专知主题链路知识推荐#4-机器学习中往往被忽视的贝叶斯参数估计方法
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。今天给大家继续介绍我们独家整理的机器学习——贝叶斯参数估计方法。
这次介绍一下机器学习中常见的参数估计方法,这对推断模型参数是非常必要的,往往是大家忽略的一个点,机器学习几乎所有的方法模型都会跟参数估计有关。很多人只知道极大似然估计,但对最大后验估计,贝叶斯估计等等往往不知所云,不是很清楚,今天,我们详细讲解这三者的联系和区别。由于微信公众号编辑公式问题,如果想更详细地了解这三者的关系,建议访问原文:
http://www.zhuanzhi.ai/#/linkedDoc/fa11d1e3d4c6239944067ca3947324aa
在参数估计中,我们会遇到两个主要问题:(1)如何去估计参数的值。 (2)估计出参数的值之后,如何去计算新的观测数据的概率,比如进行回归分析和预测。符号定义如下:
现有观测数据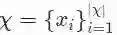
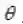
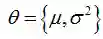
对于这些数据和参数,在贝叶斯统计学中,存在一些很普遍的概率函数。这些概率函数将在贝叶斯规则中加以介绍,贝叶斯规则如下(公式(1)):
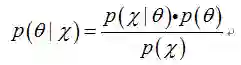
针对上式,定义相关术语如下(公式(2)):
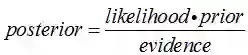
后验概率 = 似然函数*先验概率/证据
下一段我们将介绍不同的参数估计方法,首先是最大似然估计,然后是最大后验估计(如何利用最大化后验合并参数中的先验知识),最后是贝叶斯估计(使用贝叶斯规则推断一个完整的后验分布)。
(1)最大似然估计(Maximum likelihood estimation, MLE)
最大似然估计(Maximum likelihood)试图通过最大化似然函数估计出其参数。其含义是求出一个参数,使得已经发生的所有事件X的概率最大。最大似然估计就是要用似然函数取到最大值时的参数值作为估计值,似然函数可以写做公式(3):
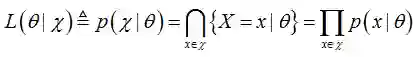
如公式(3),产生数据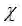
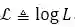
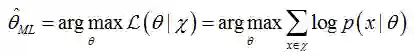
(由于公式编辑有问题,直接用图片代替了)
一般解决最大似然估计问题,通过求导似然函数,使其导数为零。根据上式,求解这个优化问题要对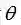
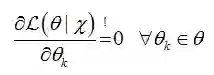
给定数据集
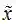
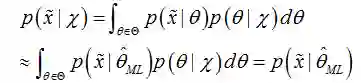
注意有一个约等于,因为他进行了一个近似的替换,将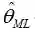
举例
举个例子,以抛硬币伯努利实验为例。考虑N次伯努利实验的集合,每次抛硬币的概率为参数p,不妨设为硬币是正面的概率。例如,伯努利实验通过投掷一枚有变形的硬币来实现。对于一次实验来说,伯努利概率密度函数如下(公式(8)):
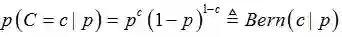
我们定义c=1为硬币的正面朝上;定义c=0为硬币反面朝上。
基于参数p构建最大似然估计,log似然函数如下所示(公式(9)):
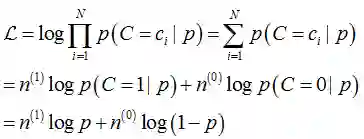
其中,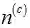
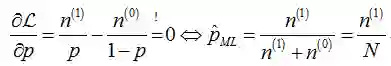
也就是正面事件次数与样本总数的比值,如果硬币是有形变的,那么经过20次抛掷以后,可能得到结果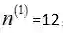
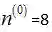
(2)最大后验估计(Maximum a posteriori , MAP)
最大后验估计(Maximum a posteriori, MAP)与最大似然估计方法类似,区别是最大后验概率估计在参数中考虑了先验知识,用先验分布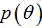
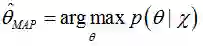
利用贝叶斯规则,上式可写为(公式(13)):
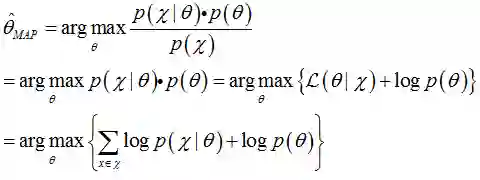
对比公式(4),在似然函数中增加了先验分布。先验分布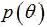
MAP参数估计可以通过最大化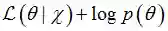
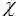
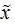
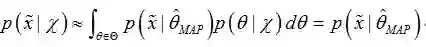
与最大似然估计相比,现在需要多加上一个先验分布概率的对数。在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)。 所以我们认为,
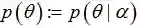
举例
下面以Beta分布举例:
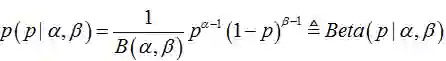
其中,Beta函数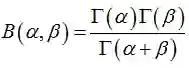
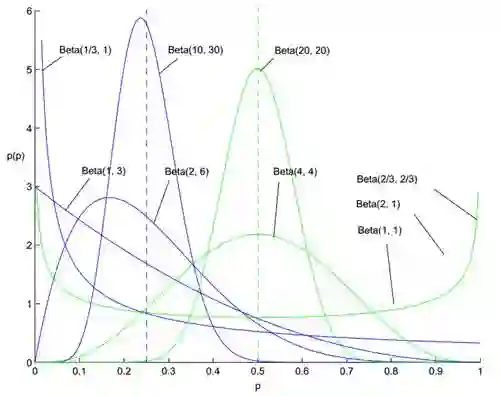
图1, 不同参数的Beta分布密度函数图
举个例子,我们可以在抛硬币的实验中把先验Beta分布的参数设置为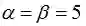
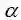
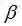
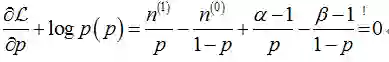
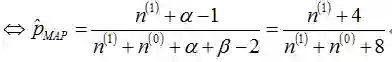
与最大似然估计ML的结果对比可以发现结果中多了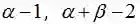
如果我们做20次实验,出现正面12次,反面8次,那么,根据MAP估计出来的参数p为(12+4)/(20+8) = 16/28 = 0.571,小于最大似然估计得到的值0.6,这也显示了先验对“硬币一般是两面均匀的”的参数估计的影响。
(3)贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。极大似然估计和极大后验概率估计,都求出了参数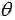
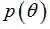
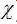
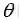
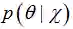
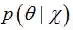
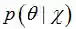
又回到贝叶斯公式(18):
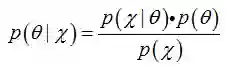
其中是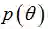
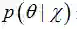
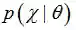
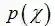
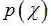
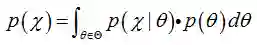
当新的数据被观察到时,后验概率可以自动随之调整。但是上式中的全概率公式的求解方法通常是贝叶斯推断中最复杂的部分(MAP直接忽略了分母),下面将进行详细介绍。
用贝叶斯估计来做预测问题时,如果我们想估计一个新样本的概率,可以由下面公式来计算:
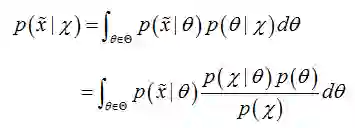
上式中,后验概率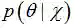
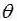
举个例子,N次伯努利实验,参数p(即正面的概率)的先验分布是参数为(5,5)的beta分布,然后接下来,我们根据参数p的先验分布和N次伯努利实验结果来求p的后验分布。我们假设先验分布为Beta分布,但是构造贝叶斯估计时,不是要求用后验最大时的参数来近似作为参数值,而是求满足Beta分布的参数p的后验分布的期望,也就是直接写出参数的分布再来求分布的期望:
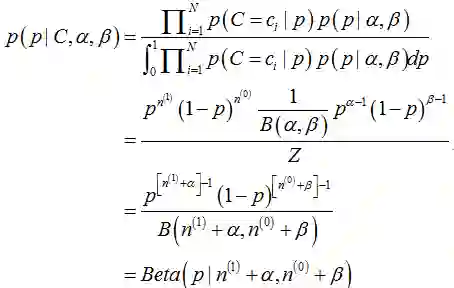
其中,C是抛掷硬币的所有实验结果,C=0或1。由上式可知,其后验分布还是服从Beta分布的概率密度函数。根据分布的均值(mean)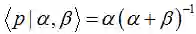
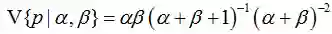
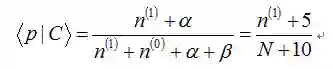
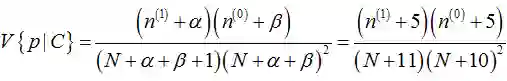
可以看出此时估计的参数p对应的后验分布的期望和最大似然估计(MLE),最大后验估计(MAP)中得到的估计值都不同,此时如果仍然是做20次实验,12次正面,8次反面,那么我们根据贝叶斯估计得到的参数p满足参数为12+5和8+5的Beta分布,其均值和方差分别是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此时求出的p的期望比MLE和MAP得到的估计值都小,更加接近0.5。
上面就是关于机器学习最基本的参数估计概念的一个总结,建议大家多多体会极大似然估计,最大后验估计,贝叶斯估计这三者的相同点和不同点,有什么问题可以在我们的专知公众号平台上交流或者加我们的微信 专知—机器学习交流群(请先加微信小助手weixinhao: Rancho_Fang)或者是QQ群专知-人工智能交流群 426491390
同时请,关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。扫一扫下方关注我们的微信公众号。



