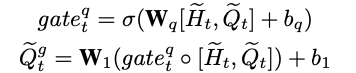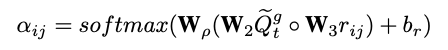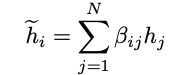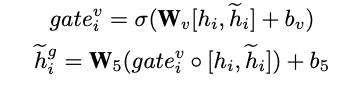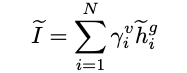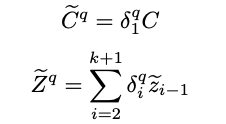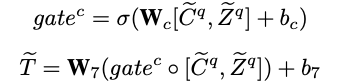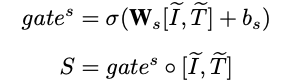作者 | 蒋萧泽
责编 | Camel
论文标题:
DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
文章作者:
蒋萧泽、于静、秦曾昌、张星星、吴琦等,由北京航空航天大学、中科院信工所、微软亚研院和阿德莱德大学合作完成。本论文已被AAAI 2020 接收。
论文链接:
https://arxiv.org/abs/1911.07251
代码链接:
https://github.com/JXZe/DualVD
近年来,跨模态研究引发了广泛关注并取得显著进展,综合分析语言和视觉等不同模态的信息对模拟现实社会中人类对于信息的认知过程具有重要意义。
视觉对话问题是视觉问答任务的衍生任务
,不同的是,视觉对话任务需要根据图像、历史对话回答当前问题,涉及多个问题且涵盖了可能与任何对象、关系或语义相关的广泛视觉内容,因此视觉对话需要根据对话的推进,不断调整关注区域使之有效地捕捉问题所涉及的视觉信息,针对不同问题对图像进行自适应的关注。
如下图 1 所示「Q1: Is the man on the skateboard?」, 需要关注「man」,「skateboard」等信息,当问题变换为「Q5: Is the sky in the picture」时,需要将关注区域转移至「sky」。问题 Q1 和 Q5 主要关注在表层(appearance-level)信息问题,而 Q4「Is he young or older」则需要进一步地视觉推理得到更高层的语义信息。因此,
如何根据问题进行自适应调整并有效地捕捉视觉信息是视觉对话问题中的重要挑战之一。
![]() 图1 DualVD模型基本思想。(左)模型输入;(右)视觉和语义信息理解模块。
根据认知学中的双向编码理论(Dual-Coding Theory), 人类认知信息的过程包含视觉表象和关联文本,人的大脑在检索关于某个概念的信息时会综合检索视觉信息以及语言信息,这种方式能够加强大脑的理解以及记忆能力。
图1 DualVD模型基本思想。(左)模型输入;(右)视觉和语义信息理解模块。
根据认知学中的双向编码理论(Dual-Coding Theory), 人类认知信息的过程包含视觉表象和关联文本,人的大脑在检索关于某个概念的信息时会综合检索视觉信息以及语言信息,这种方式能够加强大脑的理解以及记忆能力。
作者根据此理论,
提出从视觉和语义两个维度刻画视觉对话任务中图象信息的新框架
:语义模块描述图像的局部以及全局的高层语义信息,视觉模块描述图像中的对象以及对象之间的视觉关系。基于此框架,作者提出自适应视觉选择模型 DualVD(Duel Encoding Visual Dialog),分别进行模态内与模态之前的信息选择。
视觉对话任务:
根据给定图像 I,图像描述 C 和 t-1 轮的对话历史 Ht={C,(Q1,A1),...,(Qt-1,At-1)}, 以及当前轮问题 Q 等信息,从 100 个候选答案 A=(A1,A2,...,A100) 中选择针对当前轮问题 Q 的最佳答案。
作者为解决视觉对话任务所提出的 DualVD 模型框架如图 2 所示,
主要分为 Visual-Semantic Dual Encoding 和 Adaptive Visual-Semantic Knowledge Selection 两部分。
![]()
1、Visual-Semantic Dual Encoding
从视觉以及语义两个维度刻画视觉对话任务中图象信息的新框架,其中语义信息采用多层次语义描述表示,视觉信息采用场景图表示。
Scene Graph Construction
:
利用场景图表示每一张图像,并捕捉图像之间目标对象以及对象间的视觉关系信息。作者采用 Faster-RCNN 提取出图像中 N 个目标区域,并将其表示为场景图上的结点,结点 i 的特征定义为 hi;采用 Zhang 等提出的视觉关系编码器在 GQA 数据集上进行预训练,用关系向量表示图像中的任意两个目标区域之间的视觉关系,并将其表示为场景图上的边,结点 i 和结点 j 之间的关系向量定义为 r_ij。目前现有的工作大多采用关系类别来表示场景图的边,相比而言作者利用关系向量表示场景图的边的方法能考虑到视觉关系的多样性,歧义性,更准确地表达目标对象之前的视觉关系。
Multi-level Image Captions
:
将每幅图像表示为多层级的语义描述,同时刻画图像的局部和全局语义信息。相比于视觉特征,语义描述通过自然语言的信息表达出更高的语义层次,能够更加直接地为问题提供线索,避免了不同模态数据之间的「异构鸿沟」。作者采用数据集的图像描述作为全局语义信息,有助于回答探索场景的问题;采用 Feifei Li 等提出的 DenseCap 提取一组局部层次语义信息,包括对象属性,与对象相关的先验知识,以及对象之间的关系等。对全局和局部的语义信息采用不同的 LSTM 提取特征。
2、Adaptive Visual-Semantic Knowledge Selection
在视觉语义图像表示的基础上,作者提出了一种新的特征选择框架,从图像中自适应地选择与问题相关的信息。在当前问题的指导下,将特征选择过程设计为分层模式:模态内选择首先从视觉模块(Visual Module)和语义模块(Semantic Module)分别提取视觉信息和语义信息;然后通过选择性的视觉-语义融合(Selective visual-semantic fusion),汇聚视觉模块和语义模块中问题相关的线索。
这种层次结构框架的优点是可以显式地揭示渐进特征选择模式。
1)Question-Guided Relation Attention
:
基于问题引导,获取与问题最相关的视觉关系。首先,从对话历史中选择与问题相关的信息,通过门控机制更新问题表示,定义为:
![]()
基于问题新表示Qgt的引导,计算场景图中每个关系的注意力:
![]()
基于注意力aij,更新场景图中每个关系的嵌入表示:
![]()
2) Question-Guided Graph Convolution
:
基于问题引导,通过基于关系的图注意网络聚集目标对象的邻域和对应关系的信息,进一步更新每个目标对象的表示。首先,根据场景图中的结点,计算该结点i对邻居结点j之前存在对应关系rij条件下的注意力:
![]()
其次,基于注意力βij更新场景图中每个结点的特征表示:
![]()
3) Object-relation Information fusion:
在视觉对话中,目标对象的视觉表层信息和视觉关系信息有助于推断答案。本模块中自适应地将原结点和感知关系结点通过门控机制进行融合得到问题相关的目标对象特征:
![]()
为增强原始目标区域的视觉信息提供的线索以及当前问题的影响,作者基于原始目标区域的注意力分布,融合目标区域表示得到增强的图像表示I:
![]()
![]()
该模块通过问题引导语义注意模块和全局-局部信息融合模块,从全局和局部语义描述中选择和合并与问题相关的语义信息。
1)Question-guided semantic attention:
基于问题引导,对全局和局部语义描述计算注意力:
2)Global-local information fusion:
采用门控机制自适应地融合全局语义表示和局部语义表示
3)Selective Visual-Semantic Fusion:
当被提问时,模型能够检索相关的视觉信息、语言信息或综合考虑上述两种信息。作者采用门控机制控制两种信息源对于回答问题的贡献,并获得最终的视觉知识表示:
3. Late Fusion and Discriminative Decoder
整个模型由 Late Fusion encoder 和 Discriminative decoder 组成。解码时,模型首先将每个部分嵌入一个对话元组中 D = {I; Ht; Qt},然后将具有视觉知识表示的 Ht 和 Qt 连接到一个联合的输入中进行答案预测。解码器对 100 个候选答案进行排序。该模型还可以应用于更复杂的解码器和融合策略,如记忆网络、协同注意等。
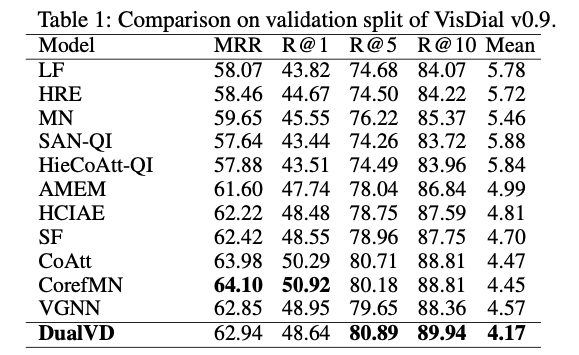
在 VisDial v0.9 和 VisDial v1.0 上对模型的效果进行了验证。与现有算法相比,DualVD 的结果超过现有大多数模型,略低于采用了多步推理和复杂 attention 机制的模型。
![]()
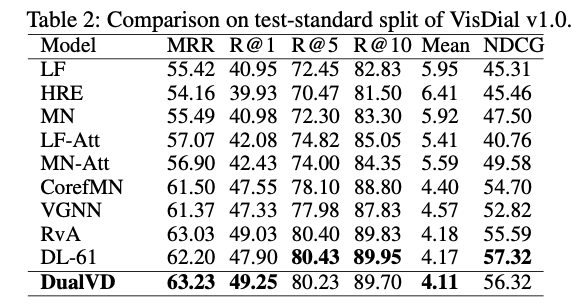
![]() VisDial v1.0 验证集的消融研究利用了 DualVD 主要成分的影响。作者使用相同的 Discriminative decoder 做了充分的消融实验验证模型各个关键模块的作用, 如 ObjRep(目标特征)、RelRep(关系特征)、VisNoRel(视觉模块去掉关系嵌入表示) 、VisMod(完整视觉模块)、GlCap(全局语义)、LoCap(局部语义)、SemMod(语义模块)、w/o ElMo (不用预训练语言模型)、DualVD(完整模型)。
VisDial v1.0 验证集的消融研究利用了 DualVD 主要成分的影响。作者使用相同的 Discriminative decoder 做了充分的消融实验验证模型各个关键模块的作用, 如 ObjRep(目标特征)、RelRep(关系特征)、VisNoRel(视觉模块去掉关系嵌入表示) 、VisMod(完整视觉模块)、GlCap(全局语义)、LoCap(局部语义)、SemMod(语义模块)、w/o ElMo (不用预训练语言模型)、DualVD(完整模型)。
![]() 实验结果表明,模型中的目标特征、关系特征、局部语义、全局语义对于提升回答问题的效果都起到了不同程度的作用。相比传统图注意力模型,采用视觉关系的嵌入表示使得模型效果又有了进一步提升。
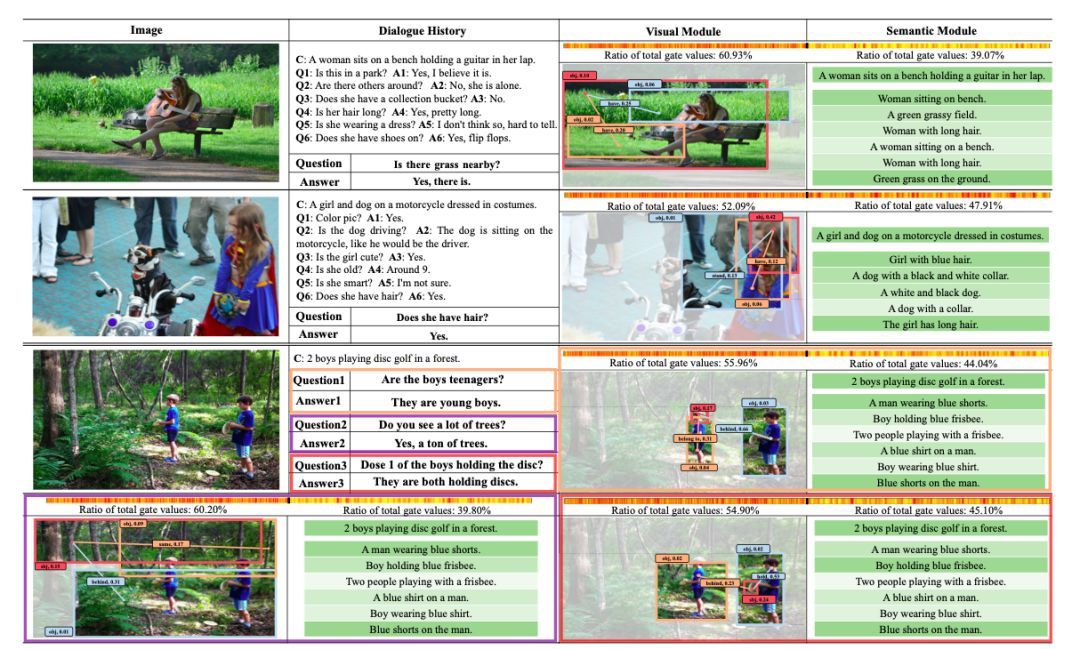
DualVD 的一个关键优势在于其可解释性: DualVD 能够预测视觉模块中的注意权重、语义模块中的注意权重以及可视化语义融合中的控制值,显式地分析模型特征选择的过程。作者通过分析可视化结果得出以下结论:
视觉信息和语义信息对于回答问题的贡献取决于问题的复杂性和信息源的相关性。涉及到目标对象表层信息的问题,模型会从视觉信息获得更多线索,如图 3 中第一个例子;当问题涉及到更加复杂的关系推理,或者语义信息包含了直接线索时,模型会更加依赖语义信息获取答案线索,如图 3 中的第二个例子。
视觉信息将为回答问题提供更重要的依据。作者根据结果发现,视觉模块的累积 gate value 总是高于来自语义模块的累积 gate value, 此现象说明在视觉对话任务中图像信息在回答问题时扮演更加重要的角色,对图像信息更准确、更全面的理解对于提升模型的对话能力至关重要。
实验结果表明,模型中的目标特征、关系特征、局部语义、全局语义对于提升回答问题的效果都起到了不同程度的作用。相比传统图注意力模型,采用视觉关系的嵌入表示使得模型效果又有了进一步提升。
DualVD 的一个关键优势在于其可解释性: DualVD 能够预测视觉模块中的注意权重、语义模块中的注意权重以及可视化语义融合中的控制值,显式地分析模型特征选择的过程。作者通过分析可视化结果得出以下结论:
视觉信息和语义信息对于回答问题的贡献取决于问题的复杂性和信息源的相关性。涉及到目标对象表层信息的问题,模型会从视觉信息获得更多线索,如图 3 中第一个例子;当问题涉及到更加复杂的关系推理,或者语义信息包含了直接线索时,模型会更加依赖语义信息获取答案线索,如图 3 中的第二个例子。
视觉信息将为回答问题提供更重要的依据。作者根据结果发现,视觉模块的累积 gate value 总是高于来自语义模块的累积 gate value, 此现象说明在视觉对话任务中图像信息在回答问题时扮演更加重要的角色,对图像信息更准确、更全面的理解对于提升模型的对话能力至关重要。
![]() 模型能够根据问题的变化,自适应调整关注的信息。如图 3 中的第三个例子,随着对话的推进,问题涉及前景、背景、语义关系等广泛的视觉内容,DualVD 都能够有效捕捉到关键线索。
模型能够根据问题的变化,自适应调整关注的信息。如图 3 中的第三个例子,随着对话的推进,问题涉及前景、背景、语义关系等广泛的视觉内容,DualVD 都能够有效捕捉到关键线索。
![]()
01. 时间可以是二维的吗?基于二维时间图的视频内容片段检测
02. 全新视角,探究「目标检测」与「实例分割」的互惠关系
03. 新角度看双线性池化,冗余、突发性问题本质源于哪里?
04. 复旦大学黄萱菁团队:利用场景图针对图像序列进行故事生成
05. 2100场王者荣耀,1v1胜率99.8%,腾讯绝悟 AI 技术解读
06. 多任务学习,如何设计一个更好的参数共享机制?
07. 话到嘴边却忘了?这个模型能帮你 | 多通道反向词典模型
![]()
![]()
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com
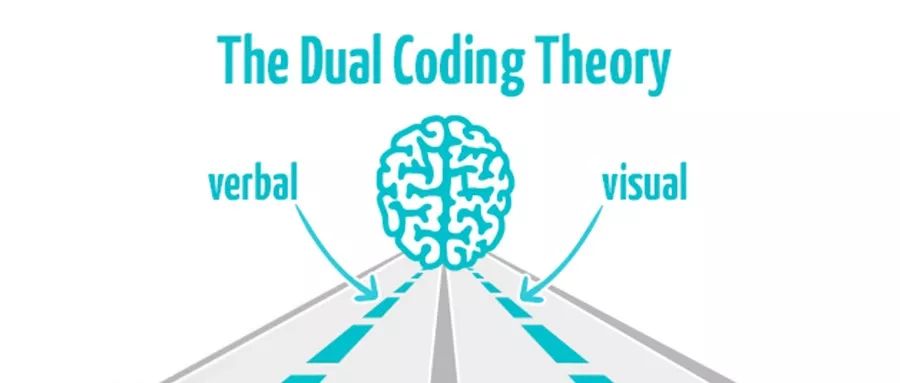
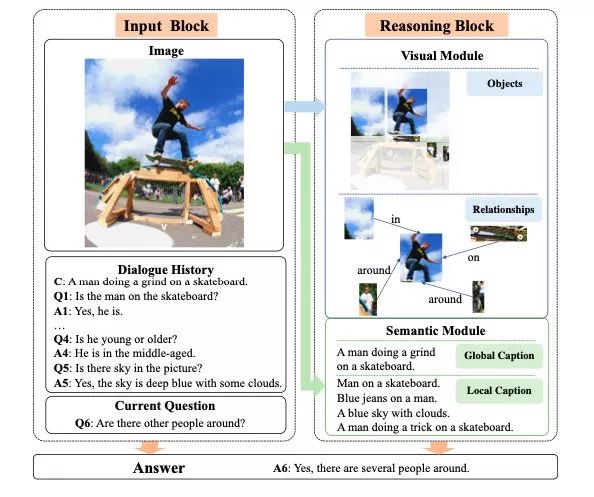 图1 DualVD模型基本思想。(左)模型输入;(右)视觉和语义信息理解模块。
图1 DualVD模型基本思想。(左)模型输入;(右)视觉和语义信息理解模块。