文本数据分析(三):用Python实现文本数据预处理
编者按:在前两篇文章中,我们首先讨论了处理文本数据的基本框架,然后详细说明了文本数据预处理的步骤。今天,作者Matthew Mayo将为大家带来用Python进行实际预处理的案例。
相关阅读:文本数据分析(一):基本框架
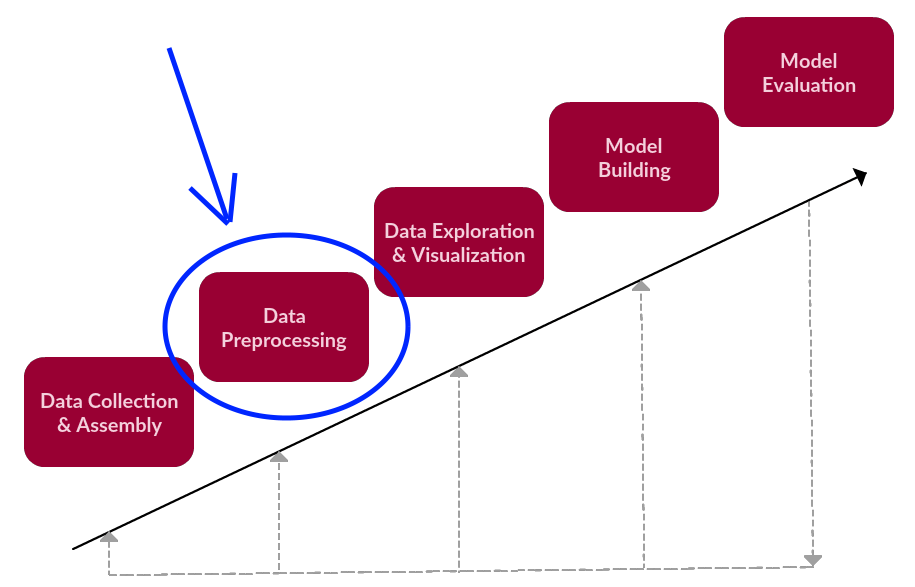
我们的目标是从文本的主体(一个冗长、未经处理的单一字符串)中,得到一个或几个经过清洗的tokens列表,用于进一步的文本挖掘或自然语言处理任务。
首先,我们输入以下代码。
import re, string, unicodedata
import nltk
import contractions
import inflect
from bs4 import BeautifulSoup
from nltk import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import LancasterStemmer, WordNetLemmatizer
除了标准的Python库外,我们还用了以下工具:
NLTK:自然语言工具箱是Python生态系统中最著名、最广泛的NLP库之一,它能用于各种任务,比如标记化、词干提取、词性标注等等。
BeautifulSoup:这款工具在从HTML和XML文件中提取数据中非常有用。
Inflect:这是一个简单的库,用于复数、单数名词、序数词和不定冠词的生成以及将数字转换为单词等任务。
Contractions:这个库也很简单,只是用于展开缩写。
如果你只安装了NLTK,没有下载其他数据的话,点击:https://www.nltk.org/data.html。
我们需要一些文本样本,刚开始我们选用一些小型、自制的文本输入进去,从而能轻易地了解每一步的结果。
sample = """<h1>Title Goes Here</h1>
<b>Bolded Text</b>
<i>Italicized Text</i>
<img src="this should all be gone"/>
<a href="this will be gone, too">But this will still be here!</a>
I run. He ran. She is running. Will they stop running?
I talked. She was talking. They talked to them about running. Who ran to the talking runner?
[Some text we don't want to keep is in here]
¡Sebastián, Nicolás, Alejandro and Jéronimo are going to the store tomorrow morning!
something... is! wrong() with.,; this :: sentence.
I can't do this anymore. I didn't know them. Why couldn't you have dinner at the restaurant?
My favorite movie franchises, in order: Indiana Jones; Marvel Cinematic Universe; Star Wars; Back to the Future; Harry Potter.
Don't do it.... Just don't. Billy! I know what you're doing. This is a great little house you've got here.
[This is some other unwanted text]
John: "Well, well, well."
James: "There, there. There, there."
There are a lot of reasons not to do this. There are 101 reasons not to do it. 1000000 reasons, actually.
I have to go get 2 tutus from 2 different stores, too.
22 45 1067 445
{{Here is some stuff inside of double curly braces.}}
{Here is more stuff in single curly braces.}
[DELETE]
</body>
</html>"""
这虽然是个小数据集,但是没有出错。我们在这里预处理的步骤是完全可以转移的。
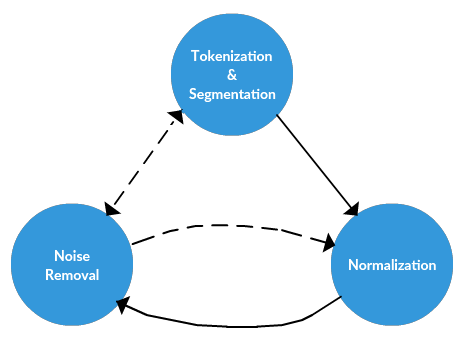
噪声消除
在这里,我们简单地吧噪声消除定义成在标记化之前进行的特定文本的归一化。我们通常所说的标记化和归一化是与任务无关的,而噪声消除与任务的联系更紧密。其中的任务包括:
删除文件的标题、页脚
删除HTML、XML等标记和元数据
从其他格式(如JSON)或数据库中提取有价值的数据
正如你所认为的,噪声消除和数据收集之间的界线很模糊,由于噪声消除与其他步骤联系紧密,因此它必须在其他步骤之前进行。例如,从JSON结构中获取的文本显然要在标记化之前消除噪音。
在我们的数据预处理过程中,我们会用BeautifulSoup库清除HTML标记,并用正则表达式删除打开和封闭的双括号以及它们之间的任何内容(通过样本我们认为这是必要的)。
def strip_html(text):
soup = BeautifulSoup(text, "html.parser")
return soup.get_text()
def remove_between_square_brackets(text):
return re.sub('\[[^]]*\]', '', text)
def denoise_text(text):
text = strip_html(text)
text = remove_between_square_brackets(text)
return text
sample = denoise_text(sample)
print(sample)
尽管没有强制要在标记化前的阶段做这个(你会发现这种表示适合相对顺序相对灵活的文本数据预处理任务),这时将缩写替换成原型更有帮助,因为我们的词语标注器会把“didnt”这样的单词分成“did”和“n’t”。虽然在稍后也可以补做这种标记化,但提前完成更容易也更直接。
def replace_contractions(text):
"""Replace contractions in string of text"""
return contractions.fix(text)
sample = replace_contractions(sample)
print(sample)
下面是样本消除噪音之后的结果。
Title Goes Here
Bolded Text
Italicized Text
But this will still be here!
I run. He ran. She is running. Will they stop running?
I talked. She was talking. They talked to them about running. Who ran to the talking runner?
¡Sebastián, Nicolás, Alejandro and Jéronimo are going to the store tomorrow morning!
something... is! wrong() with.,; this :: sentence.
I cannot do this anymore. I did not know them. Why could not you have dinner at the restaurant?
My favorite movie franchises, in order: Indiana Jones; Marvel Cinematic Universe; Star Wars; Back to the Future; Harry Potter.
do not do it.... Just do not. Billy! I know what you are doing. This is a great little house you have got here.
John: "Well, well, well."
James: "There, there. There, there."
There are a lot of reasons not to do this. There are 101 reasons not to do it. 1000000 reasons, actually.
I have to go get 2 tutus from 2 different stores, too.
22 45 1067 445
{{Here is some stuff inside of double curly braces.}}
{Here is more stuff in single curly braces.}
标记化
标记化是将文本中较长的字符串分割成较小的部分,或者tokens。大段文字会被分成句子,句子被标记成单词等等,只有这样才能进行下一步处理。标记化也被称为文本分割或语义分析,在我们的任务中,我们将把样本分割成单词列表。这是用NTLK的word_tokenize( )功能实现的。
words = nltk.word_tokenize(sample)
print(words)
以下是我们的单词tokens:
['Title', 'Goes', 'Here', 'Bolded', 'Text', 'Italicized', 'Text', 'But', 'this', 'will', 'still',
'be', 'here', '!', 'I', 'run', '.', 'He', 'ran', '.', 'She', 'is', 'running', '.', 'Will', 'they',
'stop', 'running', '?', 'I', 'talked', '.', 'She', 'was', 'talking', '.', 'They', 'talked', 'to', 'them',
'about', 'running', '.', 'Who', 'ran', 'to', 'the', 'talking', 'runner', '?', '¡Sebastián', ',',
'Nicolás', ',', 'Alejandro', 'and', 'Jéronimo', 'are', 'going', 'tot', 'he', 'store', 'tomorrow',
'morning', '!', 'something', '...', 'is', '!', 'wrong', '(', ')', 'with.', ',', ';', 'this', ':', ':',
'sentence', '.', 'I', 'can', 'not', 'do', 'this', 'anymore', '.', 'I', 'did', 'not', 'know', 'them', '.',
'Why', 'could', 'not', 'you', 'have', 'dinner', 'at', 'the', 'restaurant', '?', 'My', 'favorite',
'movie', 'franchises', ',', 'in', 'order', ':', 'Indiana', 'Jones', ';', 'Star', 'Wars', ';', 'Marvel',
'Cinematic', 'Universe', ';', 'Back', 'to', 'the', 'Future', ';', 'Harry', 'Potter', '.', 'do', 'not',
'do', 'it', '...', '.', 'Just', 'do', 'not', '.', 'Billy', '!', 'I', 'know', 'what', 'you', 'are',
'doing', '.', 'This', 'is', 'a', 'great', 'little', 'house', 'you', 'have', 'got', 'here', '.', 'John',
':', '``', 'Well', ',', 'well', ',', 'well', '.', "''", 'James', ':', '``', 'There', ',', 'there', '.',
'There', ',', 'there', '.', "''", 'There', 'are', 'a', 'lot', 'of', 'reasons', 'not', 'to', 'do', 'this',
'.', 'There', 'are', '101', 'reasons', 'not', 'to', 'do', 'it', '.', '1000000', 'reasons', ',',
'actually', '.', 'I', 'have', 'to', 'go', 'get', '2', 'tutus', 'from', '2', 'different', 'stores', ',',
'too', '.', '22', '45', '1067', '445', '{', '{', 'Here', 'is', 'some', 'stuff', 'inside', 'of', 'double',
'curly', 'braces', '.', '}', '}', '{', 'Here', 'is', 'more', 'stuff', 'in', 'single', 'curly', 'braces',
'.', '}']
归一化
归一化指的是将所有文本放在同一水平上,例如将所用文本转换成同样的格式(小写或大写),删除标点符号,将数字转换成对应的文字等等。归一化的目的就是统一对文本进行处理。
在我们之前的文章中提到,归一化涉及3个必要的步骤:词干提取、词形还原和其他。记住,在标记化完成之后,我们就不是将文本作为工作对象了,而是单词。以下是归一化功能的效果,功能的名称和评论应该表明它的目的。
def remove_non_ascii(words):
"""Remove non-ASCII characters from list of tokenized words"""
new_words = []
for word in words:
new_word = unicodedata.normalize('NFKD', word).encode('ascii', 'ignore').decode('utf-8', 'ignore')
new_words.append(new_word)
return new_words
def to_lowercase(words):
"""Convert all characters to lowercase from list of tokenized words"""
new_words = []
for word in words:
new_word = word.lower()
new_words.append(new_word)
return new_words
def remove_punctuation(words):
"""Remove punctuation from list of tokenized words"""
new_words = []
for word in words:
new_word = re.sub(r'[^\w\s]', '', word)
if new_word != '':
new_words.append(new_word)
return new_words
def replace_numbers(words):
"""Replace all interger occurrences in list of tokenized words with textual representation"""
p = inflect.engine()
new_words = []
for word in words:
if word.isdigit():
new_word = p.number_to_words(word)
new_words.append(new_word)
else:
new_words.append(word)
return new_words
def remove_stopwords(words):
"""Remove stop words from list of tokenized words"""
new_words = []
for word in words:
if word not in stopwords.words('english'):
new_words.append(word)
return new_words
def stem_words(words):
"""Stem words in list of tokenized words"""
stemmer = LancasterStemmer()
stems = []
for word in words:
stem = stemmer.stem(word)
stems.append(stem)
return stems
def lemmatize_verbs(words):
"""Lemmatize verbs in list of tokenized words"""
lemmatizer = WordNetLemmatizer()
lemmas = []
for word in words:
lemma = lemmatizer.lemmatize(word, pos='v')
lemmas.append(lemma)
return lemmas
def normalize(words):
words = remove_non_ascii(words)
words = to_lowercase(words)
words = remove_punctuation(words)
words = replace_numbers(words)
words = remove_stopwords(words)
return words
words = normalize(words)
print(words)
进行归一化之后:
['title', 'goes', 'bolded', 'text', 'italicized', 'text', 'still', 'run', 'ran', 'running', 'stop',
'running', 'talked', 'talking', 'talked', 'running', 'ran', 'talking', 'runner', 'sebastian', 'nicolas',
'alejandro', 'jeronimo', 'going', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence',
'anymore', 'know', 'could', 'dinner', 'restaurant', 'favorite', 'movie', 'franchises', 'order',
'indiana', 'jones', 'marvel', 'cinematic', 'universe', 'star', 'wars', 'back', 'future', 'harry',
'potter', 'billy', 'know', 'great', 'little', 'house', 'got', 'john', 'well', 'well', 'well', 'james',
'lot', 'reasons', 'one hundred and one', 'reasons', 'one million', 'reasons', 'actually', 'go', 'get',
'two', 'tutus', 'two', 'different', 'stores', 'twenty-two', 'forty-five', 'one thousand and sixty-seven',
'four hundred and forty-five', 'stuff', 'inside', 'double', 'curly', 'braces', 'stuff', 'single',
'curly', 'braces']
进行词干提取和词形变化之后:
def stem_and_lemmatize(words):
stems = stem_words(words)
lemmas = lemmatize_verbs(words)
return stems, lemmas
stems, lemmas = stem_and_lemmatize(words)
print('Stemmed:\n', stems)
print('\nLemmatized:\n', lemmas)
最后生成两种新的列表,其中一个是提取了词干的tokens,另一个是只有对应的动词的tokens。根据接下来的NLP任务,你可以选择其中一个进行处理。
Stemmed:
['titl', 'goe', 'bold', 'text', 'it', 'text', 'stil', 'run', 'ran', 'run', 'stop', 'run', 'talk',
'talk', 'talk', 'run', 'ran', 'talk', 'run', 'sebast', 'nicola', 'alejandro', 'jeronimo', 'going',
'stor', 'tomorrow', 'morn', 'someth', 'wrong', 'sent', 'anym', 'know', 'could', 'din', 'resta',
'favorit', 'movy', 'franch', 'ord', 'indian', 'jon', 'marvel', 'cinem', 'univers', 'star', 'war', 'back',
'fut', 'harry', 'pot', 'bil', 'know', 'gre', 'littl', 'hous', 'got', 'john', 'wel', 'wel', 'wel', 'jam',
'lot', 'reason', 'one hundred and on', 'reason', 'one million', 'reason', 'act', 'go', 'get', 'two',
'tut', 'two', 'diff', 'stor', 'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred
and forty-five', 'stuff', 'insid', 'doubl', 'cur', 'brac', 'stuff', 'singl', 'cur', 'brac']
Lemmatized:
['title', 'go', 'bolded', 'text', 'italicize', 'text', 'still', 'run', 'run', 'run', 'stop', 'run',
'talk', 'talk', 'talk', 'run', 'run', 'talk', 'runner', 'sebastian', 'nicolas', 'alejandro', 'jeronimo',
'go', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence', 'anymore', 'know', 'could',
'dinner', 'restaurant', 'favorite', 'movie', 'franchise', 'order', 'indiana', 'jones', 'marvel',
'cinematic', 'universe', 'star', 'war', 'back', 'future', 'harry', 'potter', 'billy', 'know', 'great',
'little', 'house', 'get', 'john', 'well', 'well', 'well', 'jam', 'lot', 'reason', 'one hundred and one',
'reason', 'one million', 'reason', 'actually', 'go', 'get', 'two', 'tutus', 'two', 'different', 'store',
'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred and forty-five', 'stuff',
'inside', 'double', 'curly', 'brace', 'stuff', 'single', 'curly', 'brace']
关于到底是采用词干提取还是词形变化的结果,这里有个讨论:https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
这就是用Python进行简单的文本数据预处理的方法,我建议你动手试一试。在下篇文章中,我们会用同样方法进行预处理,然后继续实际文本数据的任务介绍。敬请期待!
原文地址:https://www.kdnuggets.com/2018/03/text-data-preprocessing-walkthrough-python.html