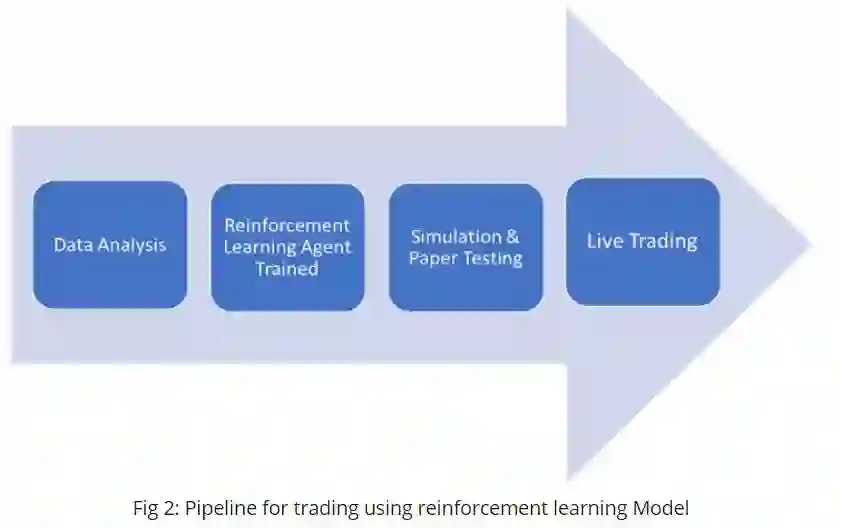

Fig2:使用强化学习模型进行交易的流程图
在IBM,我们在DSX平台(IBM Data Science Experience (DSX))上建立了一个复杂的系统,利用强化学习的力量进行金融交易。该模型利用历史股票价格数据,通过在每一步中采用随机策略进行训练,并根据每笔交易的盈亏来计算回报函数。
“IBM数据科学体验平台(DSX)是一个企业数据科学平台,它为团队提供了最广泛的开源和数据科学工具,以满足任何技能需求,在多云环境中构建和部署任何地方的灵活性,以及更快地操作数据科学成果的能力。”
以下图表示了将强化学习方法与金融交易应用在一起的使用案例。
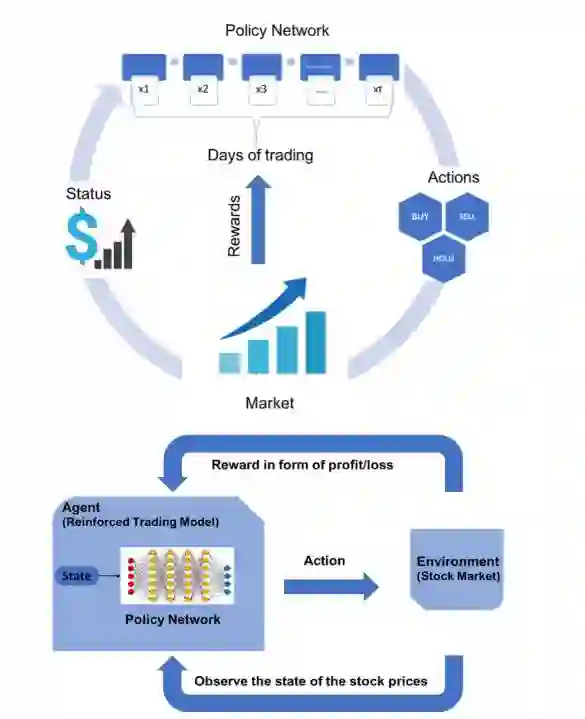
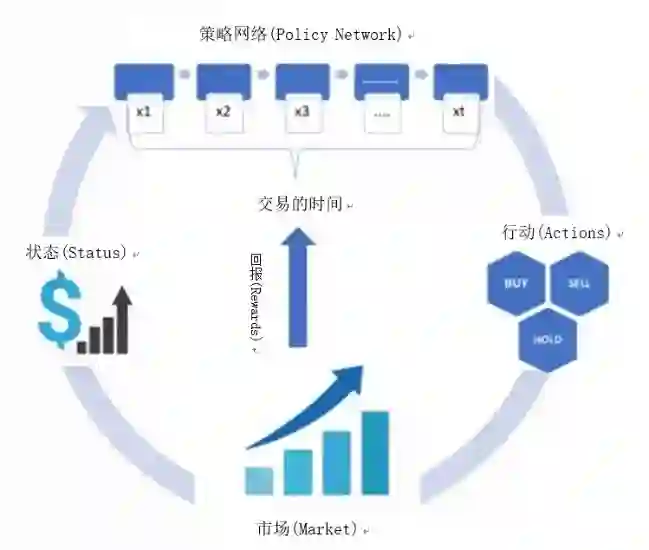
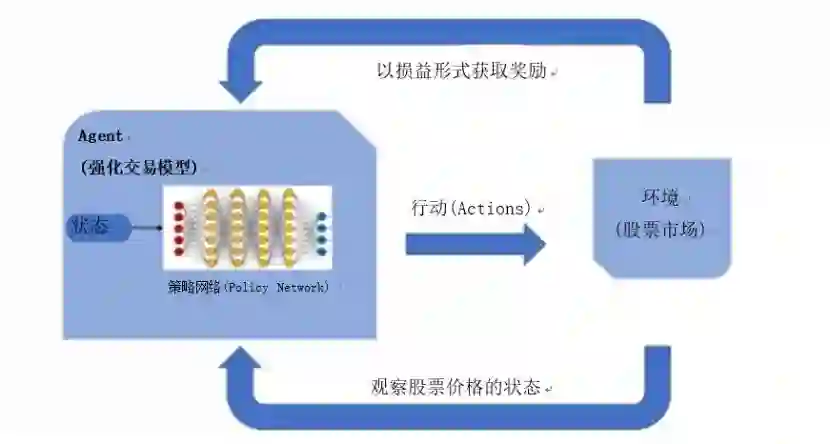
Fig3:强化学习交易模型
我们使用alpha指标(积极的投资回报,ROI)来衡量强化交易模型的表现,并根据代表市场整体走势的市场指数来评估投资的表现。最后,我们以一个简单的买入&持有策略模型和ARIMA-GARCH策略模型来进行模型评估对比。我们发现,该模型根据市场走势进行了非常精细的调节,甚至可以捕捉到头肩顶的模式,这些都是可以预示市场逆转的重要趋势。
强化学习可能并不适用于所有业务场景,但它捕捉金融交易微妙之处的能力肯定会显示出它的复杂性、威力和更大的潜力。
请继续关注我们在更多业务场景中测试强化学习的能力!
[1] 百度百科:
https://baike.baidu.com/item/%E5%A4%B4%E8%82%A9%E9%A1%B6
[2] https://www.avatrade.cn/education/trading-for-beginners/paper-trading.html
原文标题:
Reinforcement Learning: The Business Use Case, Part 2
原文链接:
https://www.kdnuggets.com/2018/08/reinforcement-learning-business-use-case-part-2.html
译者简介

赵雪尧,北邮研三在读,京东见习算法工程师,目前研究强化学习广告竞价模型。相信数据和算法将为企业发展赋能,希望跟志同道合的小伙伴一起追寻前沿消息,深入探索算法的极限。在玄学调参的道路上,一路狂奔。

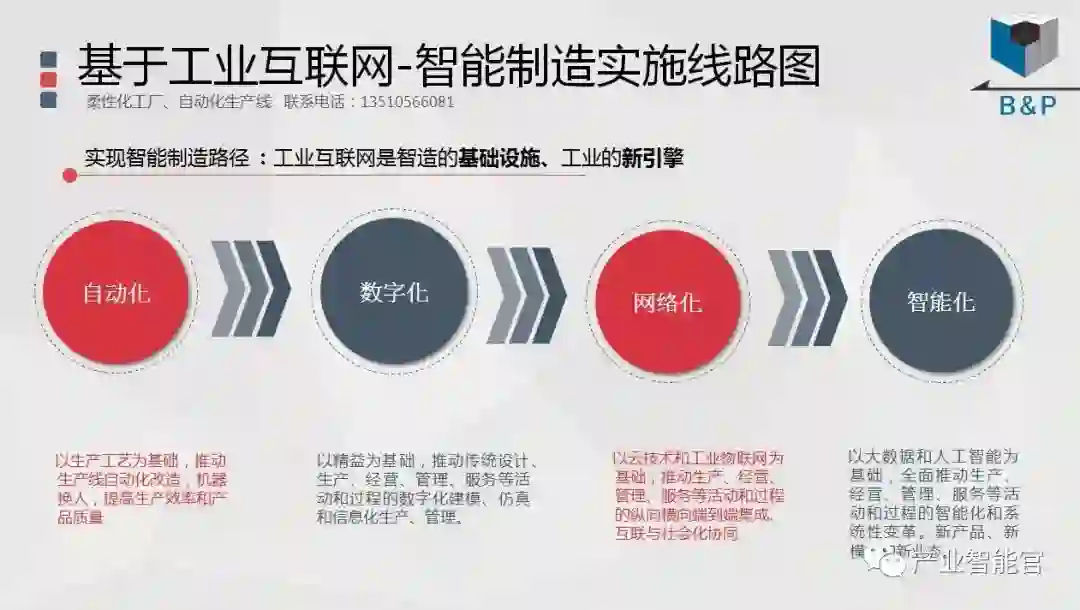

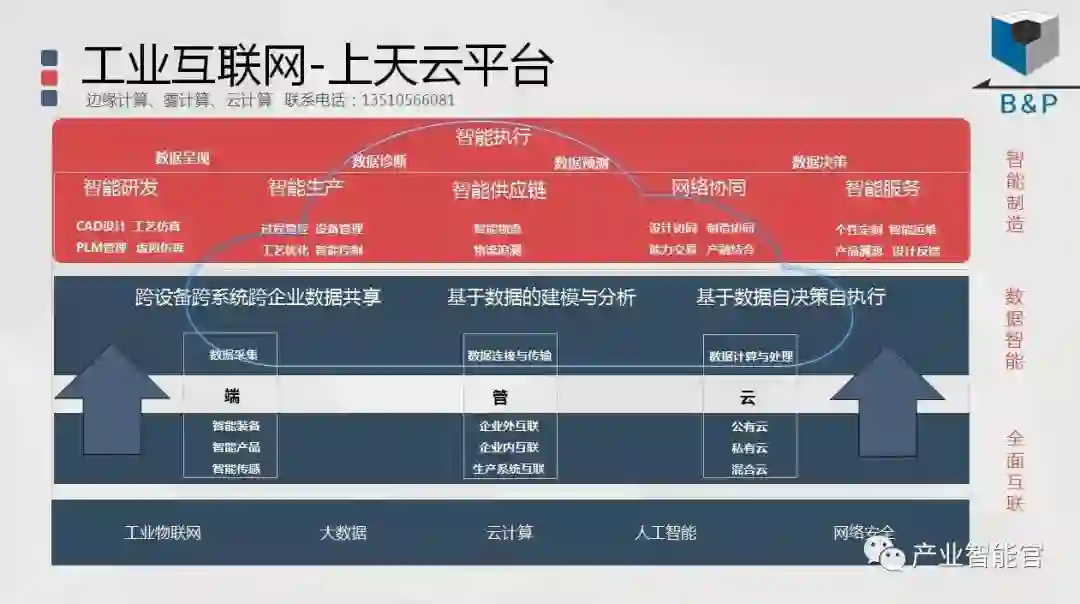
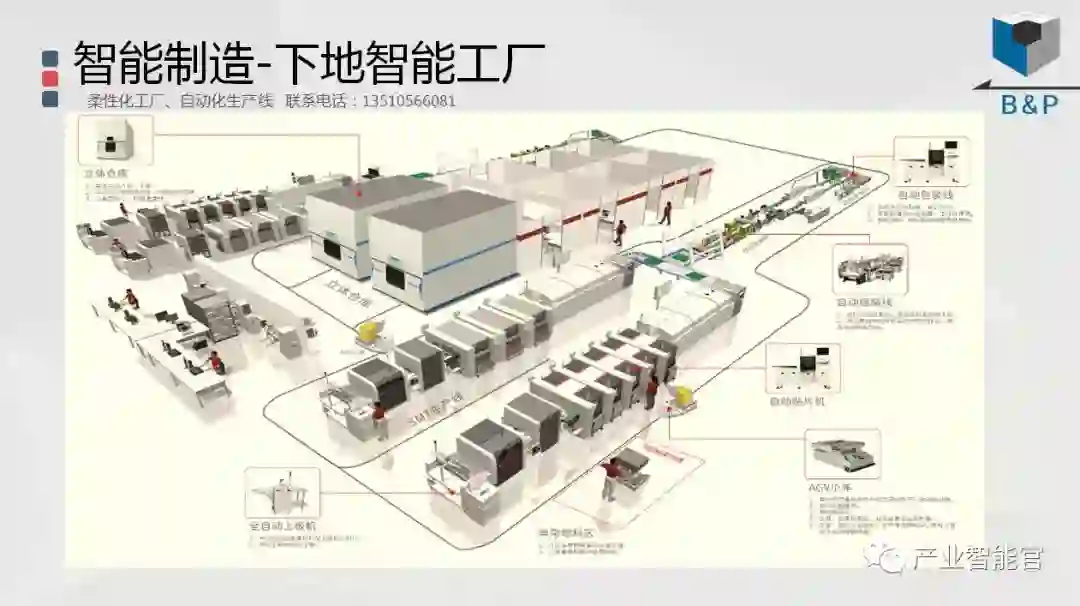
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




