你可能不需要固定词表:一种与词表无关的组合式词向量方法

论文标题:
Grounded Compositional Outputs for Adaptive Language Modeling
论文作者:
Nikolaos Pappas (UW), Phoebe Mulcaire (UW), Noah A. Smith (UW)
论文链接:
https://arxiv.org/abs/2009.11523
代码链接:
https://github.com/Noahs-ARK/groc (Coming soon)
过去的几乎所有深度模型在输入和输出的时候都使用一个固定的词向量矩阵,它的大小就是预定义好的词表的大小。
但是,在测试的时候遇到OOV,或者用在其他领域的时候,模型的效果就会大打折扣。如果要覆盖更多的词,无疑就是增大词表,这样的话,词向量矩阵也会随之增大。
如何尽可能覆盖更多的词,同时也不会显著增加参数量,甚至保持参数量不变,是处理此类问题的一个关键所在。
本文提出了一种与词表无关的词向量方法,每个词的词向量都是由它内部的字符、WordNet中的关系与定义组合得到的,这样对于所有词而言,参数量就固定了。
同时,对于任何词,即使没有在原来的词向量矩阵中,这种方法也可以得到词向量。这样就可以达到我们的目标。
在开始介绍之前需要说明,本文说的词表并不是词库,因为无论如何,包括我们人类也都是需要存储词的。这里的词表指一个固定的词向量矩阵 ,在训练完之后,对任何任务,这个矩阵在推理的时候是不变的。
本文的方法可以理解为:对不同的任务可以有不同的 ,而 中的每个词向量都是组合得到的而不是自己去学到的,所以总的参数量就和 本身无关。这一点需要尤其注意。
词向量矩阵
词向量矩阵 在各类NLP模型中是一个标配,它把词表 中的每个词 映射为一个与之对应的向量 ,在训练结束之后,这个矩阵 就是固定的,对于生成类任务而言,所有要生成的词也是从中选择的。
词向量矩阵分为两类:输入矩阵 和输出矩阵 。这两个矩阵可以相同,也可以不同,但一般来说,它们的大小都是固定的,即 。
显然,词表 越大,参数量就越多。如果想要减少参数量,令 是一个不错的选择。再进一步,令输出矩阵是输入矩阵的一个函数可以在一定程度上区分两者,即 。如下图所示。
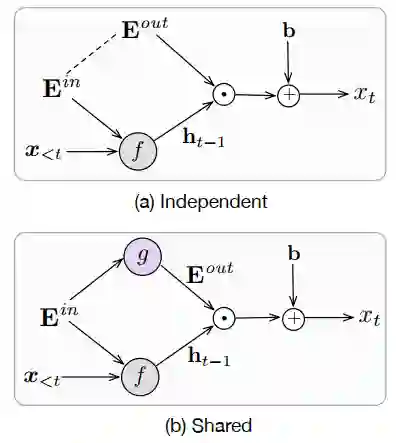
但无论是哪种方法,正如我们上面说的,它们的大小都是恒定的,如果遇到不同领域的文本,或者一些情况下我们想要引入更多的不包含在现有词表 中的词时,就会产生大量的OOV,这些词在 不存在,从而影响模型效果。
那么,转变一下思路:我们现实中的词不都是通过词典去定义吗,而且一个词的意思往往能通过组成它的字推导出来(这在英语中尤其明显)。
所以,我们能不能采用一种组合式的方式,不是对每个词都去学一个它独有的词向量,而是用它的表层形式(Surface Form)、词典定义(Definition)和关系(Relation),去得到它的词向量。
这样一来,通过特定的实现,无论我们有多少词,模型的参数量都是恒定不变的;同时,如果在测试的时候遇到一个没有见过的词,也可以用这种方式去得到它的词向量,从而解决上面的问题。
GroC: 组合式词向量
下图是GroC(Grounded Compositional)词向量的示意图。方法很简单,对每个词,无论是在不在某个词表中,它的词向量都由三部分得到:表层形式(Surface Form),关系形式(Relational Form)和定义形式(Definitional Form)。然后把这三者拼接起来就是词本身的词向量了。
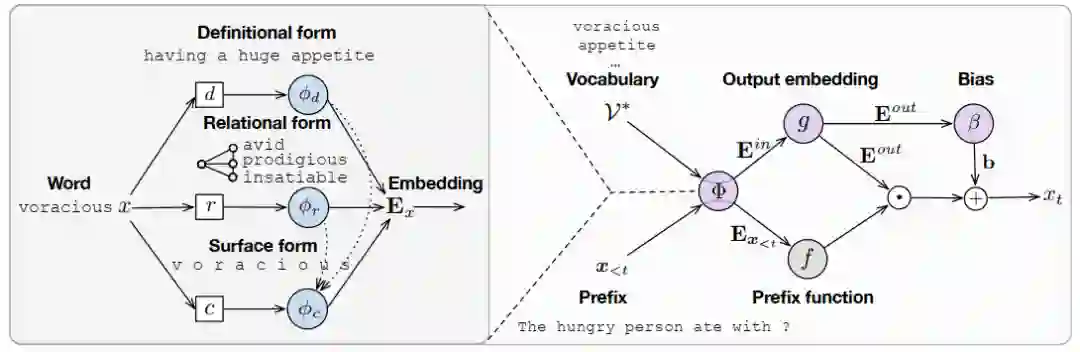
表层向量 就用一个字级别的CNN+Highway实现,关系向量 就是WordNet中它的所有同义词和近义词表层向量 的平均,而定义向量 就是词的定义中所有词表层向量 的平均。如果一个词没有出现在WordNet中,就相应地把 设为0即可。
用这种方法,训练和测试完全可以用不同的词表 。比如说现在测试用的词表是 ,那么就可以match用GroC得到它其中每个词的词向量 。
但是上面我们说了,一般模型有输入和输出向量,而GroC只能得到一个向量,为了进一步区分二者,我们依然可以把输出向量看作是输入向量的函数,即:

最后得到的 就是真正的输出向量。
注意,在训练的时候这种方法肯定会比一般的词向量方法开销更大,因为要得到三个组成向量。为此,可以不用每次都更新参数,而是以一定概率进行,具体详见原文。在推理的时候,也可以缓存已有的 。
实验
In-Domain Language Model
in-domain语言模型任务考虑的是固定词表,即训练和测试的词表相同。数据集有penn和wikitext2。所有任务的模型都是LSTM,但是输出词向量矩阵的方法不同,有Lookup Table,Convolutional,Tied,Bilinear,Deep Residual,Adaptive和GroC。下表是实验结果。

可以看到,GroC参数量极少,但可以非常显著地提升效果。其主要原因可能是能够更好地处理低频词和OOV,而GroC可以在某种程度上建立词表中各个词的联系。下图是不同词频段的中位数损失,可以看到,GroC相比所有其他方法,在所有词频段上都有提升,而提升最大的就是低频段。

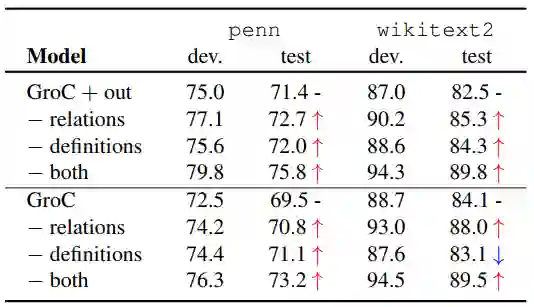
那么,GroC的不同组成向量的贡献是多少呢?下表探究了不同组成成分的影响,其中out就是函数 。可以看到,单独移除一个组成向量影响不是很大,但是移除两个的影响就非常大了。
Cross-Domain Language Model
既然我们说GroC可以在测试的时候有不同的词表,那么它在不同词表上的效果又如何呢?为此,我们继续在cross-domain上实验。
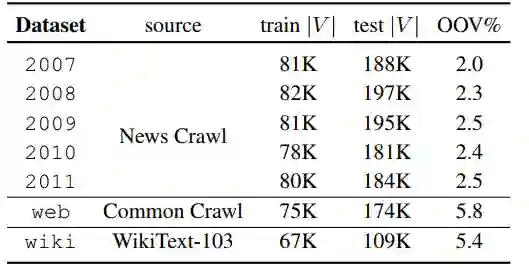
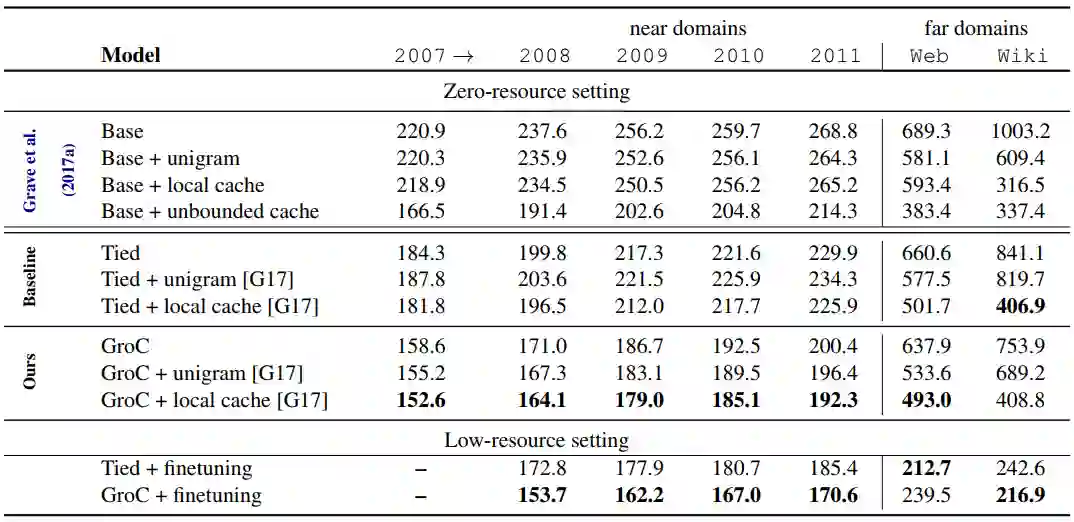
数据集来着News Crawl,Common Crawl和WikiText-103,下表是数据情况。
所有模型都在2007上训练,在targt domain上测试。比较的模型有GroC和Tied,而且都有三种迁移方法:Unigram(一种统计方法),Local Cache(一种插值方法)和Finetuning(在target domain上微调)。
下表是实验结果。无论是zero-resource,还是low-resource,不管是near-domain还是far-domain,或是不同迁移方法,几乎都是GroC显著超过Tied和Base方法。由此可见GroC在处理OOV时的威力。
小结
本文提出了组合式的词向量方法,基于词本身的表层形式和词典中的信息,可以用固定的参数得到任意多词的词向量,不但可以在词表很大的时候减少参数,而且能够有效缓解OOV问题。尽管在训练的时候可能更慢,但通过一定手段也是可以加速的。
这类方法在之前其实有很多,比如Retrofit等,但是本文的重心在于输出矩阵,对如何在输出的时候缓解常见的如低频词的影响,如何利用现有的语言学知识等问题来说,都有一定的启发。
当然本文也有不足,比如没有分析以此得到的词向量的性质(比如经典的Queen:Girl=King:Boy任务),不能直观观察它们的语言学性质如何,不过从诸多实验的效果来看,GroC的可靠性还是可以得到保障的。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




