100+中文词向量,总有一款适合你
【导读】这个项目提供了大量的中文预训练词向量。包含多种representations(包括dense和sparse)、多种词粒度(word、ngram、char等),多种窗口大小,多种语料(百度百科、人民日报等)训练出的Word Embedding。总有一款适合你。此外,该项目还提供了一个中文类比推理数据集CA8以及一个能够评估词向量质量的工具。
编译 | 专知
参与 | Yukun, Huaiwen
Chinese Word Vectors 中文词向量
WordEmbedding格式
项目中预训练的向量文件采用文本格式。每一行包含一个词和它的向量。向量的每个值用空格隔开。文件第一行记录的是元信息:第一个数字表示文件中词的数量,第二个数字表示词向量维度的大小。
除了dense词向量(用SGNS训练),我们还提供sparse向量(用PPMI训练)。它们与liblinear的格式是相同的,在“:”之前的数字表示维度索引,在“:”之后的数字表示其值。
多种Representations
现有的词表示方法分为两类:dense表示和sparse表示。 SGNS模型和PPMI模型分别是这两类表示的典型方法。 SGNS模型通过浅层神经网络训练低维密集向量, 这种方法也被称为神经嵌入方法。 PPMI模型是一种稀疏的特征表示,即正点互信息(positive-pointwise-mutual-information)。
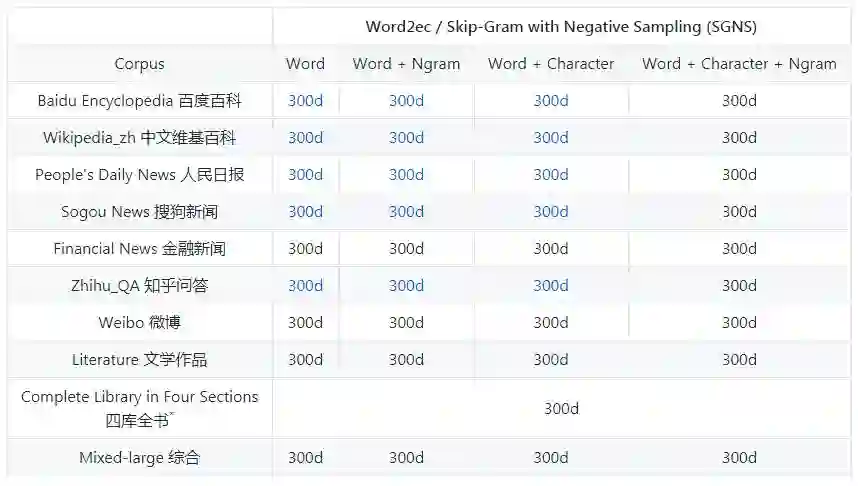
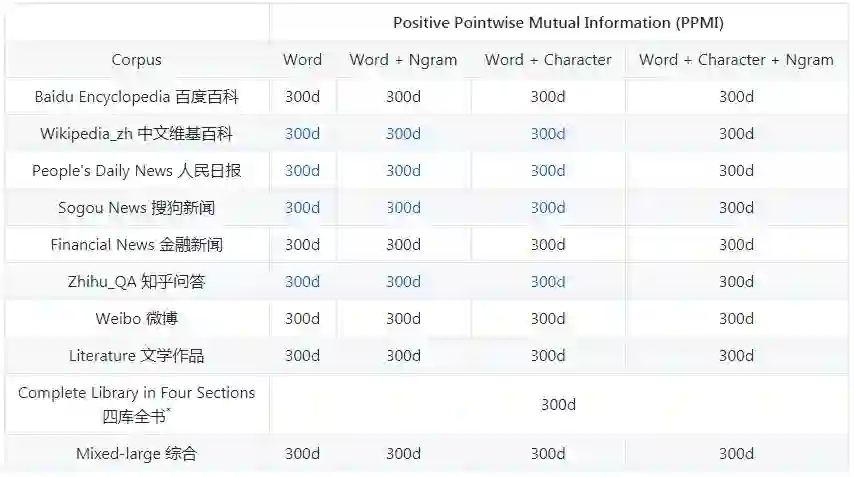
多种上下文特征
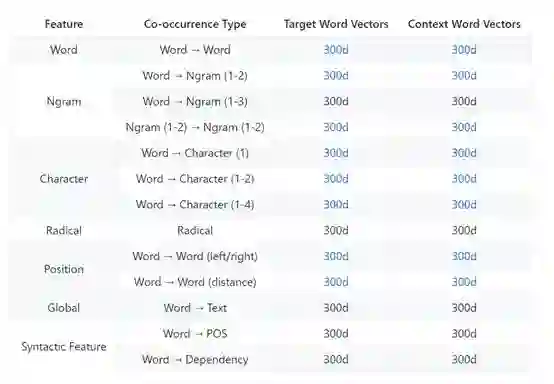
三种上下文特征:词、ngram和字符,这三种上下文特征经常在词向量表示的文献中出现。 大多数单词表示方法主要利用词与词之间的共现统计数据,即使用词作为上下文特征。受语言模型问题的启发,我们在上下文中引入了ngram特征。词与词和词与ngram的共现统计数据通常一起用来训练。对于中国人来说,字符通常表达强烈的语义。在最后,我们使用词与词和词与ngram共现统计数据来学习单词向量。字符的ngram的长度通常在1到4之间。
除了单词,ngram和字符之外,还有其他对词向量产生影响的特征。 例如,使用整个文本作为上下文特征可以将更多的内容信息融入到词向量; 使用依赖关系解析作为上下文特征可以为词向量添加语法约束。本项目考虑了17种同现类型。
多种上下文信息
词向量通常是基于一个词来预测其上下文(skip-gram),在一些相关论文中通常被称为输入和输出向量。在这一步部分,我们设置了多种上下文供你选择。
所有向量由SGNS以百度百科为数据集进行训练。
多种语料
该项目收集了大量语料,所有文本数据在预处理中删除了html和xml标签,只保留了纯文本信息,并且使用HanLP(v_1.5.3)进行分词。语料的详细信息如下所示:
工具包
所有的词向量都由ngram2vec工具包进行训练。Ngram2vec工具包是由word2vec和fasttext工具包结合起来进行构造,支持抽取任意上下文特性。
评价dense vectors:
$ python ana_eval_dense.py -v <vector.txt> -a CA8/morphological.txt
$ python ana_eval_dense.py -v <vector.txt> -a CA8/semantic.txt
评价sparse vectors:
$ python ana_eval_sparse.py -v <vector.txt> -a CA8/morphological.txt
$ python ana_eval_sparse.py -v <vector.txt> -a CA8/semantic.txt
中文词类比基准
词向量的质量通常通过类比问题进行评估,在这个项目中,评估过程采用两个基准。第一个是CA-translated,其中大多数类比问题直接从英语基准转换而来。虽然CA-translated已被广泛用于许多中文单词表示论文,但它只包含三个语义问题的问题并且只包含了134个中文单词。相比之下,CA8是专门为中文而设计的。它包含了17813个类比问题,并且包含了复杂的词法和语义关系。 CA-translated和CA8及它们的详细描述在testsets文件夹中可以看到。
参考:
Shen Li, Zhe Zhao, Renfen Hu, Wensi Li, Tao Liu, Xiaoyong Du, Analogical Reasoning on Chinese Morphological and Semantic Relations, ACL 2018.
链接:
https://github.com/Embedding/Chinese-Word-Vectors
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



