【AAAI2020论文】多轮对话系统中的历史自适应知识融合机制, 中科院信工所孙雅静等
近些年来,大家对于多轮对话中保持对话的一致性和减少重复性的问题。本文介绍中科院信工所孙雅静等人AAAI2020的工作《History-adaption Knowledge Incorporation Mechanism for Multi-turn Dialogue System》,该论文提出了一种history-adaption knowledge incorporation 机制,动态的考虑对话历史和知识之间的信息相互传递,增强检索式对话中的对话一致性以及避免重复性。

动机
核心思想
模型结构
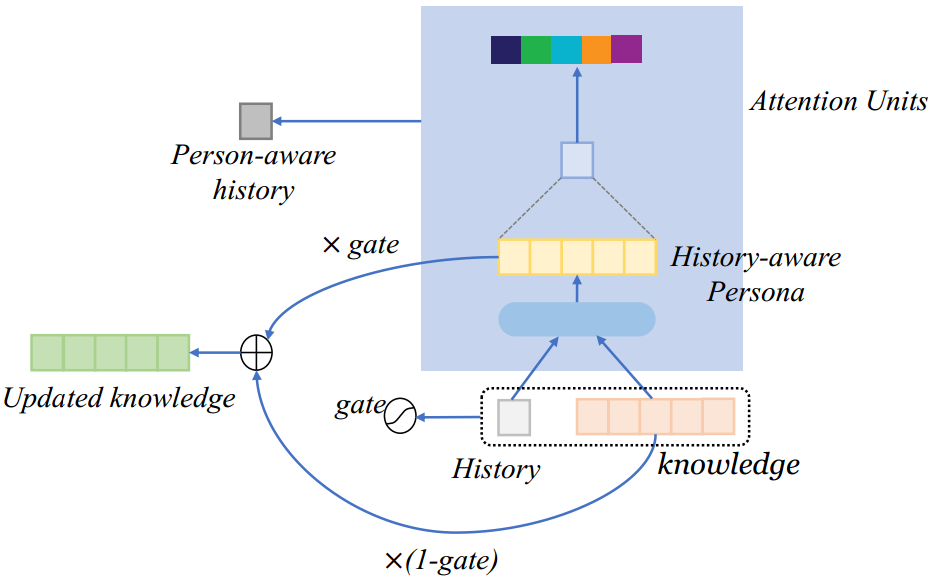
模型的总体结构如下图所示:
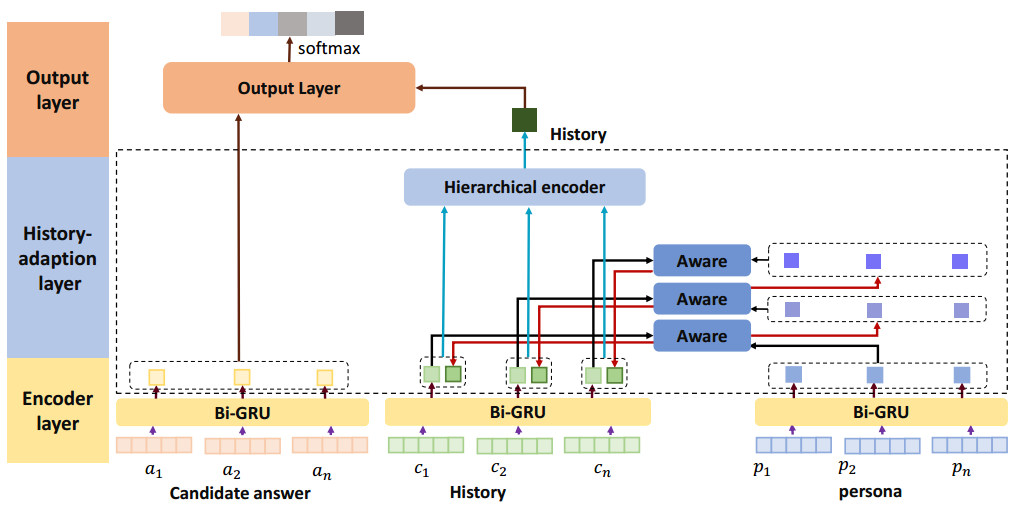
模型整体分为encoder layer,history-adaption layer以及output layer。
Encoder layer层主要是使用Bi-GRU对历史信息,知识信息以及候选答案进行编码,然后使用attention机制得到每个句子的上下文表示。得到的历史信息,知识信息,候选答案的上下文表示分别是hc,hp,ha。
在History-adaption 层,追踪外部知识在对话中的状态对于保持对话的一致性和重复性是重要的。对于外部知识的控制和更新和对话历史是紧密相关的。基于此,我们设计了一个门机制来控制外部信息在对话中的流动。我们循环的更新外部知识同时将其融入到历史中增强对话历史信息,最后我们采用层次循环机制捕捉基于外部知识感知的对话历史信息。
假定外部知识的初始状态表示为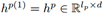
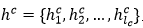

具体的更新过程如下:
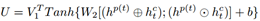
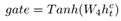
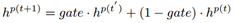
同时,我们得到基于knowledge感知的对话历史表示:
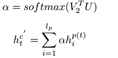
然后将更新之后的对话历史和原始对话历史表示进行拼接,最后经过GRU得到句子级别的上下文信息最后使用attention机制得到最终的对话历史表示。
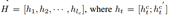
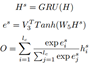
最后在output-layer主要是计算得到的对话历史表示与候选答案之间的相似度,具体如下:
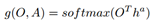
实验
数据集:主要使用persona-chat以及CMU_DoG数据集。其中CMU_DoG数据集由于没有候选答案集,我们从相同的数据集中采样了19个作为负例。这种采样方法很容易和正确答案去区分开,未来的工作中我们会考虑使用数据增强以及其他评价指标的方式生成负例。
实验参数设置:
(1)我们设置persona-chat的历史长度为6,7,8. CMUDoG的历史长度设置为7.
(2) 使用Adam优化器,batch size为128. 初始的学习率设置为0.001,然后使用1e-5。Dropout=0.5。使用glove embedding。Embedding size,hidden size均为300。
实验结果:

通过对比实验我们可以看出我们的模型相比两个baseline都有明显的提升,说明我们的模型可以更好地融合外部知识捕捉对话的深度语义信息,从候选答案中找到正确的答案。其中在CMU_DoG上的提升比较大的原因可能包括两个方面。
CMU_DoG的对话中包含更多的外部知识的信息,对于我们的模型来说比较容易选择正确的答案。其次我们使用层次循环的模型可以更好的捕捉长距离的对话历史信息相比于baseline来说。在之后的工作中,我们会采用生成式的方法来更加有效的验证我们的模型。
Ablation experiment以及length analysis如下:
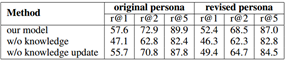
Ablation的实验中我们可以看出在persona-chat的数据集上没有知识融合机制,模型的效果会有很大的降低,没有知识更新机制同样会有降低,证明了知识融合的必要性以及知识更新的有效性。
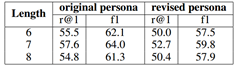
从长度分析实验中可以看出我们的模型可以捕捉较长的对话历史信息。