【专知国庆特刊-PyTorch手把手深度学习教程系列01】一文带你入门优雅的PyTorch
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。值国庆佳节,专知特别推出独家特刊-来自中科院自动化所专知小组博士生huaiwen和Jin创作的-PyTorch教程学习系列。
< 一文带你入门优雅的Pytorch >
< 快速理解系列(一): 图文+代码, 让你快速理解CNN>
< 快速理解系列(二): 图文+代码, 让你快速理解LSTM>
< 快速理解系列(三): 图文+代码, 让你快速理解GAN >
< 快速理解系列(四): 图文+代码, 让你快速理解Dropout >
< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(二) 基于字符级RNN的姓名分类 >
< NLP系列(三) 基于字符级RNN的姓名生成 >
一文带你入门优雅的Pytorch
1、说明
PyTorch是Torch在Python上的衍生(Torch是一个使用Lua语言的神经网络库)和
tensorflow比较PyTorch建立的神经网络是动态的Tensorflow是建立静态图Tensorflow的高度工业化,它的底层代码很那看懂。PyTorch好那么一点点,如果你深入API,你至少能比看Tensorflow多看懂一点点Pytorch的底层在干嘛。
建议:
如果你是学生, 随便选一个学, 或者稍稍偏向
PyTorch, 因为写代码的时候应该更好理解. 懂了一个模块, 转换Tensorflow或者其他的模块都好说.如果是上班了, 跟着你公司来, 公司用什么, 你就用什么, 不要脱群.
2、安装PyTorch
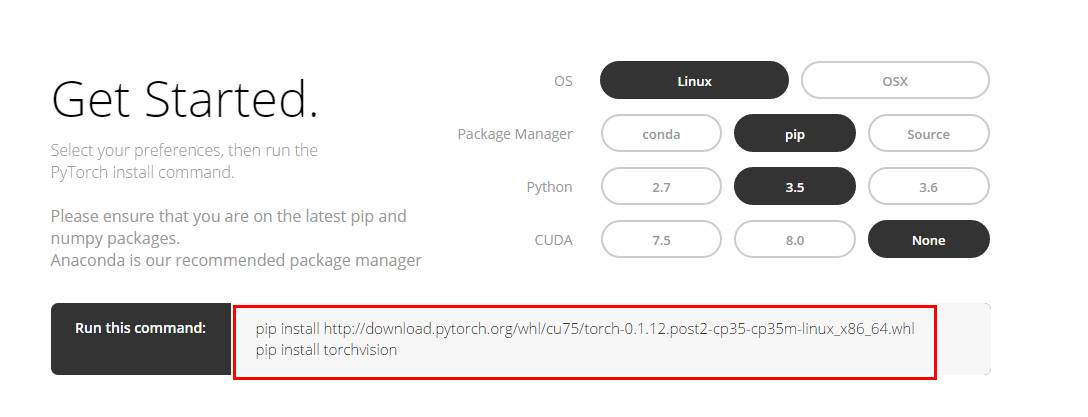
官网:http://pytorch.org/
进入官网之后可以选择对应的安装选项
目前只支持
Linux和MacOS版本执行下面对应的安装命令即可
image
安装PyTorch会安装两个模块
一个是
torch, 一个torchvision,torch是主模块, 用来搭建神经网络的。torchvision是辅模块,有数据库,还有一些已经训练好的神经网络等着你直接用, 比如 (VGG, AlexNet, ResNet).
二、基础知识
1、和Numpy交互
(1)数据转换
import torch
import numpy as np
# 创建一个np array
a = np.array([[1,2], [3,4]])
b = torch.from_numpy(a) # 根据np array创建torch 张量
c = b.numpy() # 根据张量, 导出np array(2)Torch中的运算
API:
torch中tensor的运算和numpy array运算很相似,比如np.abs() --> torch.abs()np.sin() --> torch.sin()等矩阵相乘:
data = [[1,2], [3,4]]tensor = torch.FloatTensor(data) # 转换成32位浮点 tensortorch.mm(tensor, tensor)
2、变量Variable
Variable的组成
(1)什么是Variable
在
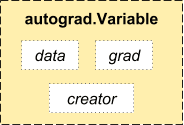
Torch中的Variable由三部分组成,data部分是Torch的Tensor,grad部分是这个Variable的梯度缓存区,creator部分是这个Variable的创造节点. 如果用一个Variable进行计算, 那返回的也是一个同类型的Variable.
(2)使用
对于式子:
y= wx+b
导入包
import torch
from torch.autograd import Variable # torch 中 Variable 模块定义
tensor并放入Variable:requires_grad是参不参与误差反向传播, 要不要计算梯度
x = Variable(torch.Tensor([1]), requires_grad=True)
w = Variable(torch.Tensor([2]), requires_grad=True)
b = Variable(torch.Tensor([3]), requires_grad=True)注意Variable和Tensor的区别:
Variable 计算时, 它在后台默默地搭建着一个庞大的系统, 叫做计算图, computational graph. 将所有的计算步骤 (节点) 都连接起来, 最后进行误差反向传递的时候, 一次性将所有 variable 里面的修改幅度 (梯度) 都计算出来, 而 tensor 只是一个数据结构.
构建计算图
y = w * x + b # y = 2 * x + 3(3)计算梯度
# 对y求梯度
y.backward()
# 打印一下各个变量的梯度
print(x.grad) # y对x的梯度: x.grad = 2
print(w.grad) # y对w的梯度: w.grad = 1
print(b.grad) # y对b的梯度: b.grad = 1(4) Variable里面的数据
直接
print(variable)只会输出Variable形式的数据,在很多时候是用不了的(比如想要用plt画图), 所以我们要转换一下, 将它变成tensor形式.获取 tensor 数据:
print(variable.data) # tensor形式, 然后也可以转而numpy数据:print(variable.data.numpy()) # numpy形式
复杂一点引入矩阵:
创建一个 $ y = w * x + b $
import torch
from torch.autograd import Variable
import torch.nn as nn
# 创建张量(x, y)
x = Variable(torch.randn(5, 3))
y = Variable(torch.randn(5, 2))
# 构建一个线性层
linear = nn.Linear(3, 2)
# 打印一个w 和 b
print ('w: ', linear.weight)
print ('b: ', linear.bias)
# 选择损失函数
loss_func = nn.MSELoss()
# 选择优化方法, 设定学习率
optimizer = torch.optim.SGD(linear.parameters(), lr=0.01)
# 计算前向过程
pred = linear(x)
# 计算损失
loss = loss_func(pred, y)
print('loss: ', loss.data[0])
# 反向传播
loss.backward()
# 打印一下各个变量的梯度
print ('dL/dw: ', linear.weight.grad)
print ('dL/db: ', linear.bias.grad)
# 优化一步
optimizer.step()
# 用优化了一步的参数,再算一遍前向过程,并计算损失
pred = linear(x)
loss = criterion(pred, y)
print('优化了一步之后, 现在的损失是: ', loss.data[0])3、PyTorch中的激活函数
导入包:
import torch.nn.functional as F # 激活函数都在这平时要用到的就这几个.
relu, sigmoid, tanh, softplus激活函数
激活函数的输入输出都是
variable
x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
x = Variable(x)
x_np = x.data.numpy() # 换成 numpy array, 出图时用y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).data.numpy()
y_tanh = F.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
# y_softmax = F.softmax(x) 4、PyTorch中的数据加载器和batch
(1) 生成数据生成并构建Dataset子类
import torch
import torch.utils.data as Data
torch.manual_seed(1)
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10) # 输入数据
y = torch.linspace(10, 1, 10) # 输出数据
# 打包成TensorDataset对象,成为标准数据集
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)(2) 生成batch数据
PyTorch用类torch.utils.data.DataLoader加载数据,并对数据进行采样,生成batch迭代器。
# 创建数据加载器
loader = Data.DataLoader(
dataset=torch_dataset, # TensorDataset类型数据集
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 设置随机洗牌
num_workers=2, # 加载数据的进程个数
)
for epoch in range(3): # 训练3轮
for step, (batch_x, batch_y) in enumerate(loader): # 每一步
# 在这里写训练代码...
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())5、PyTorch中的完整案例和CUDA
PyTorch中使用GPU计算很简单,通过调用.cuda()方法,很容易实现GPU支持.torch.cuda会记录当前选择的GPU,并且分配的所有CUDA张量将在上面创建.可以使用
torch.cuda.device上下文管理器更改所选设备.
下面的例子是对上文中的数据进行训练的完整案例,支持GPU计算.
import torch
from torch.autograd import Variable
import torch.utils.data as Data
'''
超参
'''
torch.manual_seed(1)
BATCH_SIZE = 5
LEARNING_RATE = 0.01
'''
准备数据
'''
train_data_x = torch.linspace(1, 10, 10) # 输入数据
train_data_y = torch.linspace(10, 1, 10) # 输出数据
# 打包成TensorDataset对象,成为标准数据集
torch_dataset = Data.TensorDataset(data_tensor=train_data_x, target_tensor=train_data_y)
# 创建数据加载器
loader = Data.DataLoader(
dataset=torch_dataset, # TensorDataset类型数据集
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 设置随机洗牌
num_workers=2, # 加载数据的进程个数
)
'''
构建网络结构
'''
# 构建一个线性层
linear = nn.Linear(3, 2)
print ('w: ', linear.weight)
print ('b: ', linear.bias)
'''
如果支持GPU
'''
if torch.cuda.is_available():
linear = linear.cuda() # 将网络中的参数和缓存移到GPU显存中
# 选择损失函数
loss_func = nn.MSELoss()
# 选择优化方法, 设定学习率
optimizer = torch.optim.SGD(linear.parameters(), lr=LEARNING_RATE)
'''
训练
'''
for epoch in range(3): # 训练3轮
for step, (x, y) in enumerate(loader): # 每一步
# 如果支持GPU,将训练数据移植GPU显存
if torch.cuda.is_available():
x = Variable(x).cuda()
y = Variable(y).cuda()
output = linear(x) # 预测一下
loss = loss_func(output, b_y) # 计算损失
optimizer.zero_grad() # 清空上一步的梯度缓存
loss.backward() # 计算新梯度, 反向传播
optimizer.step() # 优化一步
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())6、保存和加载模型
保存和加载整个网络
# 保存和加载整个模型, 包括: 网络结构, 模型参数等
torch.save(resnet, 'model.pkl')
model = torch.load('model.pkl')保存和加载网络中的参数
torch.save(resnet.state_dict(), 'params.pkl')
resnet.load_state_dict(torch.load('params.pkl'))7、加载预训练模型
import torchvision
# 下载并加载resnet.
resnet = torchvision.models.resnet18(pretrained=True)
# 如果你只想要finetune模型最顶层的参数
for param in resnet.parameters():
# 将resent的参数设置成不更新
param.requires_grad = False
# 把resnet的全连接层fc 替换成自己设置的线性层nn.Linear
# 比如说,输入维度是resnet.fc.in_features, 输出是100维
resnet.fc = nn.Linear(resnet.fc.in_features, 100)
# 测试一下
images = Variable(torch.randn(10, 3, 256, 256))
outputs = resnet(images)
print (outputs.size()) # (10, 100)8、简单回归
这一节我们来见证神经网络是如何通过简单的形式将一群数据用一条线条来表示. 或者说, 是如何在数据当中找到他们的关系, 然后用神经网络模型来建立一个可以代表他们关系的线条.
建立数据集
我们创建一些假数据来模拟真实的情况. 比如一个一元二次函数: y = a * x^2 + b, 我们给 y 数据加上一点噪声来更加真实的展示它.
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 张量 x: (100, 1)
y = x.pow(2) + 0.2*torch.rand(x.size()) # 加入噪声的张量 y: (100, 1)
# 将张量转为 Variable
x, y = Variable(x), Variable(y)
# 画一下
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()建立神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐层
self.relu = torch.nn.ReLU() # 选择激活层
self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层
def forward(self, x):
x = self.hidden(x) # 计算隐层
x = self.relu(x) # 计算激活层
x = self.predict(x) # 输出层
return x
net = Net(n_feature=1, n_hidden=10, n_output=1) # 定义网络
print(net) # 打印网络结构训练网络
# 选择损失函数和优化方法
loss_func = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
plt.ion() # hold住图
for t in range(100):
prediction = net(x) # 用网络预测一下
loss = loss_func(prediction, y) # 计算损失
optimizer.zero_grad() # 清除上一步的梯度
loss.backward() # 反向传播, 计算梯度
optimizer.step() # 优化一步
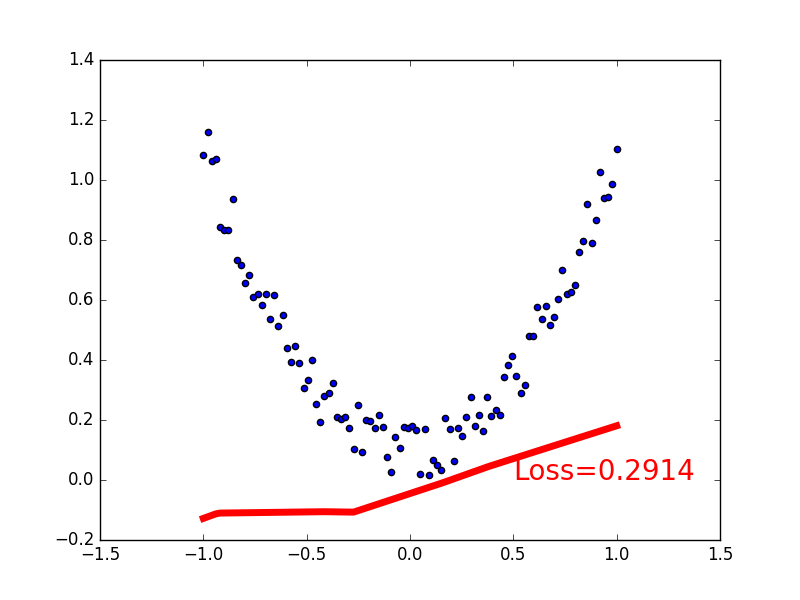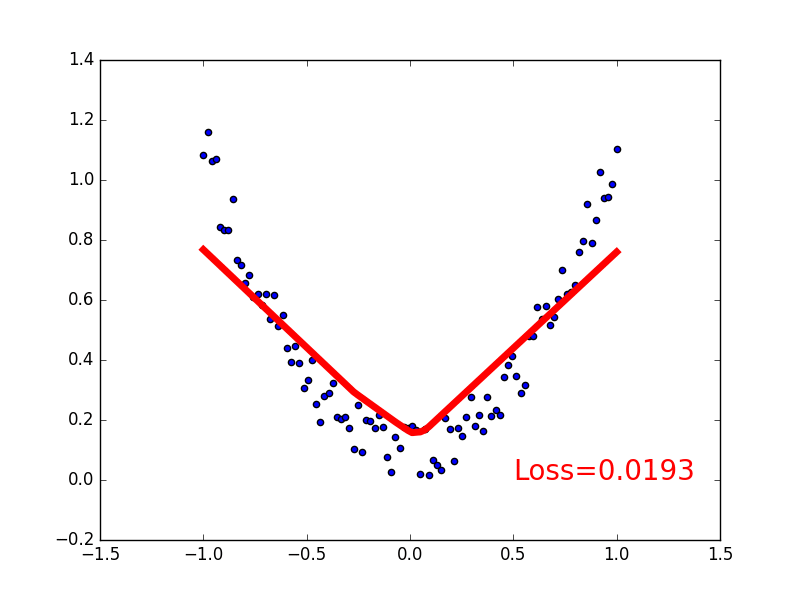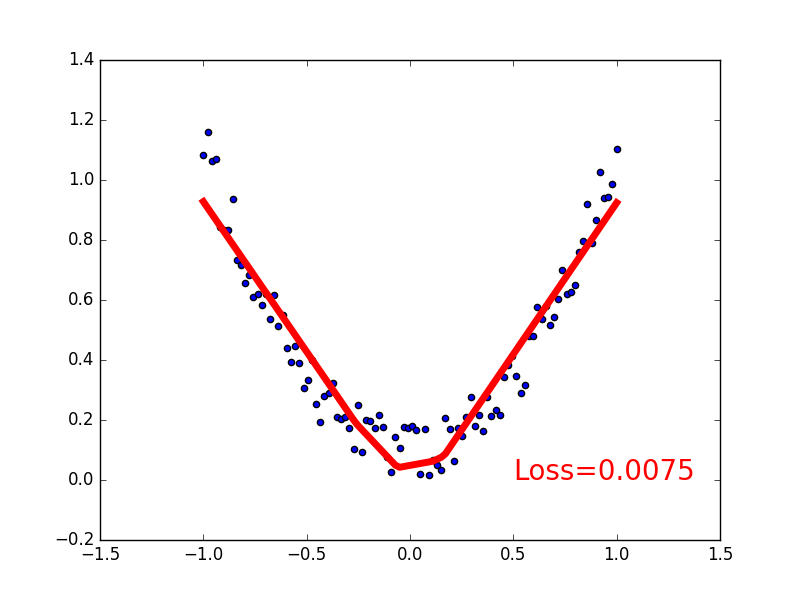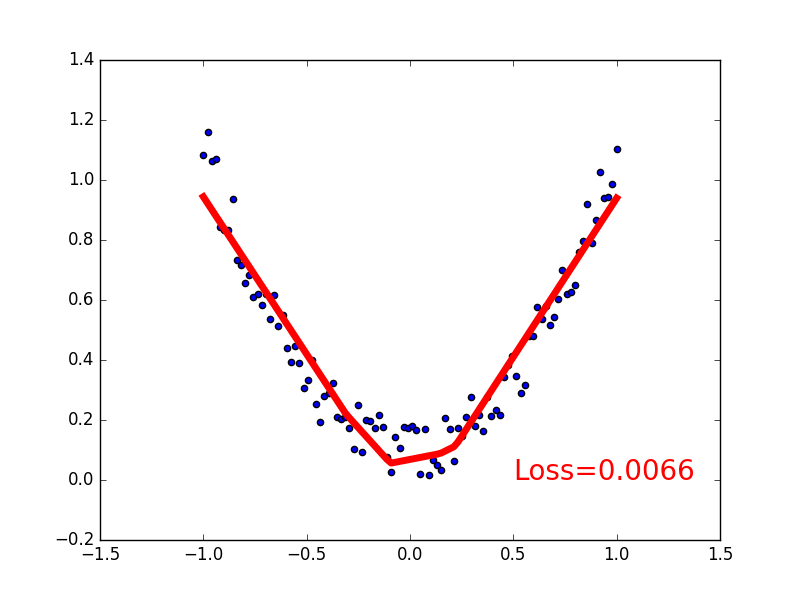
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()9、快速构建序列网络
torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。另外,也可以传入一个有序模块。 为了更容易理解,官方给出了一些案例:
# Sequential使用实例
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Sequential with OrderedDict使用实例
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))为了方便比较,我们先用普通方法搭建一个神经网络。
import torch
# 继承方式实现, 能够自定义forward
class ModuleNet(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(ModuleNet, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐层
self.relu = torch.nn.ReLU() # 选择激活层
self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层
def forward(self, x):
x = self.hidden(x) # 计算隐层
x = self.relu(x) # 计算激活层
x = self.predict(x) # 输出层
return x
module_net = ModuleNet(1, 10, 1)上面ModuleNet继承了一个torch.nn.Module中的神经网络结构, 然后对其进行了修改;接下来我们来使用torch.nn.Sequential来快速搭建一个神经网络。
# 用序列化工具, 给予Pytorch 内部集成的网络层 快速搭建
seq_net = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)我们来打印一下2个神经网络的数据,查看区别:
print(module_net) # 打印网络结构
"""
ModuleNet (
(hidden): Linear (1 -> 10)
(relu): ReLU ()
(predict): Linear (10 -> 1)
)
"""
print(seq_net) # 打印网络结构
"""
Sequential (
(0): Linear (1 -> 10)
(1): ReLU ()
(2): Linear (10 -> 1)
)
"""reference:
http://lawlite.me/2017/05/10/PyTorch/#一、PyTorch介绍
http://pytorch.org/docs/master/torch.html
https://morvanzhou.github.io/tutorials/machine-learning/torch/
http://blog.csdn.net/victoriaw/article/details/72356453
http://yongyitang92.github.io/2017/01/21/20170121-Pytroch%E5%85%A5%E9%97%A8%E7%AC%94%E8%AE%B0/
明天继续推出:专知PyTorch深度学习教程系列-< 快速理解系列(一): 图文+代码, 让你快速理解CNN>,敬请关注。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“PyTorch”即可得。
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

了解使用专知-获取更多AI知识!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“ 阅读原文 ”,使用 专知!




