即插即用,涨点明显!FPT:特征金字塔Transformer


简介
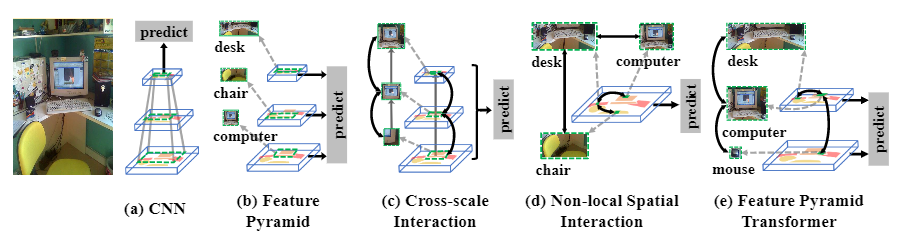
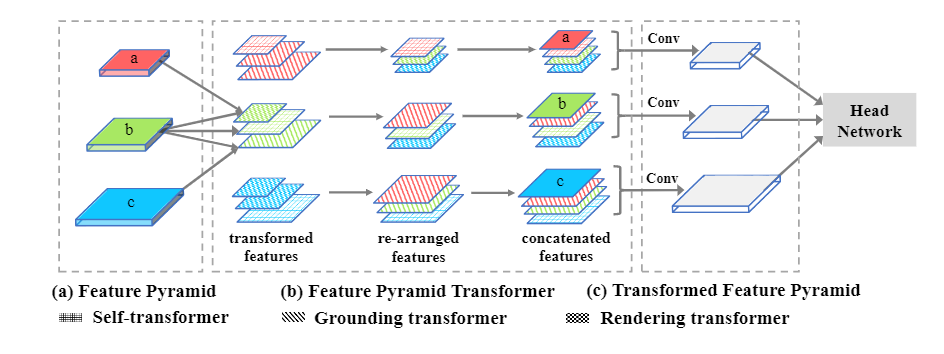
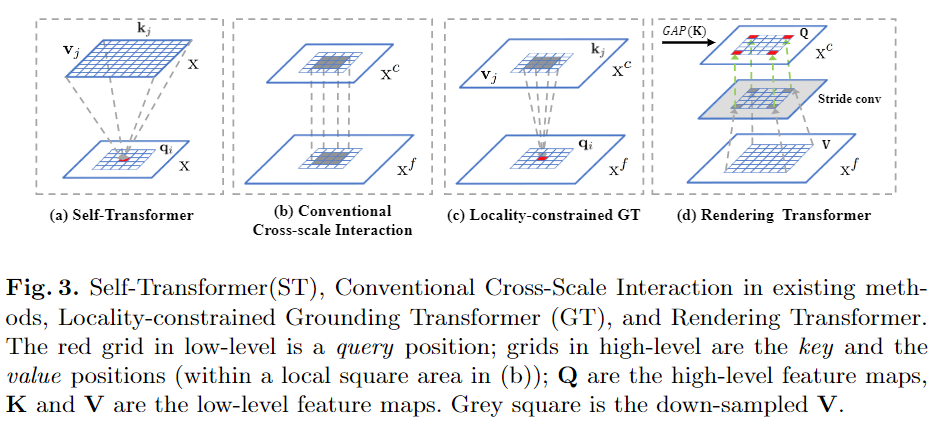
本文方法
1、Non-Local Interaction Revisited
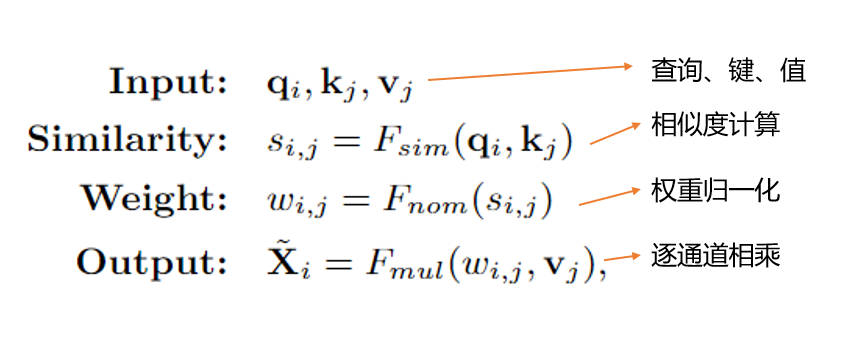
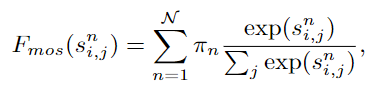

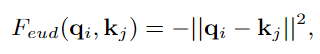

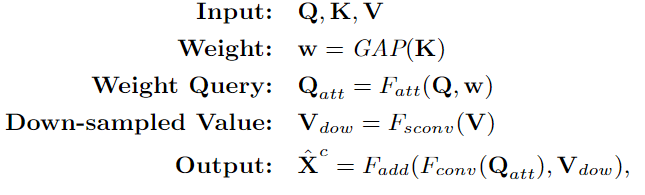
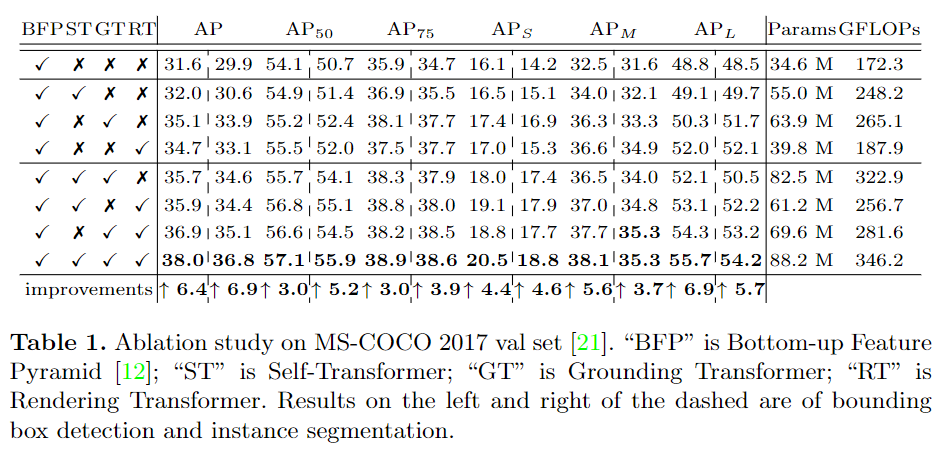
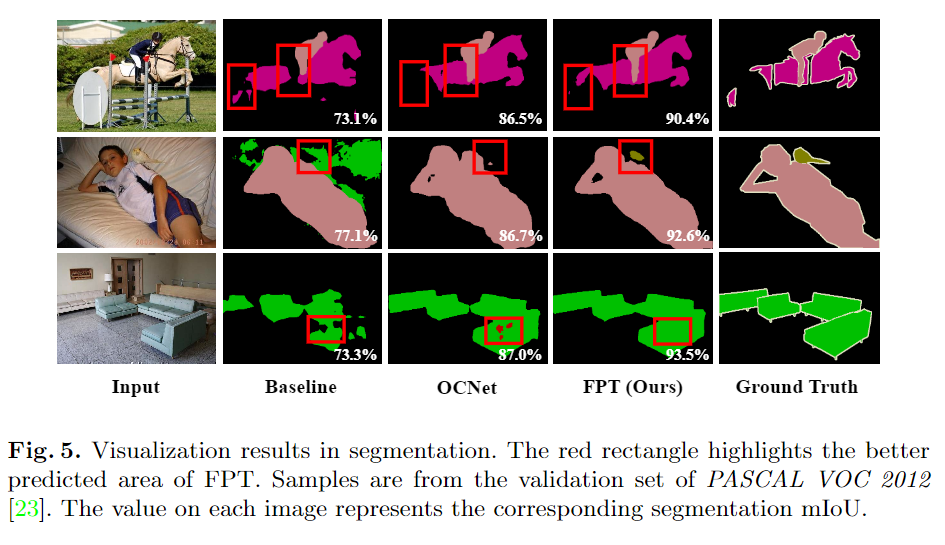
实验与结果
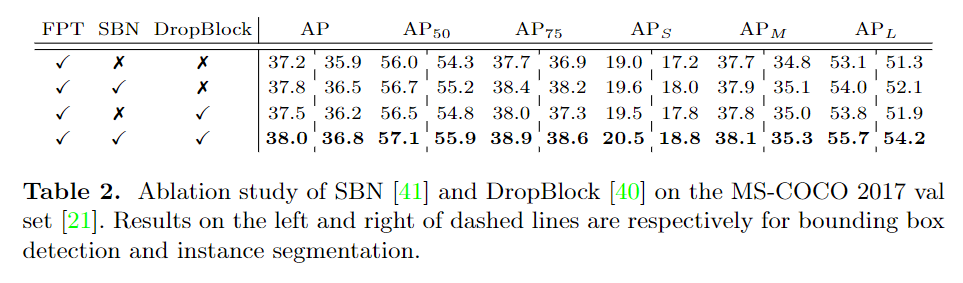
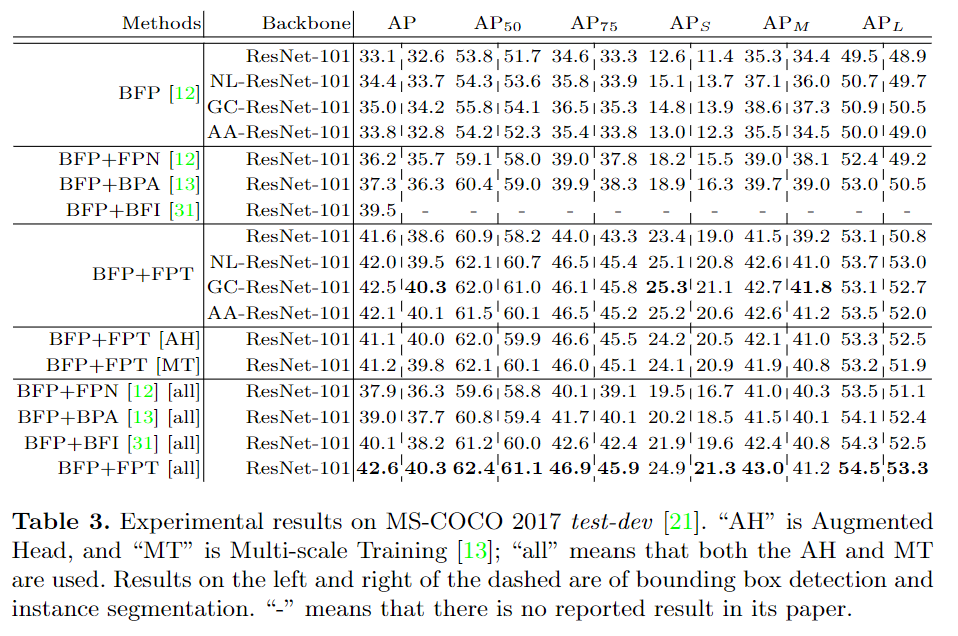
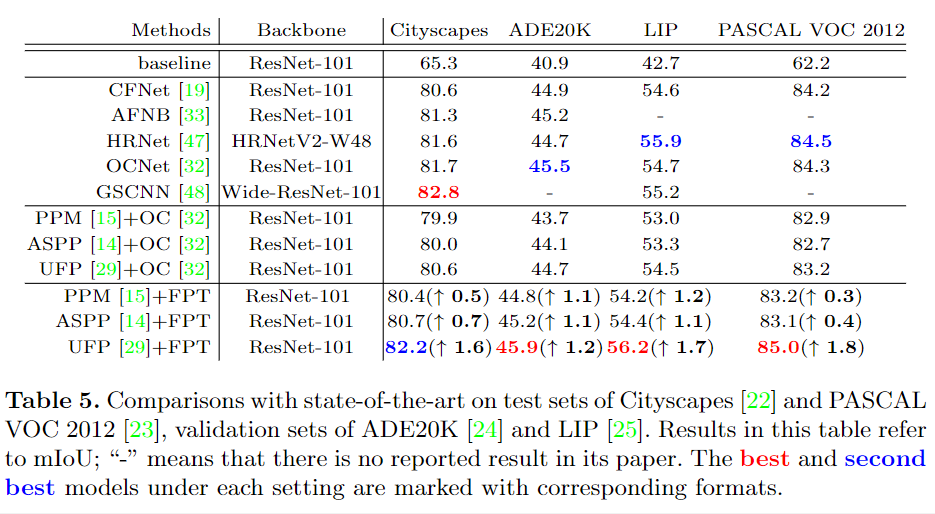
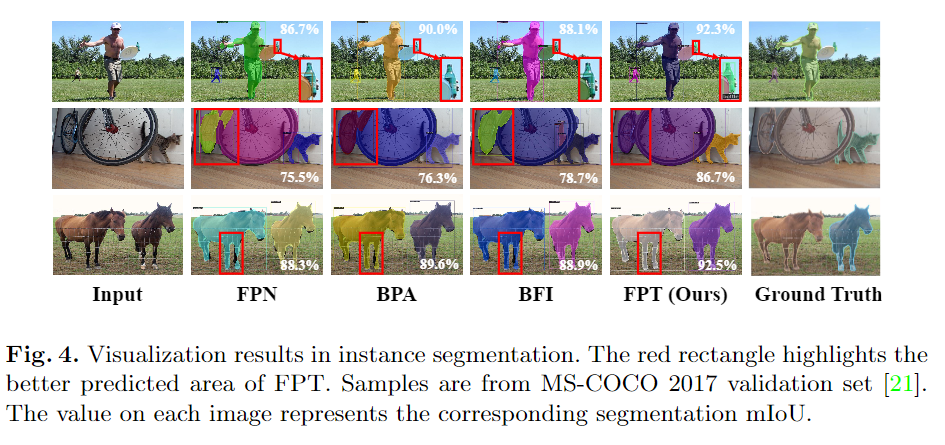


NeurIPS 2020论文接收列表已出,欢迎大家投稿让更多的人了解你们的工作~


点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容

FPT:International Conference on Field-Programmable Technology。
Explanation:现场可编程技术国际会议。
Publisher:IEEE。
SIT: http://dblp.uni-trier.de/db/conf/fpt/
Arxiv
7+阅读 · 2020年9月2日
Arxiv
7+阅读 · 2019年4月16日



相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2020年9月2日
Arxiv
7+阅读 · 2019年4月16日