TAMU最新《图神经网络可解释》综述论文,19页pdf阐述实例级与模型级解释
本文探讨了
需要GNN的可解释性
解释GNN预测的挑战
不同的GNN解释方法
GNNExplainer的直观解释
使用GNNExplainer实现解释节点分类和图分类
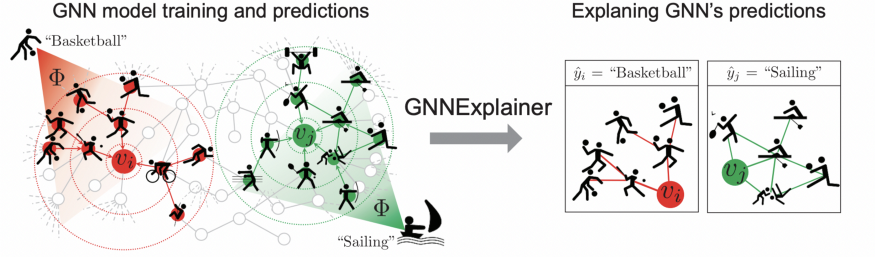
-
增加对模型预测的信任 -
改进模型的透明度,用于与公平、隐私和其他安全挑战相关的关键决策应用 -
在将模型部署之前,可以通过对网络特征的理解来识别和纠正模型所犯的系统模式错误。
深度神经网络的发展彻底改变了机器学习和人工智能领域。深度神经网络在计算机视觉[1]、[2]、自然语言处理[3]、[4]、图数据分析[5]、[6]等领域取得了良好的研究成果。这些事实促使我们开发深度学习方法,用于在跨学科领域的实际应用,如金融、生物学和农业[7]、[8]、[9]。然而,由于大多数深度模型是在没有可解释性的情况下开发的,所以它们被视为黑盒。如果没有对预测背后的底层机制进行推理,深度模型就无法得到完全信任,这就阻止了它们在与公平性、隐私性和安全性有关的关键应用中使用。为了安全可靠地部署深度模型,有必要提供准确的预测和人类可理解的解释,特别是为跨学科领域的用户。这些事实要求发展解释技术来解释深度神经网络。
深度模型的解释技术通常研究深度模型预测背后的潜在关系机制。一些方法被提出来解释图像和文本数据的深度模型。这些方法可以提供与输入相关的解释,例如研究输入特征的重要分数,或对深度模型的一般行为有较高的理解。例如,通过研究梯度或权重[10],[11],[18],我们可以分析输入特征和预测之间的灵敏度。现有的方法[12],[13],[19]映射隐藏特征图到输入空间和突出重要的输入特征。此外,通过遮挡不同的输入特征,我们可以观察和监测预测的变化,以识别重要的特征[14],[15]。与此同时,一些[10]、[16]研究侧重于提供独立于输入的解释,例如研究能够最大化某类预测得分的输入模式。进一步探究隐藏神经元的含义,理解[17]、[22]的整个预测过程。近年来对[23]、[24]、[25]、[26]等方法进行了较为系统的评价和分类。然而,这些研究只关注图像和文本域的解释方法,忽略了深度图模型的可解释性。
-
图数据不如图像和文本直观,这使得人类理解图深度学习模型的解释具有挑战性。
-
图像和文本使用类似网格的数据;然而,在一个图、拓扑中,信息是用特征矩阵和邻接矩阵表示的,每个节点有不同的邻居。因此,图像和文本的解释方法不适合获得高质量的图的解释。
-
图节点和边对GNN的最终预测有很大的贡献;因此,GNN的可解释性需要考虑这些交互作用。
-
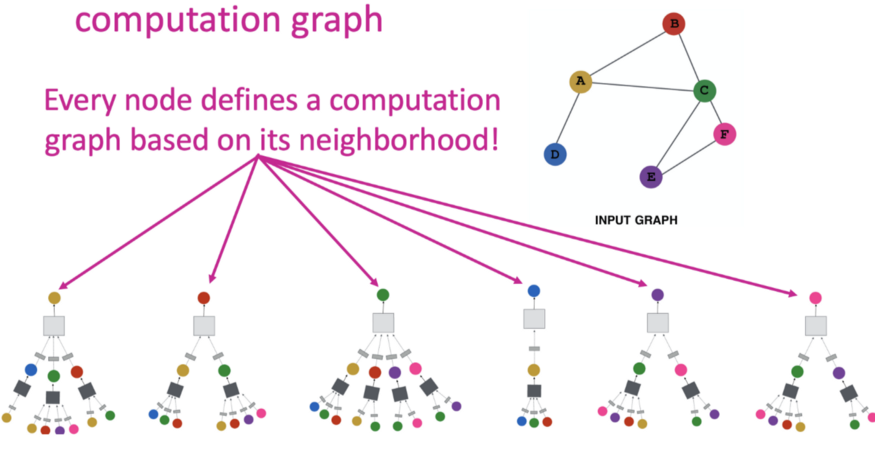
节点分类任务通过从它的邻居执行消息遍历来预测节点的类。研究消息遍历可以更好地理解为什么由GNN做出预测,但与图像和文本相比具有挑战性。
-
哪些输入边对预测更关键,贡献最大?哪个输入节点更重要? -
哪个Node特征更重要? -
什么样的图模式能最大限度地预测某一类?
-
实例级方法 : 给定一个输入图,实例级方法通过识别用于预测的重要输入特征来解释深度模型。
-
模型级方法 提供了一般的见解和高层次的理解来解释深度图模型。模型级方法专门研究哪些输入图模式可以通过GNN实现一定的预测。
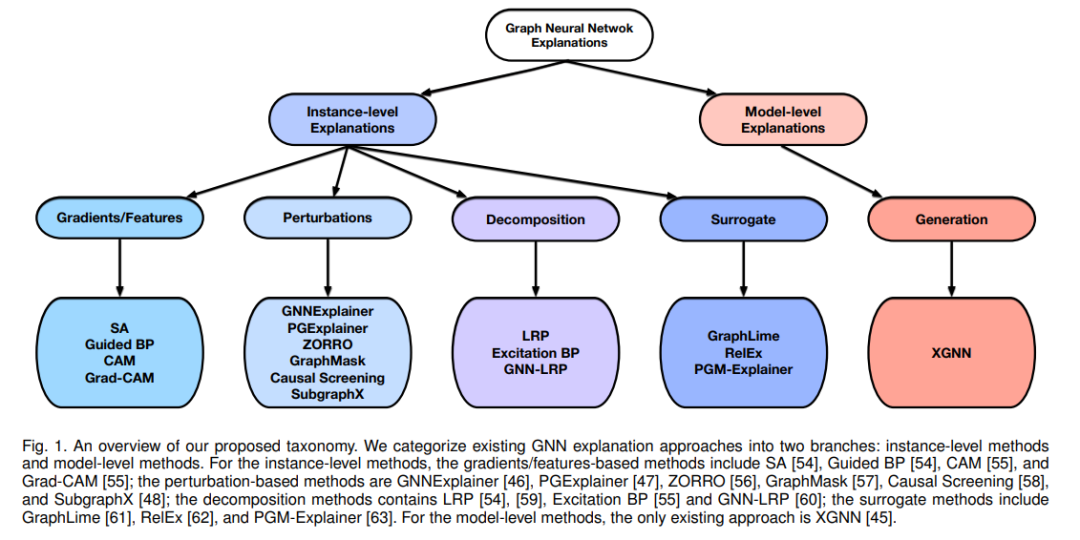

深度学习方法在许多人工智能任务中实现了不断提高的性能。深度模型的一个主要限制是它们不具有可解释性。这种限制可以通过开发事后技术来解释预测来规避,从而产生可解释的领域。近年来,深度模型在图像和文本上的可解释性研究取得了显著进展。在图数据领域,图神经网络(GNNs)及其可解释性正经历着快速的发展。然而,对GNN解释方法并没有统一的处理方法,也没有一个标准的评价基准和试验平台。在这个综述中,我们提供了一个统一的分类的视角,目前的GNN解释方法。我们对这一问题的统一和分类处理,阐明了现有方法的共性和差异,并为进一步的方法论发展奠定了基础。为了方便评估,我们为GNN的可解释性生成了一组基准图数据集。我们总结了当前的数据集和评价GNN可解释性的指标。总之,这项工作为GNN的解释提供了一个统一的方法处理和一个标准化的评价测试平台。
地址:
https://www.zhuanzhi.ai/paper/9a56925995fc3dfa1e88dbd945a2d358
本综述提供了对深度图模型的现有解释技术的系统和全面的回顾。据我们所知,这是第一次也是唯一一次关于这一主题的综述工作。
我们对现有的GNN解释技术提出了一个新的分类方法。我们总结了每个类别的关键思想,并提供了深刻的分析。
我们详细介绍了每种GNN解释方法,包括其方法论、优缺点以及与其他方法的区别。
我们总结了常用的GNN解释任务的数据集和评估指标。我们讨论了它们的局限性,并推荐了几个令人信服的度量标准。
通过将句子转换为图表,我们从文本领域构建了三个人类可理解的数据集。这些数据集不久将向公众开放,并可直接用于GNN解释任务。
参考文献以及代码:
https://arshren.medium.com/explainability-of-graph-neural-network-52e9dd43cf76
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GNE” 就可以获取《TAMU最新《图神经网络可解释》综述论文,19页pdf阐述实例级与模型级解释》专知下载链接





