主动学习:标注的一颗救心丸
机器学习领域的不断发展催生了各色各样的学习类算法。其中针对有监督、半监督、无监督学习策略的研究与应用相对广泛且成熟。但由于问题本身往往设限,传统机器学习、深度学习方法在实践中往往很难适配问题本身,逐渐延伸出了主动学习、持续学习、迁移学习等等。
机器学习算法可以很好的解决类别归属的问题。 但监督类学习针对未经标注的生数据集却无法直接使用。而单纯的无监督类学习,由于其相似归纳的特点,预期效果往往不如前者。
本文旨在有限数据量、人力、时间成本的问题设限下,介绍主动学习算法原理及效果分析。
1.问题背景

对于算法工程师而言,数据处理工作(尤其是数据标注工作)往往耗时较多,严重影响了算法迭代、研发效率且开销昂贵。而数据标注工作又是算法迭代过程中的重要一环。因此,在有限资源条件下,如何保质保量快速标注并且缩小不同人员标注质量方差成为标注工作的难点。
2.主动学习算法简介
2.1 什么是主动学习?
由问题背景可知,传统的算法不能适配整个标注过程。因此,主动学习作为一种特殊的机器学习形态被提出。
什么是主动学习?具体一点,老师给学生讲解习题存在3种方式。
-
方式A:课上时间只讲解经典类习题,简单习题由学生自己运用所学知识课下完成。 -
方式B:完全放纵学生,不讲解任何习题,任凭学生自学; -
方式C:课上时间无论是经典习题还是简单习题通透给学生讲解。
对比三种方式,不难发现方式A效果远好于方式B、方式C。因此,继续借用老师讲解习题的举例,将主动学习训练过程例化为:课堂上,老师选择出一些经典类型的问题,将经典题目讲解给学生,反复讲解直到经典题目讲解完或学生考试都考到满分为止,简单题目课下时间由学生自己完成。这样便达到了老师课堂中高质量教学的目的,老师节省了时间,学生也取得了满意成绩。
最后,我们将主动学习训练过程中概括为通过策略查询出信息密度最高的数据样本,反馈给标注人员标注,直到达到结束条件(模型效果达到最优、数据样本标注完……),即可结束训练。
2.2 主动学习与传统算法的区别?
看完上述简介,大家对主动学习应该有了宏观认识。但作为一种特殊的问题设限类算法,确实存在以下不同之处。
| 有监督 | 无监督 | 半监督 | 主动学习 | |
|---|---|---|---|---|
| 数据准备 | 全量标注 | 无标注 | 部分标注 | 部分标注或无标注 |
| 训练过程交互 | 无交互 | 无交互 | 无交互 | 有交互 |
可以看出,与传统算法相比,主动学习更类似于半监督学习。实际上,并没有严格定义其属于哪一范畴。虽然主动学习与半监督学习数据准备上相似且二者训练过程中均利用了未标注数据,但本质上半监督学习训练过程中不需要人工干预和交互。因此,主动学习也是针对半监督学习监督力不足特殊问题提出的特定解决方法。
2.3 主动学习算法包含哪些部分?工作原理?
在以上举例中,方式A的教授习题方式效果最佳。从中可以提炼出以下关键元素:习题、老师、学生、老师选择经典题目的策略、结束条件。我们将其映射为数据、标注人员、分类器、查询筛选策略、训练结束条件。因此主动学习模型可以表示为A=(C,L,S,Q,U) 。其中C表示分类器、L表示部分标注完样本集、S表示标注人员、Q表示筛选最优价值数据的查询筛选策略、U表示除L外未被标注的样本集。
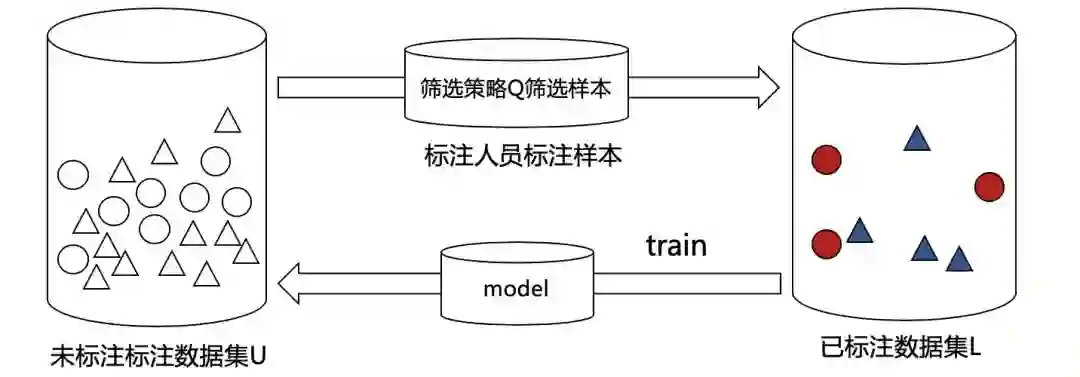
-
上图过程可概述为以下步骤:
-
确定查询筛选策略Q。 -
筛选出最优价值数据样本。 -
标注人员标注最优价值数据样本。 -
将新标注数据加入至训练数据。 -
模型基于最新训练数据再训练,直到达到停止条件。
-
算法伪代码如下图所示:

3. 主动学习查询筛选策略?
3.1 查询筛选主流方式
查询筛选策略作为主动学习的最关键步骤之一,其往往直接决定了模型性能,使得挑选出来的数据样本确实对模型性能提升最佳或语义涵盖范围最广。发展到现在,查询筛选过程主要演化为以下三种方式。
-
-
Membership Query Synthesis -
-
stream-based selective Sampling -
-
Pool-based Sampling
方式1既通过模型生成新的训练数据,来达到数据增强的目的。相比方式2、方式3,可控性较差。
方式2顾名思义,数据排好序后以流的方式给到模型判断是否学习。
方式3由于可控性较好,研究相对成熟。既上述中将标注、未标注数据放到不同池子,通过查询选择策略从中挑选数据给模型训练。
3.2 查询策略的选择
在以上内容中,我们知道了查询策略的目的是选择出最优于模型训练的(既模型预测时最不确定的样本)或语义涵盖范围最广的数据样本。因此,不确定性策略也称为人们在应用主动学习时最常用的策略。
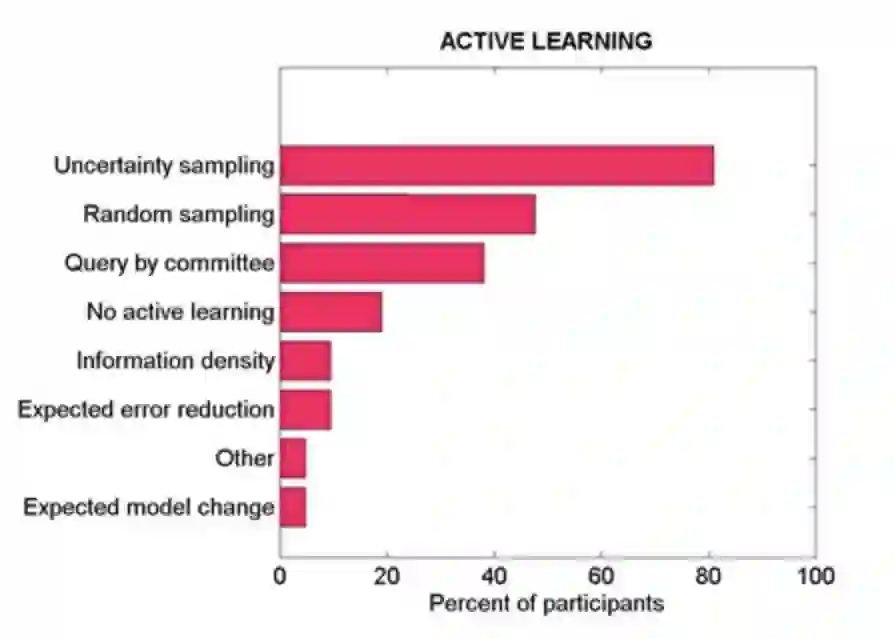
通过上图,可以看出不确定性策略已经成为主动学习的主流策略。接下来我们也以不确定性策略切入来介绍几种常用的查询策略。
-
1. 基于熵的不确定性策略
首先介绍的是基于熵的选择策略。现阶段,基于熵的选择策略是最有效且研究范围最广的策略。也正是因为熵策略的存在,深度学习中各种算法也能够与主动学习组合,深度主动学习也成为最新研究方向。传统熵值定义如下。
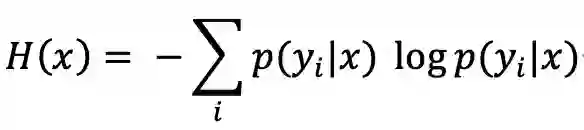
上式中,p(y_i|x)表示在给定数据样本x情况下标签属于y_i的概率。其中H(x)越大,表示信息熵越大,模型对样本的预测越不确定。p(y_i│x)=0.5时,模型对样本预测越模糊,此时熵H(x)达到最高为1。
-
2. 基于置信度的不确定性策略
其次,基于置信度的选择策略也是常用的方法之一。与基于熵策略类似,其目的也是寻找未标注数据样本中最难判别的数据(信息量丰富),表示策略对该数据没有足够的信心。公式如下所示。
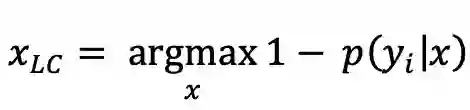
-
3. 基于间隔的不确定性策略
最后介绍的是一种基于间隔的不确定性策略。相比上述两种不确定性策略。基于间隔的策略不单单是只考虑某一个预测概率,其统计置信度最大的前两个类别做差,差值越小,模型对样本x对不确定性越大,差值越大,模型对样本x对不确定性越小。公式如下。
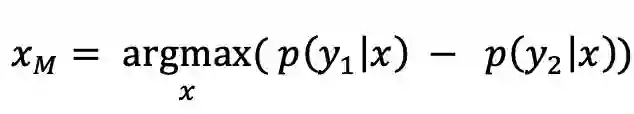
其中p(y_1│x)表示在给定数据样本x情况下置信度标签最大概率,p(y_2│x)置信度第二大对的概率值。
不确定性策略中,还有很多种策略,机器学习、深度学习中的损失函数均可与主动学习相结合。以上仅仅介绍了成熟、推广度较高的三种策略帮助理解主动学习中的选择策略。
3.3 主动学习的发展现状?
最近还有很多工作依然在关注选择筛选策略的制定上,除此之外,针对主动学习的研究还逐渐的关注整个学习流程。主要包括以下问题。
-
-
虽然与传统半监督学习,通过部分人工干预增强了监督力,但仍存在标注信息不准确的情况,延缓模型训练效率。 -
-
与主流学习类算法相结合。比如,基于聚类的主动学习,通过对每个层次上的类中心打标记来代替该层次上的类标记,然后选择出具有错误标记的类中心加入训练集不断训练等等。通过结合的方式来提高模型学习效率和对新问题的打击能力。
4.效果验证
上述说了主动学习的一些理论,具体主动学习效果如何?或到底提效如何?想必大家都想了解。下面通过简单的实验论证一下。
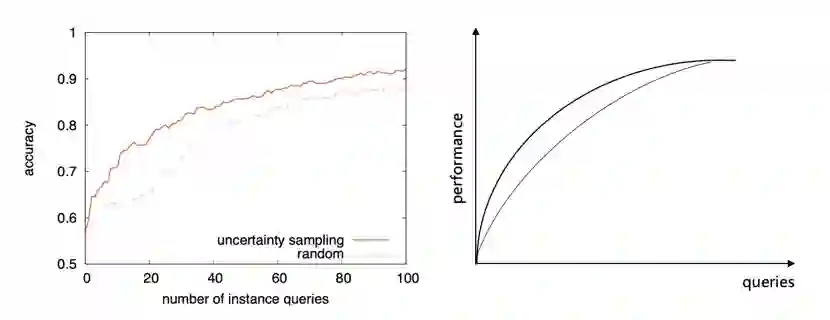
上图为Burr Settles《Active Learning Literature Survey》中通过实验得到的结果和主动学习理论上可达到的效果。本实验在与前者尽可能一致的情况下进行。
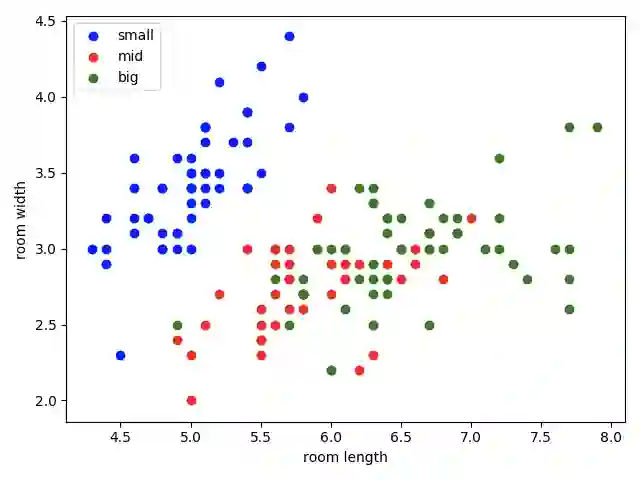
数据准备方面,我们随机初始化了150个样本。样本分布如下图所示。
| 实验设置 | 值 |
|---|---|
| 训练集 | 105/个 |
| 测试集 | 45/个 |
| 初始标注数 | 5/个 |
| 未标注数据集 | 100/个 |
| 迭代次数 | 10/轮 |
| 选择策略 | 不确定策略 vs Random |
| 评价指标 | 准确率 |
| batch_size | 1 |
实验结果如下图所示。
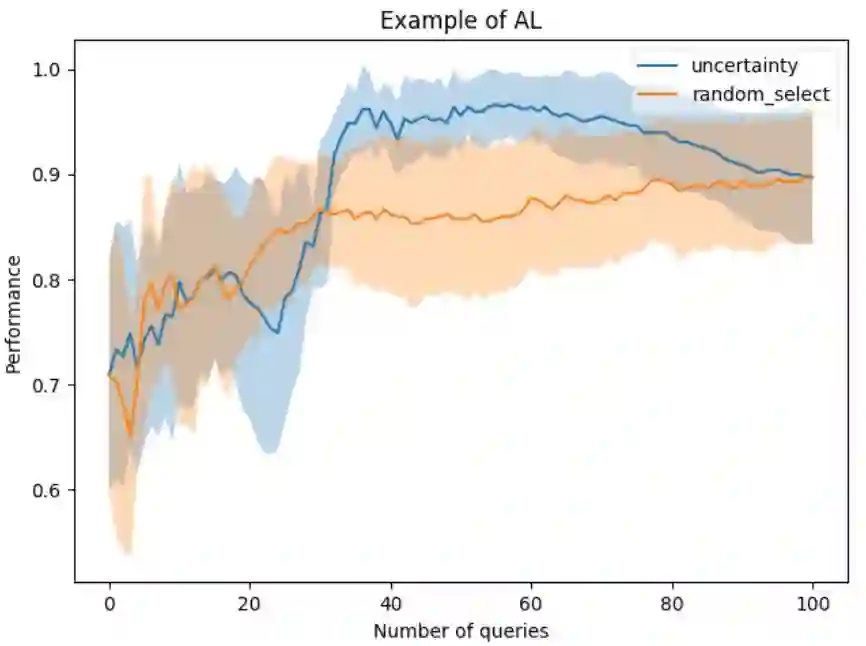
通过实验结果可以看出:
-
-
32次query之前,不确定性策略与随机选取策略浮动差异不大,不确定性策略准确率活动范围均可包含随机选取策略。 -
-
不确定性策略与随机选取策略在32次query之后出现明显的差异。不确定策略在拟合速度上明显快于随机策略。在55次query左右不确定性策略达到最优,效果相差9%左右。 -
-
99次左右query左右不确定性与随机策略重合。
通过上图可以看出,主动学习在模型训练时能够提升效率。达到预期目的。看到这想必大家已经对主动学习有了大概认识,祝大家标注愉快!
5.参考资料
[1] Burr Settles. Active Learning Literature Survey
[2] 黄圣君 主动学习年度进展|VALSE2018
[3] 主动学习-Active Learning:如何减少标注代价 https://zhuanlan.zhihu.com/p/39367595
[4] [ICLR2018]Deep Active Learning for Named Entity Recognition
[5] UT Austin博士生沈彦尧:基于深度主动学习的命名实体识别 | 分享总结。
[6] 杨文柱 主动学习算法研究进展
作者介绍
朱成浩,2019年6月毕业于黑龙江大学自然语言处理实验室,毕业后加入贝壳找房语言智能与搜索部,负责标注平台建设等工作。
本文转载自公众号:贝壳智搜,作者应用架构团队
推荐阅读
Siamese network 孪生神经网络--一个简单神奇的结构
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



