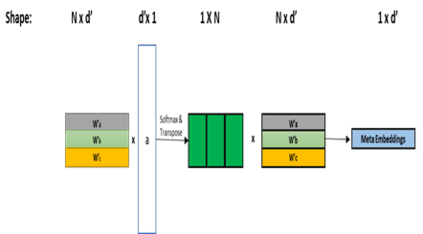
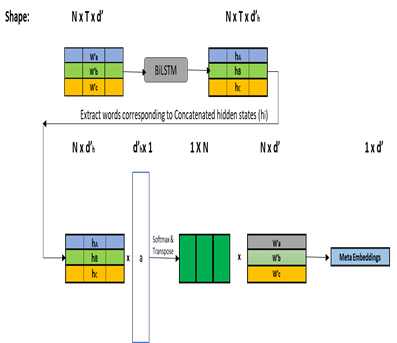
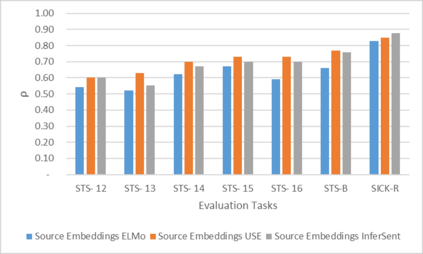
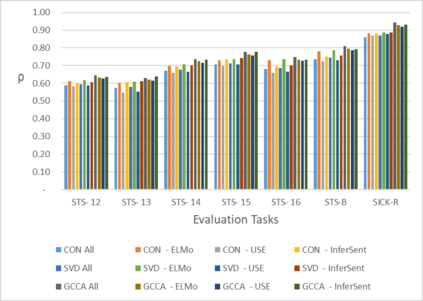
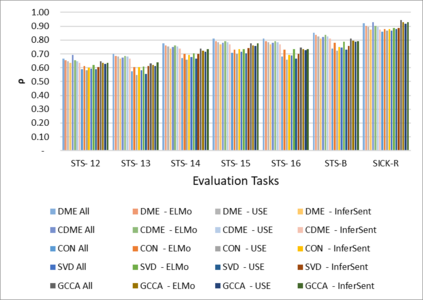
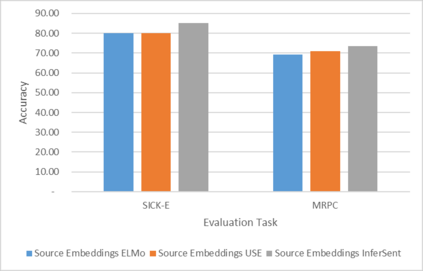
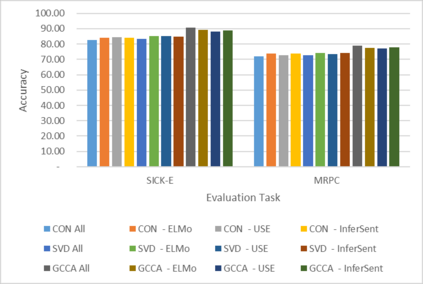
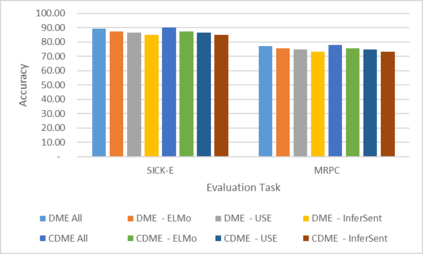
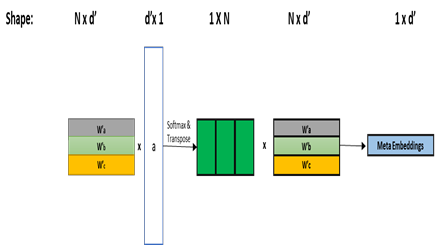
Word Representations form the core component for almost all advanced Natural Language Processing (NLP) applications such as text mining, question-answering, and text summarization, etc. Over the last two decades, immense research is conducted to come up with one single model to solve all major NLP tasks. The major problem currently is that there are a plethora of choices for different NLP tasks. Thus for NLP practitioners, the task of choosing the right model to be used itself becomes a challenge. Thus combining multiple pre-trained word embeddings and forming meta embeddings has become a viable approach to improve tackle NLP tasks. Meta embedding learning is a process of producing a single word embedding from a given set of pre-trained input word embeddings. In this paper, we propose to use Meta Embedding derived from few State-of-the-Art (SOTA) models to efficiently tackle mainstream NLP tasks like classification, semantic relatedness, and text similarity. We have compared both ensemble and dynamic variants to identify an efficient approach. The results obtained show that even the best State-of-the-Art models can be bettered. Thus showing us that meta-embeddings can be used for several NLP tasks by harnessing the power of several individual representations.
翻译:语言代表构成几乎所有先进的自然语言处理(NLP)应用的核心组成部分,例如文本挖掘、问答和文本总结等。在过去20年中,为了找到一个单一的模型来解决所有主要的自然语言处理任务,进行了巨大的研究。目前的主要问题是,不同的自然语言处理任务有许多选择。因此,对于自然语言处理(NLP)实践者来说,选择使用正确的模型本身就是一个挑战。因此,将多种预先培训的字嵌入和形成元嵌入结合起来,已成为改进处理自然语言处理任务的可行办法。元嵌入学习是从一套特定经过预先培训的投入嵌入的词中产生一个单词嵌入的过程。在本文件中,我们提议使用从少数国家艺术(SOTA)模型中得出的Met 嵌入式来有效解决主流自然语言处理任务,例如分类、语义相关关系和文本相似性。我们比较了多种预先培训的词嵌入和形成元嵌入式变式,从而确定了一种有效的方法。获得的结果显示,即使是最佳的国家- 最佳的版本模型也能够更好地展示我们使用的几种现代版本模型。