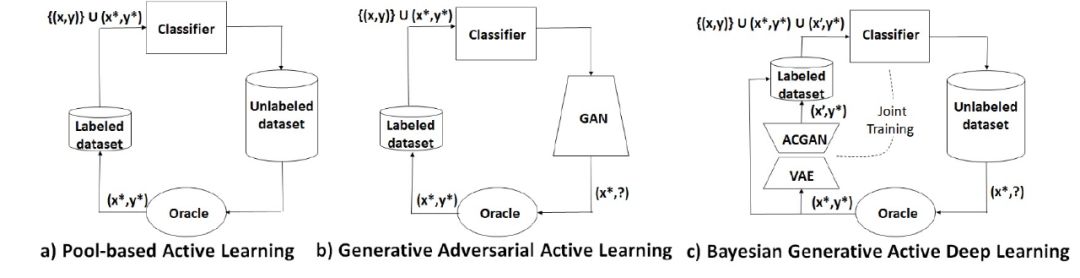
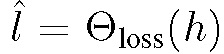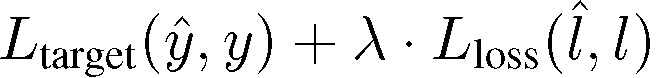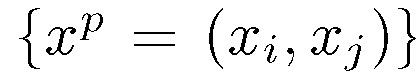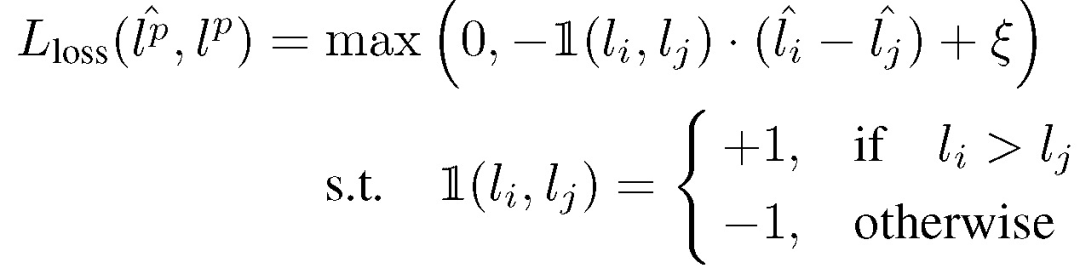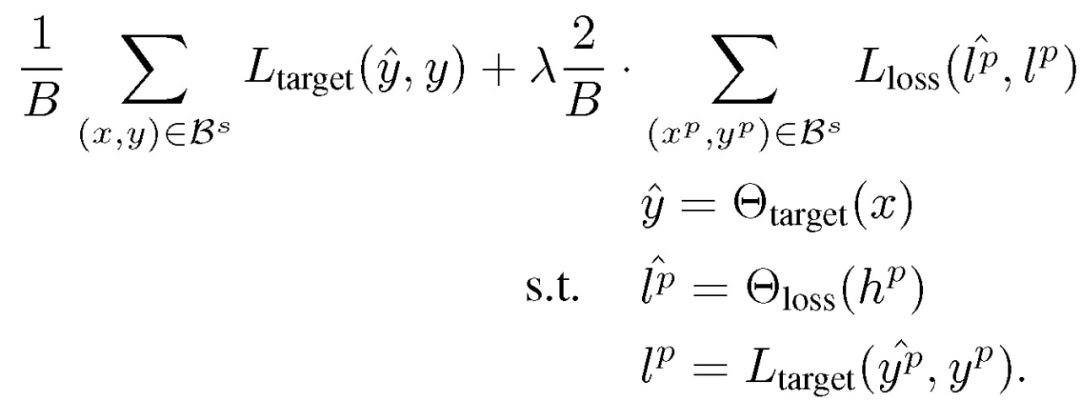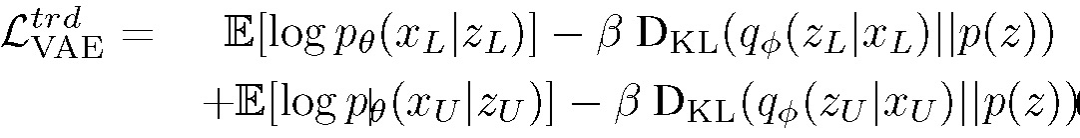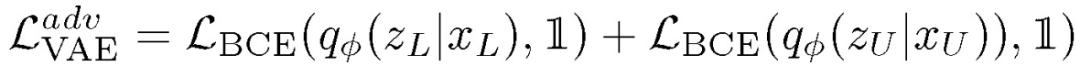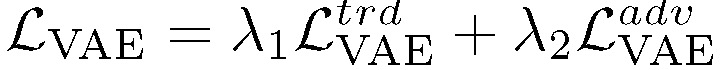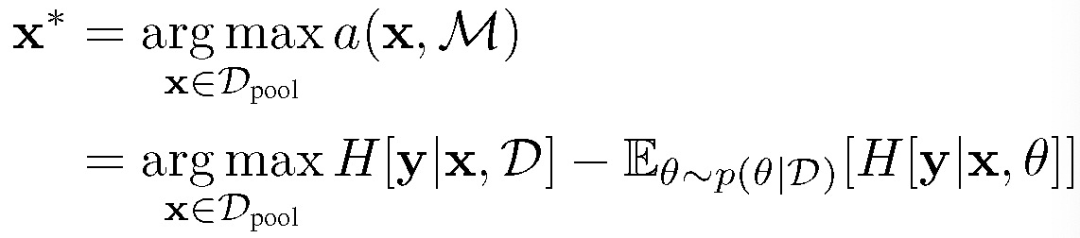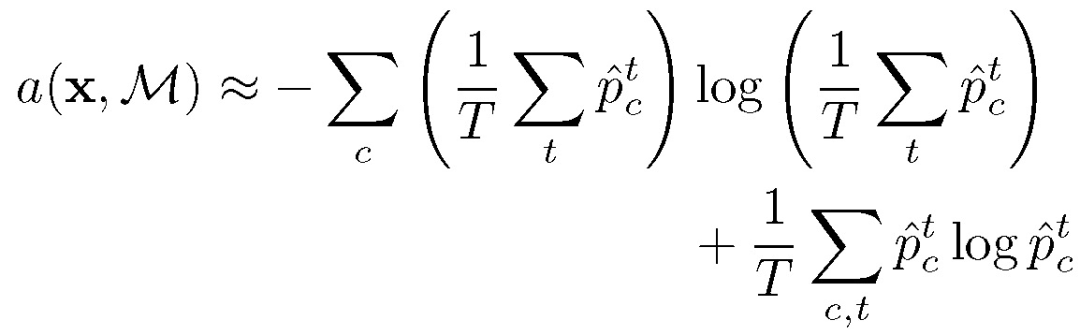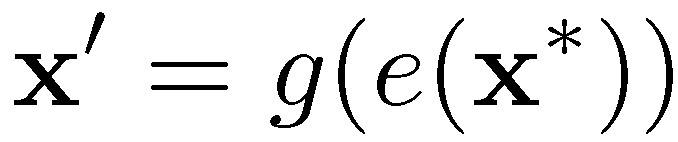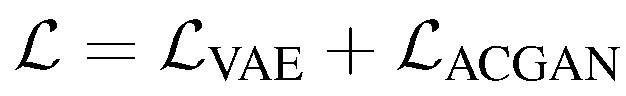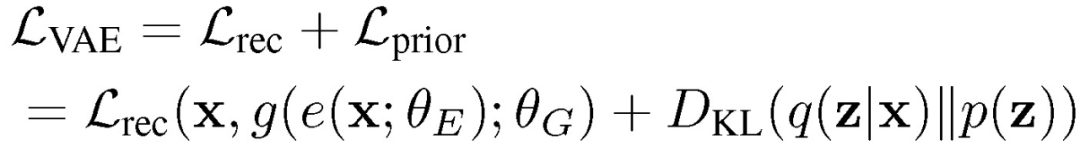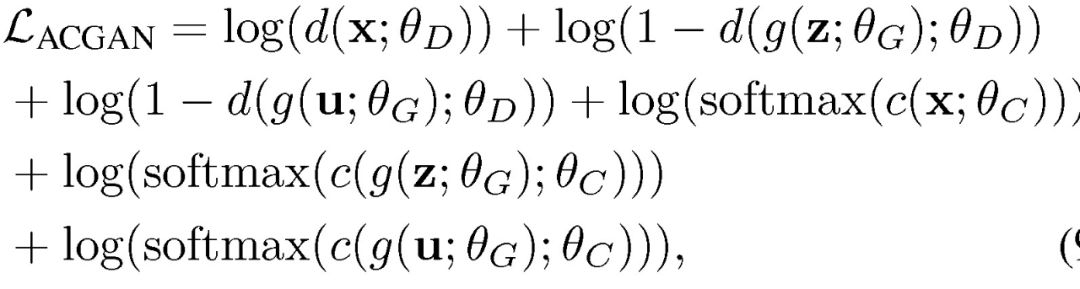目前推广应用的机器学习方法或模型主要解决分类问题,即给定一组数据(文本、图像、视频等),判断数据类别或将同类数据归类等,训练过程依赖于已标注类别的训练数据集。在实验条件下,这些方法或模型可以通过大规模的训练集获得较好的处理效果。然而在应用场景下,能够得到的数据实际上都没有进行人工标注处理,对这些数据进行类别标注所耗费的人力成本和时间成本非常巨大。在一些专门的应用领域,例如医学图像处理,只有专门学科的专业医生能够完成对医学影像图像的数据标注。显然,在这种情况下必须依赖大规模训练集才能使用的方法或模型都不再适用。为了减少对已标注数据的依赖,研究人员提出了主动学习(Active Learning)方法。主动学习通过某种策略找到未进行类别标注的样本数据中最有价值的数据,交由专家进行人工标注后,将标注数据及其类别标签纳入到训练集中迭代优化分类模型,改进模型的处理效果。
根据最有价值样本数据的获取方式区分,当前主动学习方法主要包括基于池的查询获取方法(query-acquiring/pool-based)和查询合成方法(query-synthesizing)两种。近年来提出的主动学习主要都是查询获取方法,即通过设计查询策略(抽样规则)来选择最具有价值信息的样本数据。与查询获取方法「选择(select)」样本的处理方式不同,查询合成方法「生成(generate)」样本。查询合成方法利用生成模型,例如生成式对抗网络(GAN, Generative Adversarial Networks)等,直接生成样本数据用于模型训练。
我们从 2019 年机器学习会议中选出三篇关于主动学习方法的文章进行针对性的分析,这三篇文章为:
Learning loss for active learning(CVPR 2019,oral)
Variational Adversarial Active Learning (ICCV 2019,oral)
Bayesian Generative Active Deep Learning (ICML 2019)
其中,前两篇提出基于池的查询获取方法:《Learning loss for active learning》通过添加损失函数设计一种任务不可知的主动学习方法,《Variational Adversarial Active Learning》设计了一种利用 VAE 和对抗网络来学习潜在空间中已标注数据分布情况的查询策略。第三篇 ICML 的文章《Bayesian Generative Active Deep Learning》介绍了一种利用对抗性网络的查询合成方法。
1. Learning Loss for Active Learning(CVPR 2019)
![]()
原文地址:https://arxiv.org/abs/1905.03677?context=cs.CV
主动学习的一个研究热点为抽样策略(准则)的设计,即通过改进样本不确定性度量方式、引入委员会投票模式、采用期望误差以及考虑多样性准则等方法,设计主动学习的抽样策略(准则)。然而,由于不同的机器学习任务不同,使用的数据特征不同等问题,抽样策略(准则)一般是针对目标任务进行设计,不具备普适性,例如在某一类机器学习任务中效果好的模型(例如文本分析),直接应用在其它任务中效果很差(例如图像分类)。
来自韩国 KAIST 的两位学者提出了一种新的主动学习方法:学习损失函数的主动学习模型(Learning Loss for Active Learning)。本文的思路主要来源于深度学习,即不管任务是什么、任务量有多大以及任务的体系结构有多么复杂,学习目的就是最小化损失函数而与具体任务无关。本文提出的主动学习方法引入一个「损失预测模块」,通过学习损失预测模块来估计未标注数据的损失值。无论目标任务是什么,模型都执行同样的损失函数优化,因此损失预测模块是任务不可知的,该方法可以应用于任何使用深度网络的机器学习。
提出了一种简单而有效的主动学习方法,该方法具有损失预测模块,可直接应用于深度网络的任何任务。
利用现有的网络体系结构,通过分类、回归和混合三个学习任务来评估所提出的方法。
本文提出的学习损失函数的主动学习模型主要由两部分组成:目标模块和损失预测模块。其中目标模块的函数为:
![]()
![]()
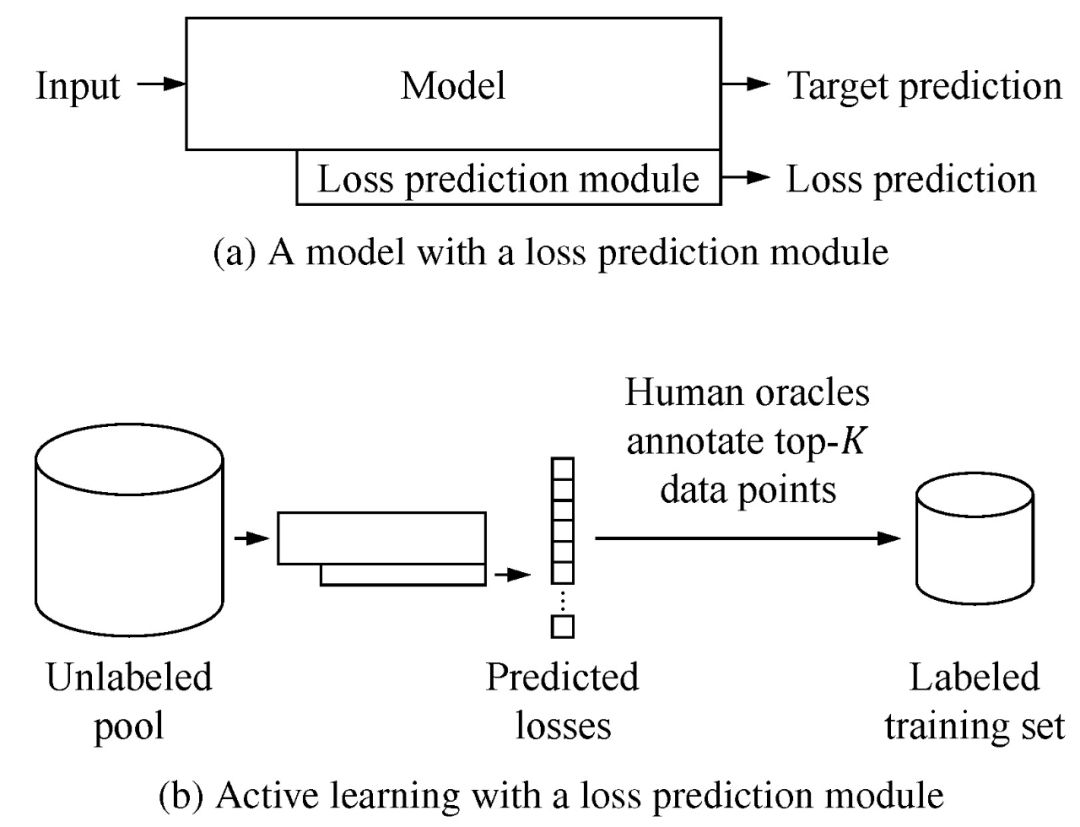
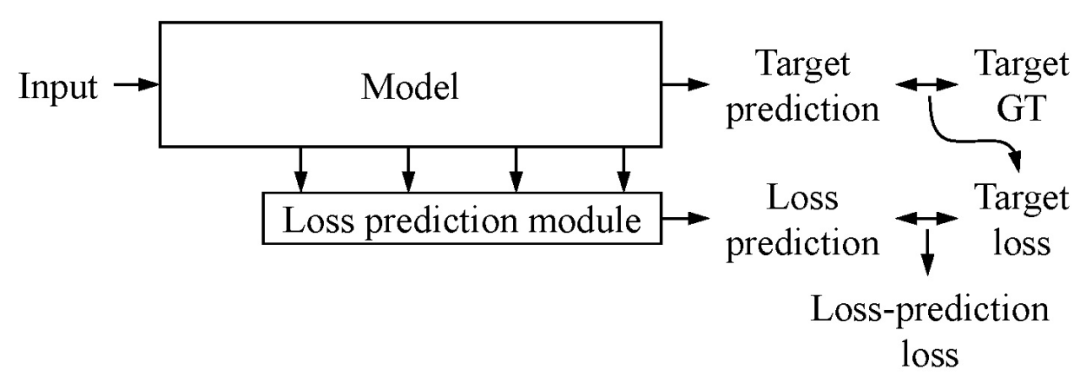
h 表示从目标模块的多个隐藏层中提取的样本数据 x 的特征集。初始化已标注数据集后,通过学习得到初始化目标函数和损失预测函数。在主动学习过程中,利用损失预测模块对未标注池中的所有数据进行评估,得到数据损失对。之后人工标注 K 个损失最大的数据(Top-K),更新已标注数据集,重复循环,直到达到满意的性能。图 1 给出本文算法的处理过程。其中图 1(a)表示利用目标模块基于输入数据生成目标预测值,利用损失预测模块基于目标模块的隐藏层生成损失预测值。图 1(b)表示利用损失预测模块评估未标注数据集中的数据,找到 Top-K 预测损失值的数据,完成专家人工标注后将这些数据及类别信息添加到已标注的训练集中。
![]()
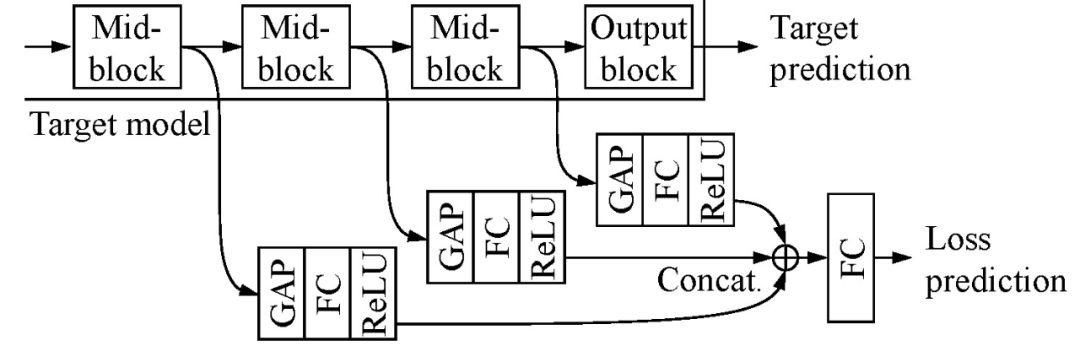
损失预测模块是本文算法的核心,其目标是最大限度地降低主动学习过程中针对不确定性的学习成本。损失预测模块的特点为(1)比目标模块小得多(2)与目标模块同时学习,无需增加额外学习过程。损失预测模块的输入为目标模块的中间层提取的多层特征映射,这些多重连接的特征值使得损耗预测模块能够有效利用层间的有用信息进行损失预测。
首先,通过一个全局平均池(global average pooling, GAP)层和一个全连接层(full connected layer,FC),将每个输入特征映射简化为一个固定维度的特征向量。然后,连接所有特征并输入另一个全连接层,产生一个标量值作为预测损失。损失预测模块的结构见图 2。损失预测模块与目标模块的多个层次相连接,将多级特征融合并映射到一个标量值作为损失预测。
![]()
最后,讨论损失预测模块的计算方式。损失预测模块的计算公式如下:
![]()
第一部分为目标模块的目标注释值与预测值之间的损失值,第二部分为损失预测模块计算得到的损失值。给定输入,目标模型输出目标预测,损失预测模块输出预测损失。目标预测和目标注释用于计算目标损失,从而完成目标模型的学习。此外,目标损失还将作为损失预测模块的真值损失,用于计算预测损失。具体计算过程见图 3。
![]()
本文没有直接使用均方误差(the mean square error,MSE) 定义损失函数,而是进行样本数据对的比较。给定大小为 B 的小批量数据集,能够生成 B/2 个数据对,例如
![]()
下标 P 表示一个数据对,B 应该是一个偶数。然后,通过考虑一对损失预测之间的差异来学习损失预测模块:
![]()
给定小批量 B,同时学习目标模块和损失预测模块的损失函数为:
![]()
为了验证该方法的任务普适性,本文选择了三个目标任务进行实验,包括图像分类(分类任务),目标检测(分类和回归的混合任务),人体姿态估计(典型回归问题)。
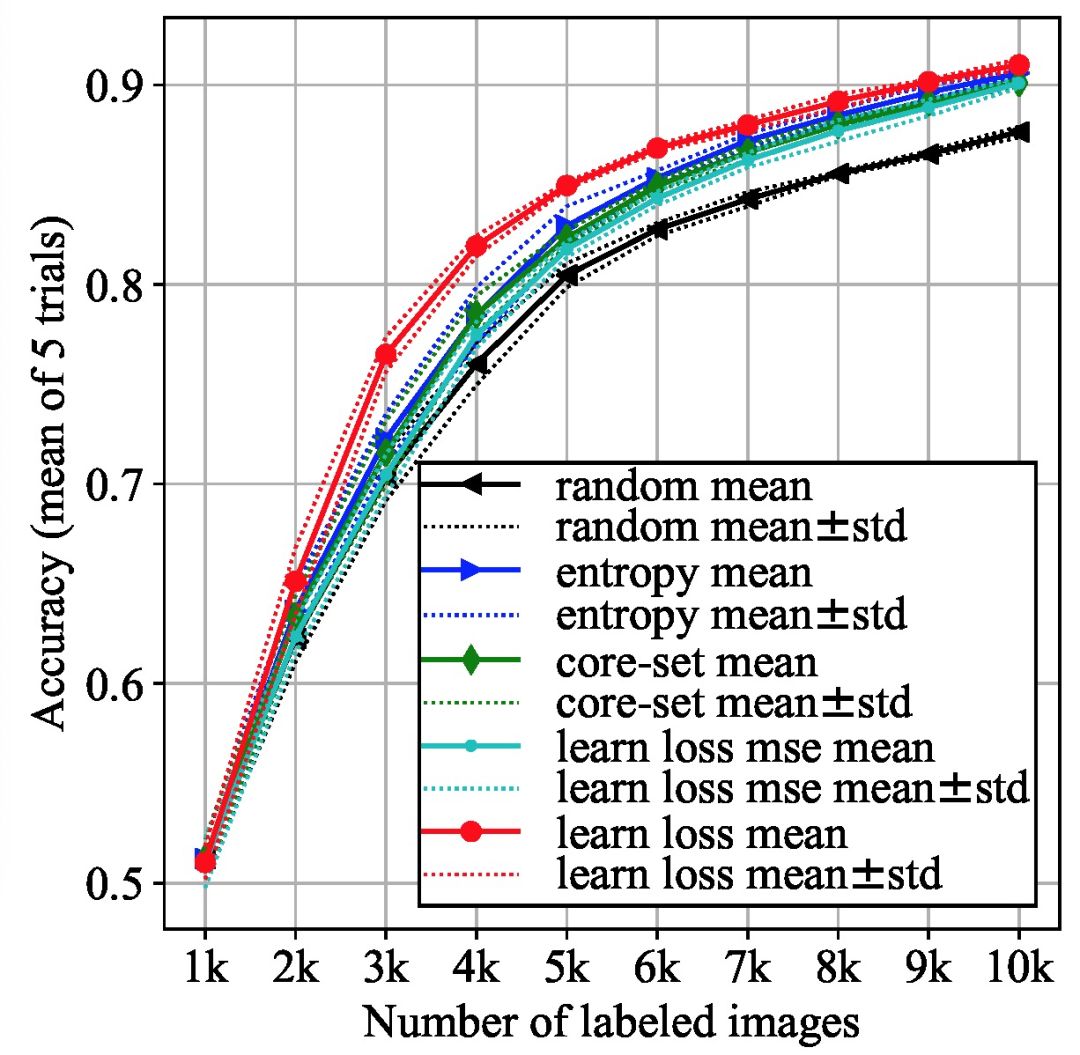
数据库:本文选择 CIFAR-10 数据库,使用其中 50000 张图片作为训练集、10000 张图片作为测试集。由于训练集数据量非常大,本文在每个主动学习循环阶段选择一个随机子集(大小为 10000),从中选取 K 最不确定样本。
目标模块:ResNet-18。
损失预测模块:ResNet-18 由 4 个基本块组成 {convi_1; convi_2 j| i=2; 3; 4; 5},每个模块有两层。将损失预测模块连接到每个基本块,利用块中的 4 个特性来估计损失。
![]()
图 4 中每个点均为使用不同的初始标记数据集进行 5 次实验的平均值。由实验结果可知,本文提出的算法在 CIFAR-10 库中的效果最好。
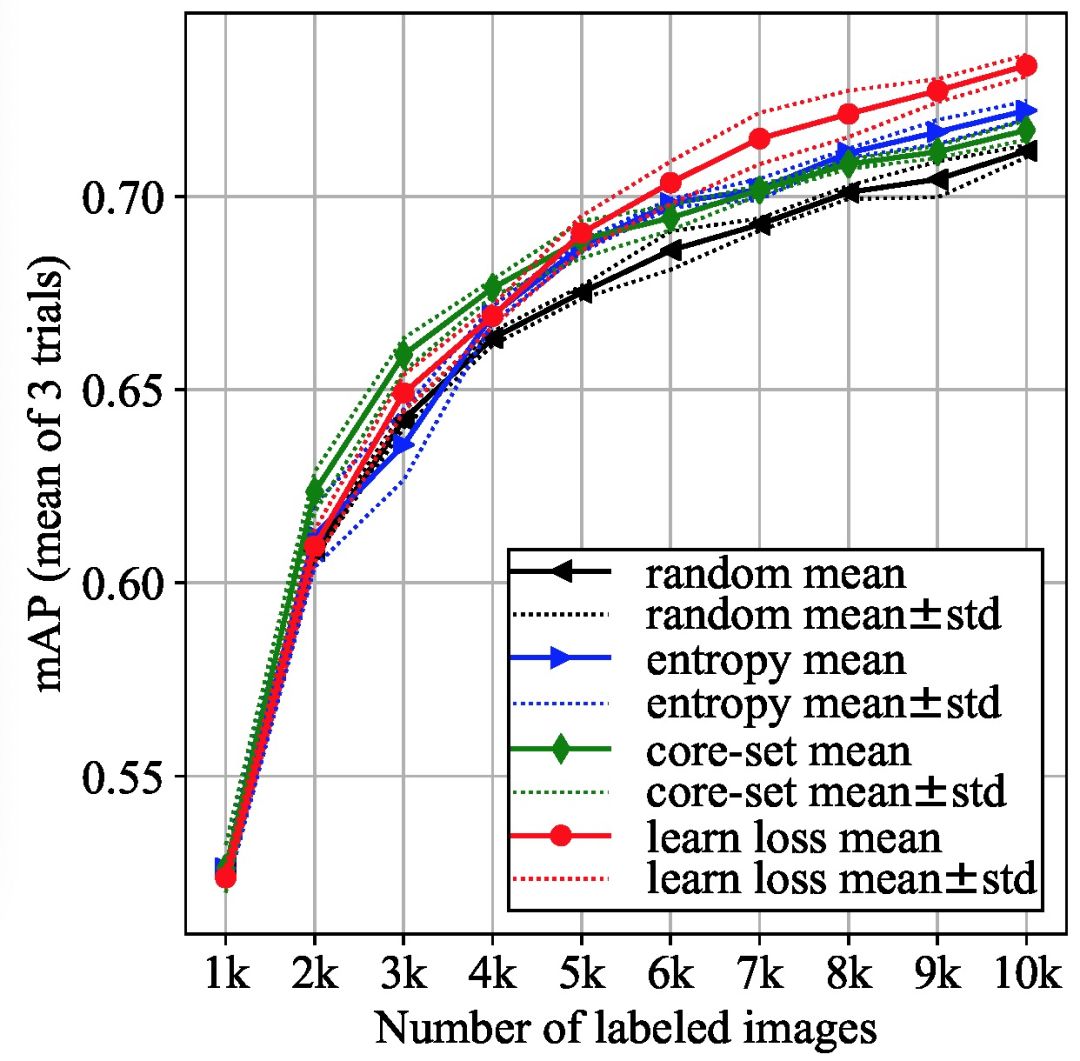
数据库:本文选择 PASCAL VOC 2007+2010 数据库。由于训练集数据量不大,实验不需选择随机子集抽取 K 最不确定样本。
目标模块:Single Shot Multibox Detector (SSD)。
损失预测模块:SSD 从 6 级特征映射中提取边界框及其类 {convi | i=4_3; 7; 8_2; 9_2; 10_2; 11_2}。将损失预测模块连接到每个基本块,利用块中的 6 个特性来估计损失。
实验对比算法:随机抽样(random sampling),基于熵的采样(entropy-based sampling),芯组采样(core-set sampling)。
![]()
图5:在PASCAL VOC 2007+2012上的主动学习目标检测结果
图 5 中每个点均为使用不同的初始标注数据集进行 3 次实验的平均值。由实验结果可知,本文提出的算法在 PASCAL VOC 库中的效果最好。
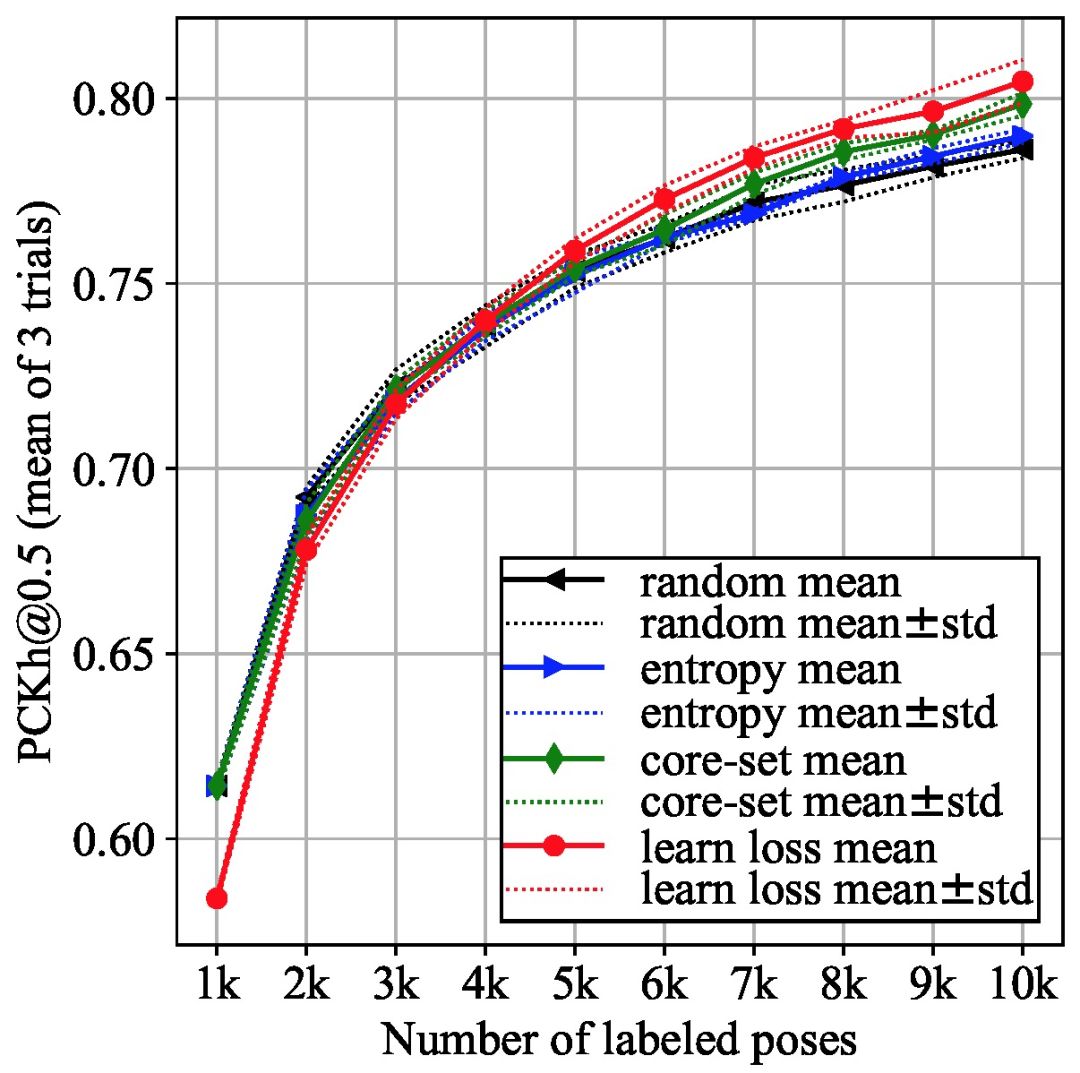
数据库:本文选择 MPII 数据库。由于训练集数据量非常大,本文在每个主动学习循环阶段选择一个随机子集(大小为 5000),从中选取 K 最不确定样本。
目标模块:Stacked Hourglass Networks。
损失预测模块:Stacked Hourglass Networks 的特征图为 (H,W,C)=(64,64,256)。本文使用两个特征图,将损失预测模块连接到每个图中,利用 2 个特性来估计损失。
实验对比算法:随机抽样(random sampling),基于熵的采样(entropy-based sampling),芯组采样(core-set sampling)。
![]()
图 6 中每个点均为使用不同的初始标注数据集进行 3 次实验的平均值。由实验结果可知,本文提出的算法在 MPII 库中的效果最好。
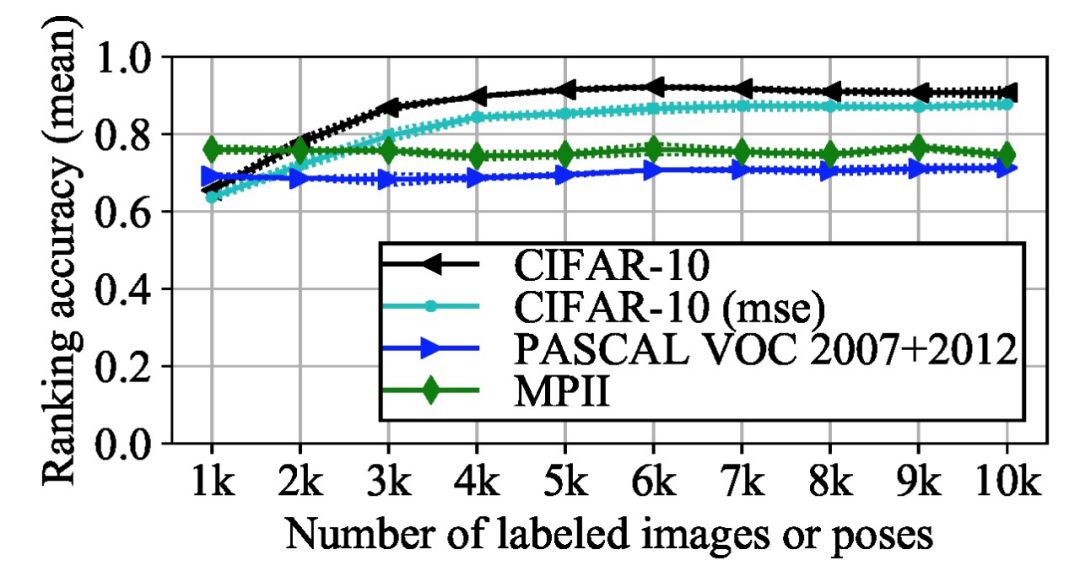
图 7 为本文提出的算法在不同数据库中损失预测的准确度。对于一对数据点,如果预测结果为真,我们给出 1 分,否则给出 0 分。由图 7 可知,使用本文的预测函数效果优于 MSE。本文提出的损失预测模块预测的回归损失在不同任务中的准确度分别约为 90%、70%、75%。
![]()
图8:损失预测模块的损失预测准确率
本文提出了一种新的主动学习方法,适用于当前各类深度学习网络。本文通过三个主要的视觉识别任务和流行的网络结构验证了方法的有效性。虽然实验结果证明了该方法有效,但在该方法在抽样策略中并没有考虑数据的多样性或密度等特征。此外,在目标检测和姿态估计等复杂任务中,损失预测准确度相对较低(如图 8 分析),这些都将是后期的研究重点。
2、Variational Adversarial Active Learning (ICCV 2019,oral)
![]()
原文地址:https://arxiv.org/pdf/1904.00370
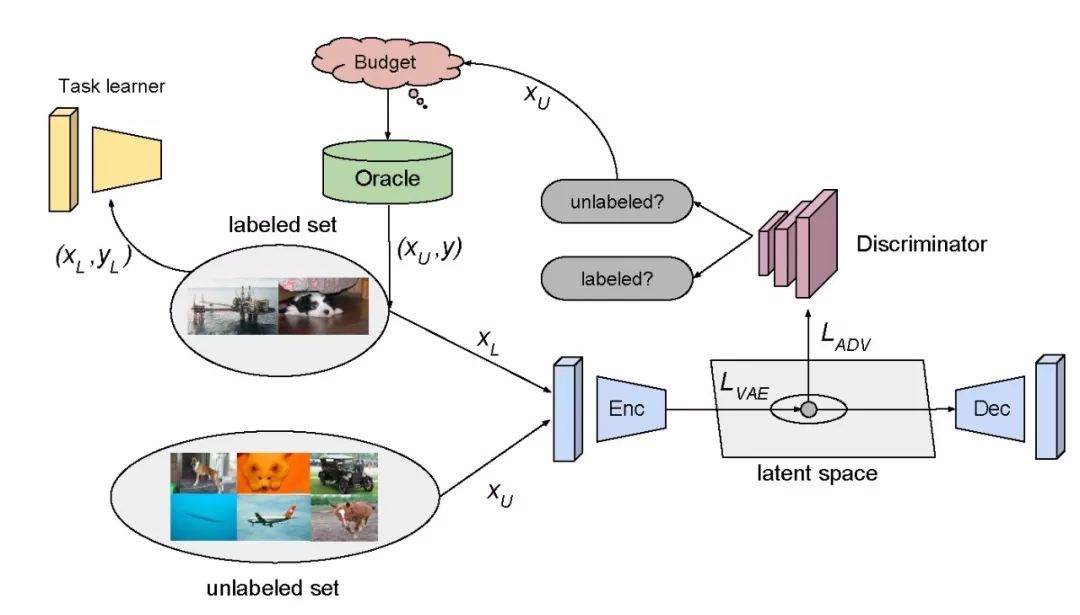
本文提出了一种使用变分自动编码器(VAE)和对抗网络来学习已标注数据在潜在空间中分布情况的主动学习模型(Variational adversarial active learning,VAAL)。在 VAE 和对抗网络之间进行的极大极小博弈过程中,训练 VAE 欺骗对抗网络将所有数据都预测为已标注数据;训练对抗网络区分潜在空间中不同类型数据的分布情况,从而区分已标注数据和未标注数据。VAAL 的整体结构见图 1。
![]()
图1:该模型使用VAE算法学习了标记数据在潜在空间中的分布,该算法采用了重建和对抗损失两种优化方法
首先,本文使用 VAE 学习潜在空间中已标注数据和未标注数据的表示,其中编码器使用高斯先验函数学习底层分布的低维空间,解码器重建数据。VAE 的目标函数为最小化给定样本边际似然概率的变分下界:
![]()
其中 p 和 q 分别表示编码器和解码器,p(z) 为高斯先验知识。由 VAE 学习的潜在空间表示是已标注数据和未标注数据相关的潜在特征的混合。
第二步,本文的抽样策略为训练一个对抗性网络,以学习如何区分隐藏空间中不同类别数据的编码特征。训练对抗网络,将潜在表示映射为二进制标签:如果样本数据为已标注,则为 1,否则为 0。
在上一步处理中,VAE 将已标注和未标注的数据映射到具有相似概率分布的同一潜在空间,它愚弄鉴别器将所有输入均定义为已标注的数据。另一方面,鉴别器则试图有效地估计该数据属于未标注数据的概率。关于 VAE 的对抗角色目标函数表述为:
![]()
其中 L_bce 为简单的二元交叉熵成本函数。由上面的分析,VAAL 中 VAE 的完整目标函数如下:
![]()
由于参与数据标注的人员专业性水平不同,专家标注(Oracle)的结果并不完全可靠。本文假设存在两种类型的 Oracle:一种是理想的 Oracle,它总是能够提供正确的标签;另一种是有噪声的 Oracle,它非自愿地为某些特定的类提供错误的标签。为了更加真实地评估有噪声 Oracle 情况下 VAAL 的效果,本文添加目标噪声,使用与鉴别器预测相关的概率作为一个打分项,收集每批样本中置信度最低的 B 个样本发送给 Oracle。
实验结果
本文实验条件为:初始训练集中已标注和未标注数据的比例为 10%、90%。从未标注数据集中选择需要由 Oracle 标注的样本,标注完毕后将这些数据添加到初始训练集中,并在新的训练集中重复训练。
实验通过准确度和平均 IoU 来评估 VAAL 在图像分类和分割中的性能,当有 Oracle 提供的标签可用时,分别以训练集的 10%、15%、20%、25%、30%、35%、40% 的比例进行训练。除 ImageNet 外,最终结果均为 5 次实验结果的平均值。ImageNet 中的结果则为使用 10%、15%、20%、25%、30% 的训练数据 2 次实验结果的平均值。
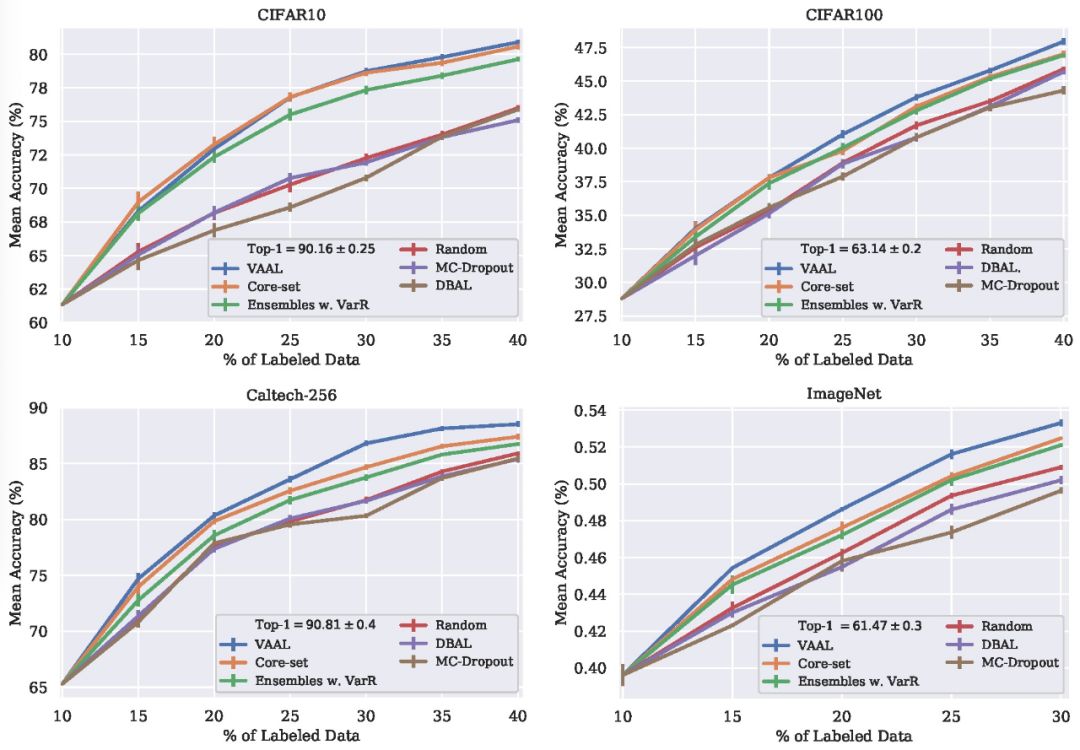
![]()
在 CIFAR-10 上,VAAL 使用 40% 的样本数据达到了 80.9% 的平均准确度,而使用整个样本数据集得到的准确度为 90.16%。在 CIFAR-100 上,VAAL 与 Ensembles w. VarR 和 Core-set 都获得较好效果,并且优于所有其他基线。在拥有类别真实图像的 Caltech-256 上,VAAL 始终优于其它算法,超过 Core-set 1.01%。在大规模数据集 ImageNet 中的实验结果证明了 VAAL 的可扩展性。由图 2 实验可知,VAAL 在图像分类实验中准确度最高,在获得同样准确度的情况下 VAAL 所需的样本数量最少。
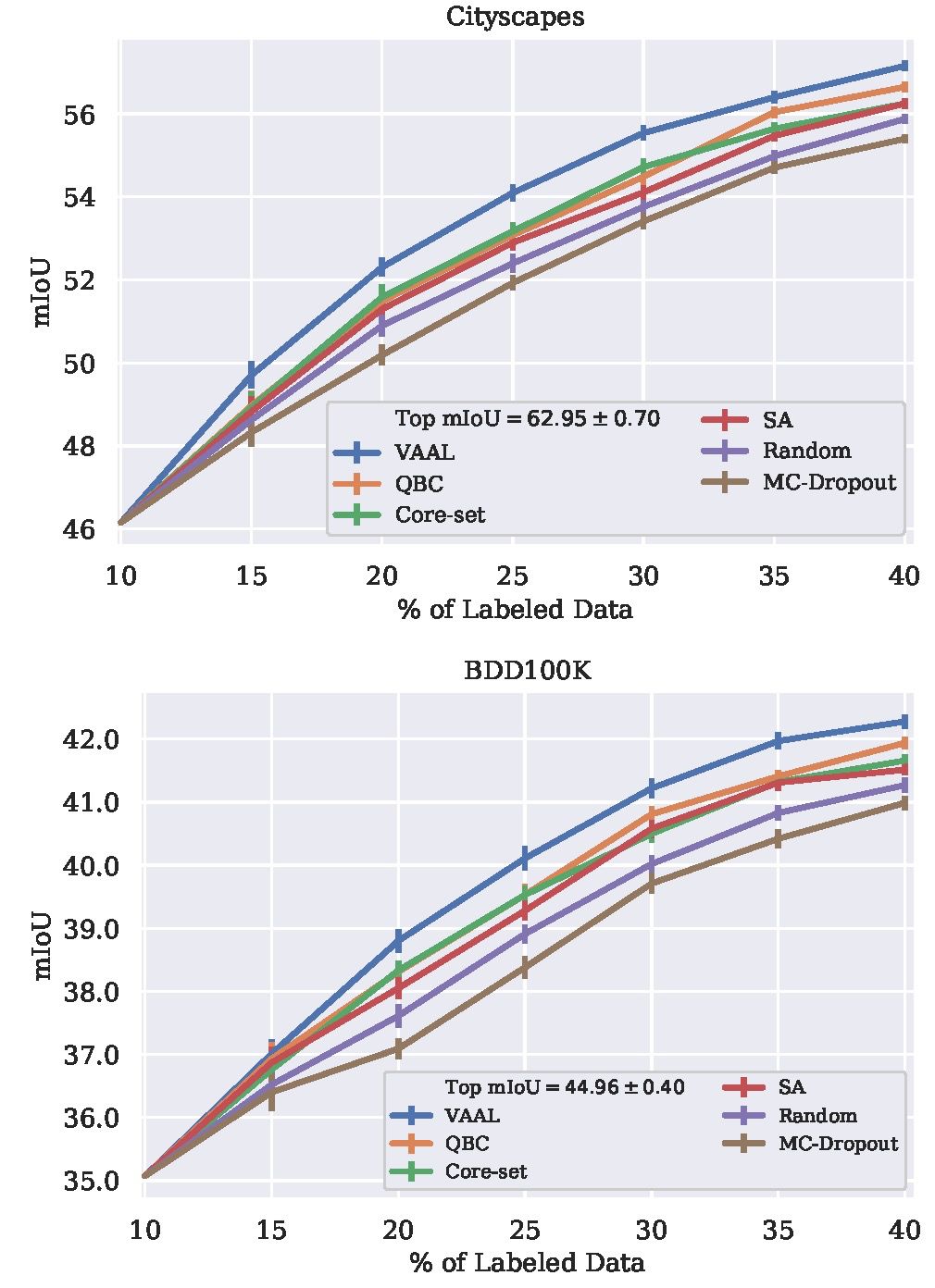
![]()
图3:与QBC、Core-set、MC-Dropout和Random Sampling相比,使用Cityscapes和BDD100K的VAAL在分割任务上的性能更好
在已标注数据比率不同的情况下,VAAL 在 Cityscapes 和 BDD100K 两个数据库中都能获得最高的平均 IoU。VAAL 仅使用 40% 的标注数据就可以实现 57.2 和 42.3 的%mIoU。当使用 100% 标注数据的情况下,VAAL 在 Cityscapes 和 BDD100K 两个数据库中可以达到 62.95 和 44.95 的%mIoU。
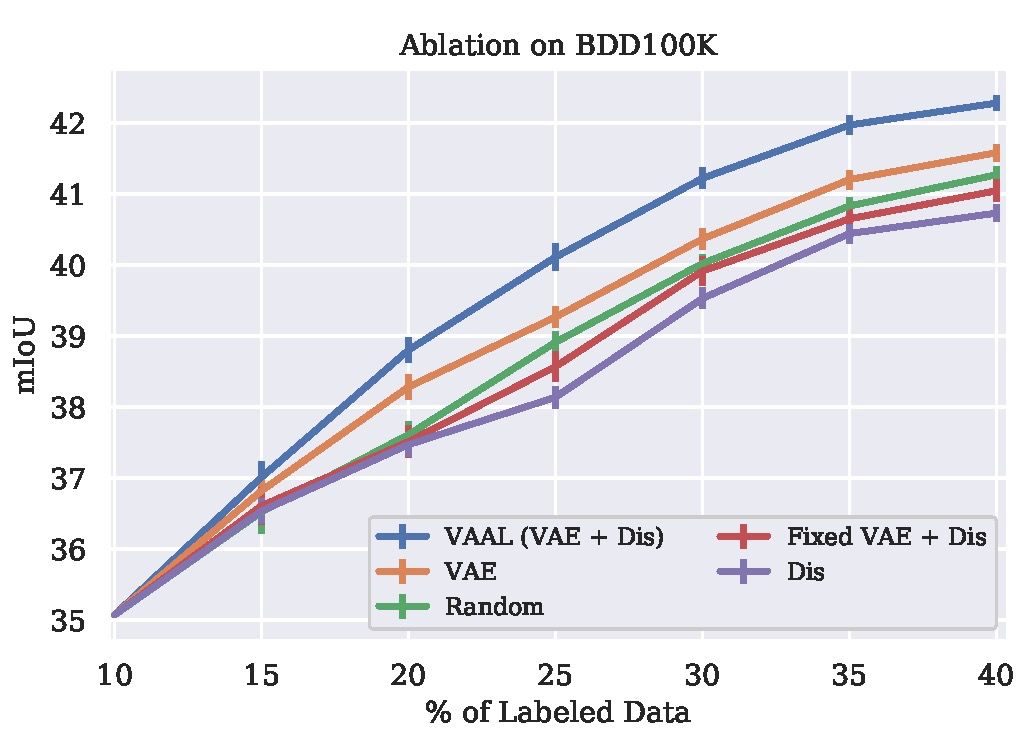
进一步,本文在 BDD100K 库中进行实验,以验证本文方法中所采用的 VAE 和鉴别器的有效性。实验考虑三种情况:1)取消 VAE;2)给定一个鉴别器,固定 VAE;3)取消鉴别器。实验结果见图 4。
![]()
实验结果表明,由于鉴别器只用于存储数据,仅采用鉴别器的模型处理效果最差。VAE 除了能够学习潜在空间,还能够利用鉴别器进行最小-最大博弈,从而避免过度拟合。而 VAAL 能够有效学习 VAE 和鉴别器之间对抗性博弈的不确定性,实验效果最优。
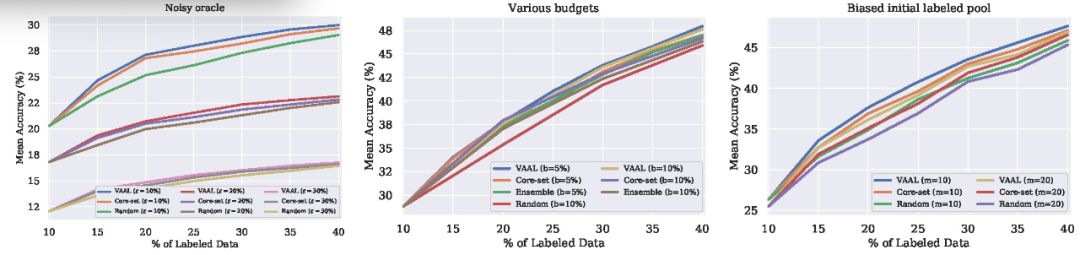
最后,本文给出了 CIFAR100 库中初始标注偏移情况(bias)、预期规模(budget)、噪声 oralce 对 VAAL 的影响,实验结果见图 5,实验证明了 VAAL 对不同参数的鲁棒性。
![]()
图5:使用CIFAR100分析VAAL对噪声标签、预算大小和有偏初始标签池的鲁棒性。
VAAL 的关键是以一种对抗性的方式同时学习 VAE 和对抗性网络,从而找到最有价值的抽样策略(准则)。本文基于各种图像分类和语义分割基准数据集对 VAAL 进行了广泛评估,VAAL 在 CIFAR10/100、CALTECH-256、IMAGENET、CITYSCAPE 和 BDD100K 上均获得了较好的效果。实验结果表明,本文的对抗性方法在大规模数据集中能够学习有效的低维潜在空间,并提供计算有效的抽样策略。
3、Bayesian Generative Active Deep Learning(ICML 2019)
![]()
原文地址:
https://arxiv.org/pdf/1904.11643.pdf
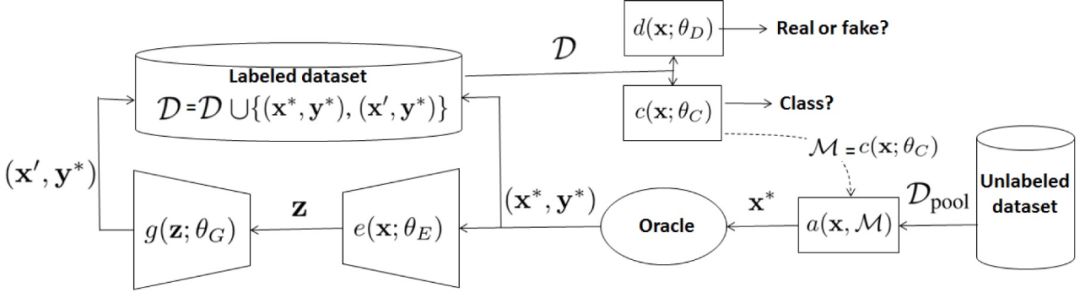
本文提出了一种新的贝叶斯生成式主动深度学习模型,该模型的目标是用生成的样本扩充已标注数据集,而这些生成样本对训练过程具有一定的参考价值。本文使用贝叶斯不一致主动学习(Bayesian active learning by disagreement,BALD)从未标注数据集中抽样,样本进行专家标注后使用对抗性模型 VAE-ACGAN((variational autoencoder,VAE)-(auxiliary-classifier generative adversarial networks,ACGAN))处理,生成与输入样本具有相似信息的新人工样本。将新样本添加到已标注数据集中,供模型迭代训练使用。
本文的研究主要受到最近提出的一种生成性对抗性主动学习方法(Generative adversarial active learning,GAAL)(Zhu and Bento, 2017 (https://arxiv.org/abs/1702.07956v5)) 启发,不同于传统的根据抽样策略选择信息量最大样本的主动学习方法,GAAL 依靠一个优化问题生成新样本(这种优化平衡了样本信息性和图像生成质量)。本文提出的贝叶斯生成式主动深度学习模型利用传统的基于池的主动学习方法选择样本,之后利用生成性对抗模型生成样本。传统的基于池方法、GAAL 和本文模型的对比图示见图 1。
![]()
与 GAAL 不同,本文方法首先利用基于池的方法(BALD)选择出信息量最大的样本,具体公式为:
![]()
其中 a(x ;M) 为抽样策略函数,使用香农熵表征预测值和分布情况。样本 x 被标记为 y 后进入样本库用于后续训练。具体抽样函数使用 Monte Carlo (MC) dropout 方法:
![]()
f 表示在 t 次迭代时从后验估计中取样的网络函数。
在建立生成模型主动生成样本数据的过程中,本文没有像 GAAL 一样直接应用 GAN,而是借鉴了数据增加(data augmentation)的理念,采用了贝叶斯数据增加(Bayesian Data Augmentation,BDA)模型。BDA 模型包括一个生成器(用于从潜在空间中生成新的训练样本)、鉴别器(区分真实和虚假样本)和分类器(确定样本类别)。首先,给定一个潜在变量 u 和类别标签 y,用函数 g 表示生成函数,将 (u,y) 映射为点 x=g(u,y),之后已标注的数据 x 以(x,y)格式加入到训练集中。本文对 BDA 进行改进,在样本生成阶段不使用潜在变量 u 和类别标签 y,而是使用样本 x 和类别标签 y,即样本 x 直接推送到 VAE 中:
![]()
VAE 的训练过程通过最小化重建损失实现。此外,本文证明了从信息量最大的样本中生成的样本同样具有信息量。
本文的主要贡献是通过结合 BALD 和 BDA,有效生成对训练过程有参考意义的新的标记样本。本文模型的结构见图 2。
![]()
由图 2 可知,本文提出的模型由四部分组成:分类器、编码器、解码器/生成器、鉴别器。其中分类器可使用主流的各种深度卷积神经网络分类器,这使得该模型具有很好的灵活性,可以有效利用各种优秀分类器。生成器部分本文使用的是 ACGAN 和 VAE-GAN。将 VAE 的重建误差引入 GAN 的损失函数中构成 VAE-ACGAN 的损失函数,实现对 GAN 训练过程中的不现实性和模式崩溃进行惩罚。VAE-ACGAN 的损失函数为:
![]()
其中 VAE 损失表示为重建损失 Lrec 和正则化先验 Lprior 的组合:
![]()
![]()
本文根据 Top-1 精度测量的分类性能评估贝叶斯生成式主动深层学习模型的效果。
实验对比的方法包括:贝叶斯生成式主动深层学习模型(AL w. VAEACGAN)、使用 BDA 的主动学习模型(AL w. ACGAN)、未使用数据增加处理的 BALD(AL without DA)、未使用主动学习方法的 BDA(BDA)以及随机生成样本的方法。
实验数据库:MNIST、CIFAR-10、CIFAR-100、SVHN。
实验中使用的分类器:ResNet18、ResNet18pa。
![]()
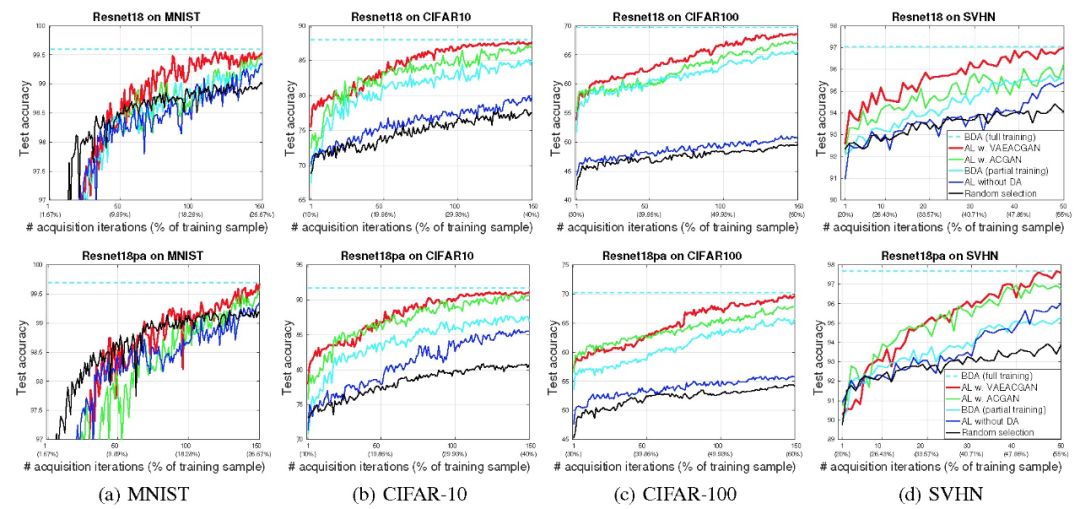
图 3 给出了在采集初始训练集迭代次数、样本百分比不同的情况下各个模型的实验结果。图 3 中曲线的每个点表示一次采集迭代的结果,其中每个新点表示训练集的增长百分比。使用完整训练集和 10 倍数据扩充建模的 BDA 的实验结果作为所有其他方法的上限(BDA(full training))。本文提出的模型(AL w. VAEACGAN)效果优于使用 BDA 的主动学习模型(AL w. ACGAN)。这说明尽管 AL w. ACGAN 使用样本信息训练,但生成的样本可能不具有信息性,因此是无效样本。尽管如此,AL w. ACGAN 生成的样本分类性能仍然优于未使用数据增加处理的主动学习方法(AL without DA)。
此外,图 3 的实验还表明,本文提出的模型在仅依赖部分训练集数据的情况下,能够获得与依赖 10 倍训练集大小数据量的数据增强方法相当的分类性能。这表明,本文模型仅需要消耗较少的人力和计算资源来标记数据集和训练模型。
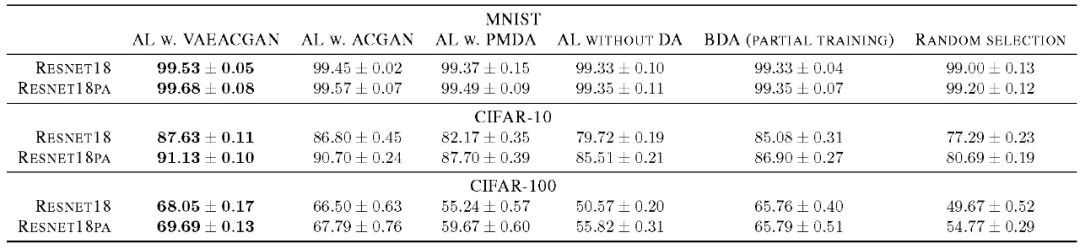
进一步,本文在不同随机初始化的情况下完成三次实验,给出最终的分类结果见表 1。表 1 的数据表明,本文提出的模型效果优于其他方法。
![]()
表1:经过3次运行,迭代150次后在MNIST、CIFAR-10和CIFAR-100上分类准确率的平均标准差
图 4 给出在不同数据库中使用本文提出的模型生成的图像。本文模型的主要目标是改进训练过程以获得更好的分类效果,然而由图 4 结果可知,模型的生成数据具有非常高的图像质量。
![]()
图4:
本文提出的AL w. VAE-ACGAN方法生成的各类图像。
本文是受 (Zhu and Bento, 2017 ) 启发提出的查询合成类(生成样本)主动学习模型,由于 (Zhu and Bento, 2017 ) 文章中仅探讨了二进制分类问题,本文未与其进行实验对比。本文提出的方法是模型不可知的(model-agnostic),因此它可以与目前提出的几种主动学习方法相结合。现有模型的样本生成方式是:以从未标注数据集中选择出的具有较高信息量的样本为基础来生成样本,后续研究将着重考虑如何使用复杂的采集函数直接从未标注数据集中生成样本,而不再需要样本选择的步骤。此外,模型的计算性能还需进一步提升。
作者介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com