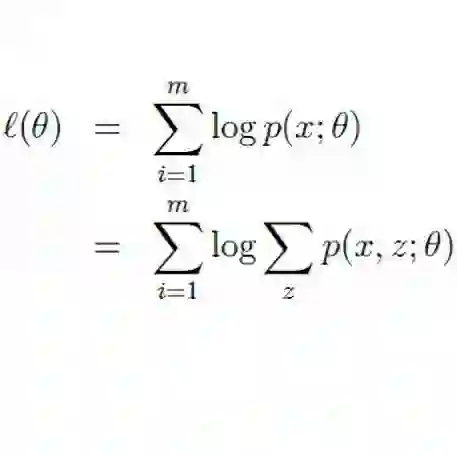五分钟快速了解EM算法
 !
!
阅读大概需要8分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()


EM算法要解决什么问题
EM算法的E-step和M-step以及证明其收敛性
EM算法的应用
一.EM算法要解决什么问题
二.EM算法的公式以及证明其收敛性
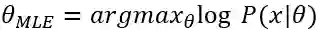 ,为了方便求解一般会加上log,后面这个式子也称为log likelihood。
EM算法就是通过迭代的方式求出这个式子的解析解。
,为了方便求解一般会加上log,后面这个式子也称为log likelihood。
EM算法就是通过迭代的方式求出这个式子的解析解。
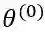 , 开始迭代。
假设
, 开始迭代。
假设
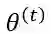 是第t次迭代参数的估计值,在第t+1次迭代时,EM算法的公式是
是第t次迭代参数的估计值,在第t+1次迭代时,EM算法的公式是
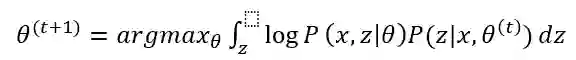
这个式子后半部分的积分其实就是求期望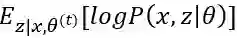
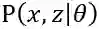
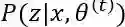
需要注意的是,虽然参数的初值可以任意选择,但是EM算法对于初值是敏感的,随意取初值很有可能得不到好的结果,所以还是要慎重取值。
了解了公式之后,接下来我们来证明EM算法的收敛性。即证明
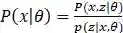 ,两边同时取对数得
,两边同时取对数得
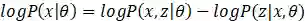
由上文可知
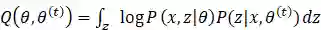
令
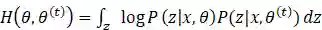
则 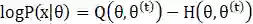
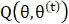
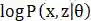
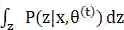
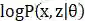
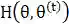
对于上式分别取θ为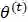
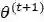
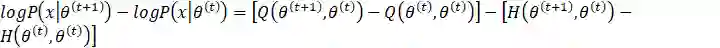
为了证明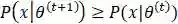
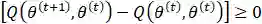
对于第二项
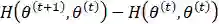
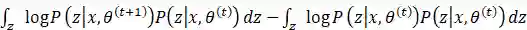
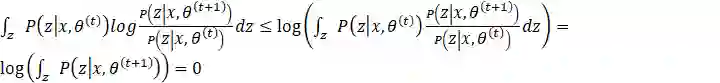
这里的不等式由Jenson不等式得到。其实如果了解KL散度可以发现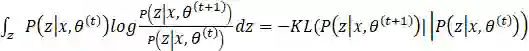
三.EM算法的应用
之前有一次面试,面试官问我机器学习算法都会哪些,我说到了EM算法,然后她问EM算法有什么应用吗,她觉着EM算法没有什么应用场景。其实EM算法应用还是比较广泛的,尤其是在高斯混合模型做参数估计的时候。EM算法不像感知机,支持向量机应用普遍,它很少作为分类算法被使用,EM算法作为一种参数估计的方法,更多是和概率模型结合使用,例如用于马尔可夫模型参数求解。同时EM算法还有一些推广:GEM算法,变分EM等等。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!