文本挖掘之特征选择(python 实现)

数据挖掘入门与实战 公众号: datadw
机器学习算法的空间、时间复杂度依赖于输入数据的规模,维度规约(Dimensionality reduction)则是一种被用于降低输入数据维数的方法。维度规约可以分为两类:
特征选择(feature selection),从原始的d维空间中,选择为我们提供信息最多的k个维(这k个维属于原始空间的子集)
特征提取(feature extraction),将原始的d维空间映射到k维空间中(新的k维空间不输入原始空间的子集)
在文本挖掘与文本分类的有关问题中,常采用特征选择方法。原因是文本的特征一般都是单词(term),具有语义信息,使用特征选择找出的k维子集,仍然是单词作为特征,保留了语义信息,而特征提取则找k维新空间,将会丧失了语义信息。
对于一个语料而言,我们可以统计的信息包括文档频率和文档类比例,所有的特征选择方法均依赖于这两个统计量,目前,文本的特征选择方法主要有:DF, MI, IG, CHI,WLLR,WFO六种。
为了方便描述,我们首先一些概率上的定义:
p(t):一篇文档x包含特征词t的概率。
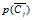
p(Ci|t):已知文档x的包括某个特征词t条件下,该文档属于Ci的概率
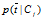
类似的其他的一些概率如p(Ci), 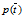
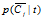
为了估计这些概率,我们需要通过统计训练样本的相关频率信息,如下表:
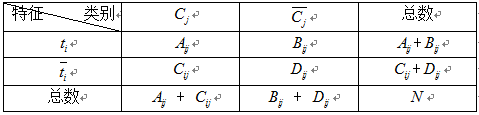
其中:
Aij: 包含特征词ti,并且类别属于Cj的文档数量 Bij: 包含特征词ti,并且类别属于不Cj的文档数量
Cij:不包含特征词ti,并且类别属于Cj的文档数量 Dij:不包含特征词ti,并且类别属于不Cj的文档数量
Aij + Bij: 包含特征词ti的文档数量 Cij + Dij:不包含特征词ti的文档数量
Aij + Cij:Cj类的文档数量数据 Bij + Dij:非Cj类的文档数量数据
Aij + Bij + Cij + Dij = N :语料中所有文档数量。
有了这些统计量,有关概率的估算就变得容易,如:
p(ti) = (Aij + Bij) / N; p(Cj) = (Aij + Cij) / N;
p(Cj|tj) = Aij / (Aij + Bij)
......类似的一些概率计算可以依照上表计算。
介绍了事情发展的前因,现在进入正题:常见的四种特征选择方法如何计算。
1)DF(Document Frequency)
DF:统计特征词出现的文档数量,用来衡量某个特征词的重要性,DF的定义如下:
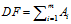
DF的动机是,如果某些特征词在文档中经常出现,那么这个词就可能很重要。而对于在文档中出现很少(如仅在语料中出现1次)特征词,携带了很少的信息量,甚至是"噪声",这些特征词,对分类器学习影响也是很小。
DF特征选择方法属于无监督的学习算法(也有将其改成有监督的算法,但是大部分情况都作为无监督算法使用),仅考虑了频率因素而没有考虑类别因素,因此,DF算法的将会引入一些没有意义的词。如中文的"的"、"是", "个"等,常常具有很高的DF得分,但是,对分类并没有多大的意义。
2)MI(Mutual Information)
互信息法用于衡量特征词与文档类别直接的信息量,互信息法的定义如下:
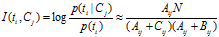
继续推导MI的定义公式:
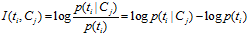
从上面的公式上看出:如果某个特征词的频率很低,那么互信息得分就会很大,因此互信息法倾向"低频"的特征词。相对的词频很高的词,得分就会变低,如果这词携带了很高的信息量,互信息法就会变得低效。
3)IG(Information Gain)
信息增益法,通过某个特征词的缺失与存在的两种情况下,语料中前后信息的增加,衡量某个特征词的重要性。
信息增益的定义如下:
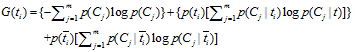
依据IG的定义,每个特征词ti的IG得分前面一部分:
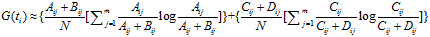
IG与MI存在关系:
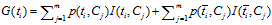
因此,IG方式实际上就是互信息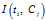
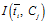
4)CHI(Chi-square)
CHI特征选择算法利用了统计学中的"假设检验"的基本思想:首先假设特征词与类别直接是不相关的,如果利用CHI分布计算出的检验值偏离阈值越大,那么更有信心否定原假设,接受原假设的备则假设:特征词与类别有着很高的关联度。CHI的定义如下:
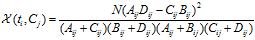
对于一个给定的语料而言,文档的总数N以及Cj类文档的数量,非Cj类文档的数量,他们都是一个定值,因此CHI的计算公式可以简化为:
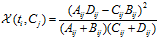
CHI特征选择方法,综合考虑文档频率与类别比例两个因素
5)WLLR(Weighted Log Likelihood Ration)
WLLR特征选择方法的定义如下:
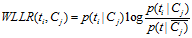
计算公式如下:
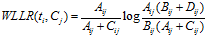
6)WFO(Weighted Frequency and Odds)
最后一个介绍的算法,是由苏大李寿山老师提出的算法。通过以上的五种算法的分析,李寿山老师认为,"好"的特征应该有以下特点:
好的特征应该有较高的文档频率
好的特征应该有较高的文档类别比例
WFO的算法定义如下:
如果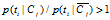
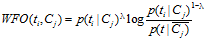
否则:
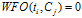
不同的语料,一般来说文档词频与文档的类别比例起的作用应该是不一样的,WFO方法可以通过调整参数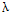
介绍完理论部分,就要给出代码了。可以利用sklearn开源工具,自然先首先sklearn工具,可惜的是sklearn文本的特征选择方法仅提供了CHI一种。为此在sklearn框架下,尝试自己编写这些特征选择方法的代码,自己动手,丰衣足食。
笔者实现了三种特征选择方法:IG,MI和WLLR,看官如果对其他特征选择方法感兴趣,可以尝试实现一下~ 好了,啥也不说了,上代码,特征选择模块代码:

输出的结果:
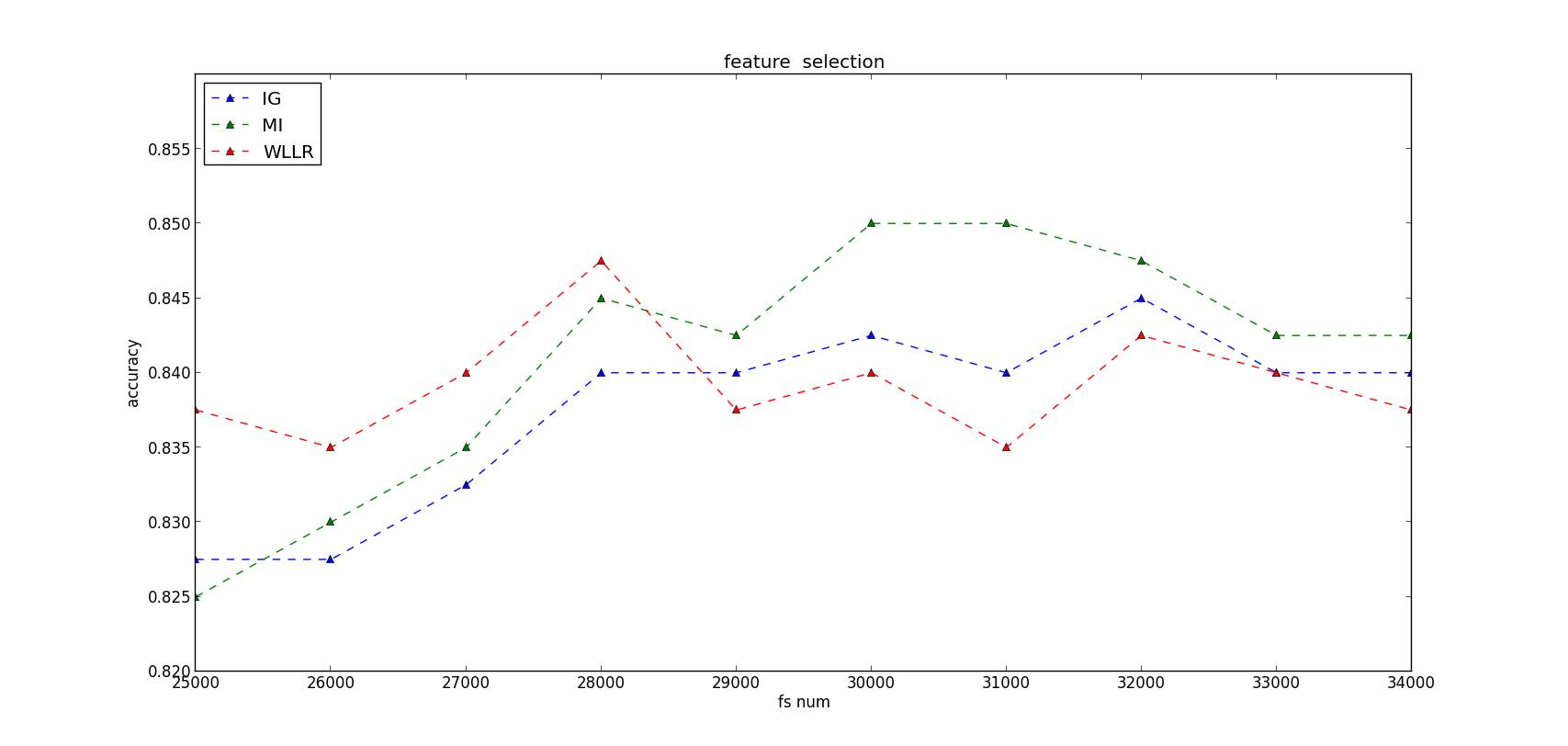
从上面的图看出:分类的性能随着特征选择的数量的增加,呈现“凸”形趋势:1)在特征数量较少的情况下,不断增加特征的数量,有利于提高分类器的性能,呈现“上升”趋势;2)随着特征数量的不断增加,将会引入一些不重要的特征,甚至是噪声,因此,分类器的性能将会呈现“下降”的趋势。这张“凸”形趋势体现出了特征选择的重要性:选择出重要的特征,并降低噪声,提高算法的泛化能力。
人工智能AI与大数据技术实战
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注





