加速机器学习:从主动学习到BERT和流体标注
作者:知道创宇IA-Lab 岳永鹏
专栏地址:http://www.52nlp.cn/author/befeng

机器学习模型代码优化是为了获得更高效(时间更少、存储更少、计算规模更大)执行的机器指令和具有更强泛化能力的模型,获得更高效执行的机器指令可以采用多核和高频的CPU计算,以及采用并行计算和向量化计算。而获得具有更强泛化能力的模型不仅仅与选择的模型有关,还与标注数据的数量和质量有关。而数据标注需要大量标注人员从事重复而枯燥的工作,这也必然会增加成本。
本文将介绍主动学习(Active Learning)以及主动学习结合Google今年发布的流体标注(Fluid Annotation)和BERT(Bidirectional Encoder Representation from Transformers)对加速机器学习有什么启示。
标签数据
按是否需要“标签”数据(Labeled Data)可以将机器学习分为监督学习(supervised Learning)、无监督学习(unsupervised Learning)以及半监督学习(Semi-Supervised Learning)三类。其中监督的机器学习是完全依赖于标签数据,无监督学习则不需要标签数据,半监督学习仅部分需要标签数据。而获得正确的标签数据,往往需要付出昂贵的代价,无监督学习和半监督学习虽然不需要付出获得标签的代价,但是对实际的问题,用监督学习的还是主流,特别是当下大红大紫的深度学习(Deep Learning)模型,在工业界都需要大量的标签数据,甚至有“有多少智能,就需要多少人工”的说法,这里的人工就是指聘请的一些训练有素的“专家”为成千上万的数据打标签。倘若我们的专家不太好,我们训练的模型也不会很好。有时,专家几乎可以是任何人,例如MNIST手写数据集中手写字体仅高中生就能完成。而有时,专家必须是一些经验丰富的行家,比如自然语言处理中的词性、实体和关系的标注。获得这些行家的标签数据是非常非常昂贵,但是又是监督学习所必须的,而减小标注数据的代价又可以从两个方面考虑。
一方面可以采用主动学习,在保证模型精度的条件下,选择出具有代表性的点进行标注,尽量的做到少标记数据。例如对如下图所示两个簇(绿色和红色)的线性分类模型,想创建一个线性的“决策边界” 将绿色和红色的形状分开。而在一开始我们并不知道数据点的标签(红色或绿色),红色或绿色标签是通过采样而得到的一小部分雇佣专家标注而得到的。

在请专家标记数据的时候会面临如下的问题:采用什么样的采样策略而得到行之有效的小部分待标注数据。比如在中图,线性分类器在一小部分随机采样数据上得到的决策边界是次优的,因为这条线明显偏离红色数据点并进入绿色形状区域,这是因为标记数据点选择不当造成的。在最右边图中,使用另外一种采样策略方法选择的一小部分数据点具有更好的决策边界,因为它更好地分离了两种颜色。
另一方面可以借鉴Google今年发布BERT的Fluid Annotation的思想,首先通过大规模语料进行自然语言的模型预训练,然后在预训练好的模型上进行后续任务训练,并且其可以作为主动学习过程中训练模型的fine-tuning过程,提高模型的预测精度,让单纯的人工语料标转变为模型先预测,人工审核和确认的过程,从而加快标注人员的标注效率,生产出更多的标注语料,加速机器学习。


主动学习
通过上文的描述已经对主动学习有了初步的认识:主动学习是一种可以减少监督学习所需标签数据量的方法,用更少的标注数据训练出更好的模型。通俗的理解就是在提高模型精度的同时,让毫无技术含量的体力标注“专家”或需要具有丰富行业知识的行家少干一些标注数据的活儿,从而减少减小待标注数据的总量。
为了更好的理解主动学习的流程,首先先回顾一下监督学习流程。监督学习分为训练(train)和预测(Prediction)两个阶段,在训练阶段通过标签数据集来确认模型的参数,得到一个模型。在预测阶段将无标签的数据输入到已经训练好的模型,得到一个预测的标签。
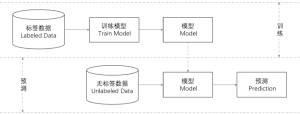
在模型的训练阶段利用这种大型数据集来训练模型的方式也称为被动学习(Passive Learning),一般来讲被动学习所需的训练数据集越多越好,但往往“理想是美好的,现实是残酷的”,越多越好的标签数据是是很难获得的。此时将标注数据的流程和模型训练的流程进行结合,边标注边训练就构成了主动学习。
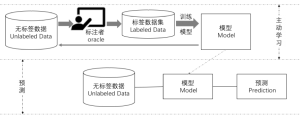
更详细的,主动学习的流程可以分为初始化和循环查询两个阶段。在初始化阶段,先随机的从无标签数据集中选取一小部分样本由标注者完成标注,并将这一小部分标注样本作为初始训练集,建立初始的机器学习模型。

在循环查询阶段,按照某种查询策略从无标签数据集中选择样本数据进行标注,并将已标注的数据加入到标注数据集中,重新训练机器学习的模型,直到达到训练停止的标准才停止循环。
主动学习的两个阶段中,其关键是如何从无标签数据集中选择出样本进行标记以及如加快重新训练机器学习模型的精度,对如何从标签数据集中选择更好的样本可以用选择策略(Select Query)的确定,常用的选择策略方法有:
不确定性采样。
委员会投票选择算法(Query-By-Committee, QBC)。
期望模型变化最大化。
方差变化最大化。
基于密度权重的方法。
而对于如何加速重新训练机器学习模型的精度,则可以引入BERT。
BERT
主动学习的循环阶段有重新训练机器学习模型的步骤,重新训练模型一种方式是用全部语料重新训练模型参数,另一种方式是在已有的模型参数的基础上做模型参数的fine-tuning。对自然语言处理Google最近发布的BERT(Bidirectional Encoder Representation from Transformers)新模型就在在11项NLP任务中获得了不错的结果。Google的BERT是在33亿文本的语料上训练语言模型,再分别在不同的下游任务(实体识别、意图理解等等)上微调,这样的模型在不同的任务均得到了目前为止最好的结果,并且有一些结果相比此前的最佳成绩得到了幅度不小的提升。
流体标注
对图像分类标注的模型预训练可以采用语义分割模型(Mask R-CNN)预先生成约1000个图像片段及其分类标签和置信度分数,即Google 的流体标注(Fluid Annotation)。置信度分数最高的片段用于对标签的初始化,呈现给标注者。然后,标注者可以:
1)从机器生成的候选标签中为当前片段选择标签。
2)对机器未覆盖到的对象通过鼠标左键添加分割段。机器会识别出最可能的预生成段,标注者可以从中选择质量最高的一个。
3)通过鼠标右键删除现有段,从而实现机器预生成片段的修改。
4)通过滚动鼠标来改变重叠段的深度顺序。
Google Fluid Annotation Demo
总结
从工程的角度出发,可以结合主动学习和BERT和流式标注的思想,在自然语言处理任务的标注中,借助BERT实现主动学习循环阶段重新训练模型模型精度的提高,借助流式标注的思想,可以让纯手工的标注变为对模型最终预测结果的确认和修改,从而实现加速NLP机器学习的效果。
知道创宇招聘NLP(智能问答)实习生
岗位描述:
1、负责 NLP/NLU 自然语言处理相关核心技术研发;
2、探索基于深度学习技术的自然语言处理,并应用于垂直领域的语义解析和开放领域的问答与对话系统。
岗位要求:
1. 计算机/信息/数学类专业硕士或博士在读,能熟练的阅读英文文献;
2. 精通Python, Java, 或C++其中一种或多种语言,熟悉Linux平台;
3. 有机器学习/机器学习/自然语言处理/智能问答相关研发经验者优先;
4. 有ACM获奖经验者或有TensorFlow、PyTorch实战经验者优先;
5. 善于思考、分析问题,有较强的沟通能力和自我驱动力。
联系邮箱:zhus at knownsec.com




