【专知-PyTorch手把手深度学习教程06】NLP-Word Embedding快速理解与PyTorch实现: 图文+代码
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。值国庆佳节,专知特别推出独家特刊-来自中科院自动化所专知小组博士生huaiwen和Kun创作的-PyTorch教程学习系列, 今日带来第五篇-< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(二) 基于字符级RNN的姓名分类 >
< NLP系列(三) 基于字符级RNN的姓名生成 >
Word Embedding: 编码词汇的语义
在一般任务中, 我们总是非常自然的用特征值来表示一个词汇。但是, 到底怎么样表示一个词, 才是最合理的? 存储其ASCII码表示,只会告诉你这个词是什么,并不能表示这个词真正的语义(也许你可以从这个词的词缀中获得该词的词性或其他属性,但也只能获得这些东西)。更进一步的, 我们应该在什么场景下, 将这些词的表示联合起来考虑? 因为我们的神经网络, 常常输入维度是整个词典的大小|V|,输出维度是标签集合的大小(一般远小于|v|). 如何从稀疏的高维空间生成较小的维度空间?
如果我们用one-hot来表示词的话:
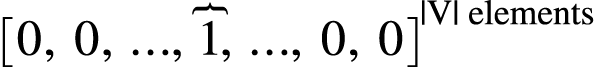
我们能得到如图的一个表示: 只有某一维度的值是1, 其他维度都是0, 这个值为1的维度就代表这个词.
你可能马上就会意识到, 这样表示如果词典大了, 会不会向量就太长了? 是的! 但这不是这个表示的最大问题, 这个表示最大的问题是: 它将所有单词视为彼此无关的独立实体。但是, 我们真正想要的表示, 是表示词语的语义, 显然有很多词的语义是相似的, 而不是独立的. 一个好的表示, 应该要把这些相似关系也刻画出来.
现在举一个例子说明为什么要表示词语之间相似:
假设我们正在建立一个语言模型,语料是如下几个句子:
The mathematician ran to the store.
The physicist ran to the store.
The mathematician solved the open problem.
假如有一个句子从没在训练数据中出现过:
The physicist solved the open problem.
其实, 简单的语言模型就能将上面的句子处理的很好, 但是如果我们的语言模型能够使用下面的两个事实, 显然它能做的更好:
我们可以从训练语料里看到mathematician 和 physicist 在句子中的角色是相同的(
句子 1,2), 显然他们之间有某种语义关系。我们能够看到mathematician 曾在语料库的句子中扮演的角色(
句子 3)和现在 新出现的句子里的physicist(句子 4) 一样.
这样, 其实我们可以判断, physicist出现在句子 4 的那个位置, 是有一定道理的?
这就是我们想要表示的相似性:语义相似性,而不是简单地这两个词有相似的正交表示。这是一种通过链接我们学过的知识和我们没学过的知识, 来对抗语料稀疏问题的技巧. 当然, 这个例子取决于一个基本的语言学假设:出现在类似语境中的词在语义上是相互关联的。 这被称为分布假说(Distributional semantics)。
获得稠密的词向量表示
怎么才能搞到一个稠密的词向量表示?这个问题等同于怎么有效的编码词汇之间的语义相似度。
最淳朴的想法就是观察得到一些语义属性,例如通过观察句子1,2 我们能够知道mathematician 和 physicist都能 run
, 那么就可以给这些词关于“is able to run” 这个语义特征一个高分。我们可以用人工定义出很多这样的特征。
如果把每个语义特征当做一个维度,那么我们可以得到如下向量:
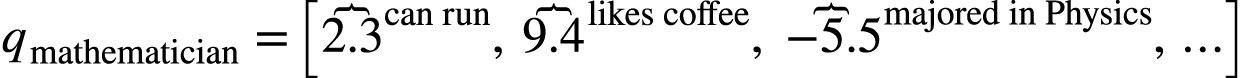
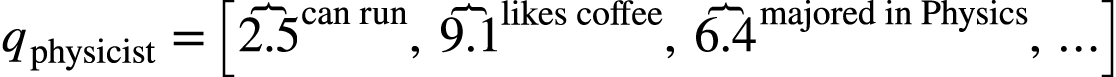
然后我们可以根据下面这个式子来计算这两个向量的余弦相似度:
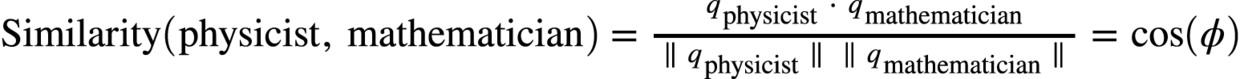
这样相似度被归一化了, 范围为从[-1,1], 越大越相似。
你可以将本节开头的稀疏one-hot向量看做我们刚定义的向量的一个特例,在这个特例中,每个单词之间相似度为0,我们给每个单词一个唯一的语义特征。显然, 刚定义的这些新向量是稠密的,也就是说它们的实体(通常)非零。
显然一个好的表示, 不应该是先人为设计出多个语义属性, 然后在计算出来的, 它应该是被学出来的. 或者说, 是被Embedding出来的, 人不可能完美定义各种语义属性. 尽管人为定义出来的语义属性, 具有天然的可解释性can run, likes coffee, 而学出来的, 大家并不知道它的每一维度表示的是啥.
总而言之, word embedding 可以有效的表示跟你的任务相关的语义信息, 而且可以轻松的embedding进去各种其他信息, 比如词性, 句法树之类的语言学特征.
Word Embeddings in Pytorch
显然, 一个Word Embeddins 矩阵, 应该是|V| x D的, 每一行表示一个词, 每一列是词的某一位词向量表示.
我们首先要把词搞成索引:构建一个word_to_ix的字典, 输入是一个词, 输出是这个词的索引.
然后使用Embedding模块: torch.nn.Embedding,它有两个参数:词典大小和Embedding向量维度。
我们用一个词作为输入, 去预测这个词的上下文(content)来学习Word Embedding.
# 上下文宽度
CONTEXT_SIZE = 2
# embedding 维度
EMBEDDING_DIM = 10
# 训练语料
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
# 我们把训练语料拆成三元组, 如:
# [(['When', 'forty'], 'winters'), (['forty', 'winters'], 'shall'), (['winters', 'shall'], 'besiege')]
trigrams = [ ([test_sentence[i], test_sentence[i+1]], test_sentence[i+2]) for i in xrange(len(test_sentence) - 2) ]
# 构建词语索引字典,
# 比如:word_to_ix = { "hello": 0, "world": 1 }
vocab = set(test_sentence)
word_to_ix = { word: i for i, word in enumerate(vocab) }
# 集成nn.Module 实现Embedding过程
class NGramLanguageModeler(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NGramLanguageModeler, self).__init__()
# 定义Embedding层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 定义线性隐层
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
# 输出层
self.linear2 = nn.Linear(128, vocab_size)
# 编写前向过程
def forward(self, inputs):
embeds = self.embeddings(inputs).view((1, -1))
out = F.relu(self.linear1(embeds))
out = self.linear2(out)
log_probs = F.log_softmax(out)
return log_probs
# 选择损失函数, 优化方法, 实例化网络
losses = []
loss_function = nn.NLLLoss()
model = NGramLanguageModeler(len(vocab), EMBEDDING_DIM, CONTEXT_SIZE)
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 对于每一个epoch
for epoch in xrange(10):
total_loss = torch.Tensor([0])
for context, target in trigrams:
# 准备数据, 打包成Variable
context_idxs = map(lambda w: word_to_ix[w], context)
context_var = autograd.Variable( torch.LongTensor(context_idxs) )
# 清空梯度缓存
model.zero_grad()
# 计算前向过程
log_probs = model(context_var)
# 计算损失
loss = loss_function(log_probs, autograd.Variable(torch.LongTensor([word_to_ix[target]])))
# 反向传播, 优化一步
loss.backward()
optimizer.step()
total_loss += loss.data
losses.append(total_loss)
# 打印一下损失
print losses
############################
[
518.8207
[torch.FloatTensor of size 1]
,
516.3852
[torch.FloatTensor of size 1]
,
513.9670
[torch.FloatTensor of size 1]
,
511.5646
[torch.FloatTensor of size 1]
,
509.1782
[torch.FloatTensor of size 1]
,
506.8095
[torch.FloatTensor of size 1]
,
504.4555
[torch.FloatTensor of size 1]
,
502.1131
[torch.FloatTensor of size 1]
,
499.7835
[torch.FloatTensor of size 1]
,
497.4669
[torch.FloatTensor of size 1]
]明天继续推出:专知PyTorch深度学习教程系列-< NLP系列(二) 基于字符级RNN的姓名分类 >,敬请关注。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“PyTorch”即可得。
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

了解使用专知-获取更多AI知识!

-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“ 阅读原文 ”,使用 专知!




