论文解析 | 罪行预测

| 作者:黑龙江大学nlp实验室研究生刘宗林
导读
背景知识
近些年来,Legal Jugement Prediction 任务越来越引起大家的关注,这个任务的目的是通过给定的事实描述,预测出罪名,法条以及刑期等相关信息,charge prediction 任务就是这样的一个任务,这对一些法律助手是很有帮助的,对法官判决也有很大的帮助,不仅如此,对那些法律知识知之甚少的人也会有一定的积极作用。
目前,这类任务的主流做法是基于文本分类的框架,像流行的SVM,CNN,LSTM等这些深度学习框架,然而,作者认为,仅仅通过给定的事实描述来做,不能够很好的解决问题,他认为,法条信息在这个任务上有很重要的作用,所以,作者通过加入法条特征,使用attention机制,提出了这个任务新的方法,通过他的实验结果也确实表明法条起着至关重要的作用。
数据处理
数据来源于中国裁判文书网,收集了50000个文本用作训练,5000个文本用于开发,5000个文本用于测试,50000个训练文本中,把罪名的频度低于80的看做消极数据,不作处理,仅仅处理频度高于80的数据。
对于法条部分,考虑刑事法律,结果数据集中包含50个不同的罪名,321条不同的相关法条,每个事实描述平均383个词,根据下图,高亮的部分,能够很容易通过正则表达式抽取相关特征。

由于目前很难匹配多个罪名,所以这篇论文仅仅考虑了一个罪名的情况,并没有做多个罪名的情况。
论文模型
模型整体架构
论文的整体的模型图如下图Figure 1:
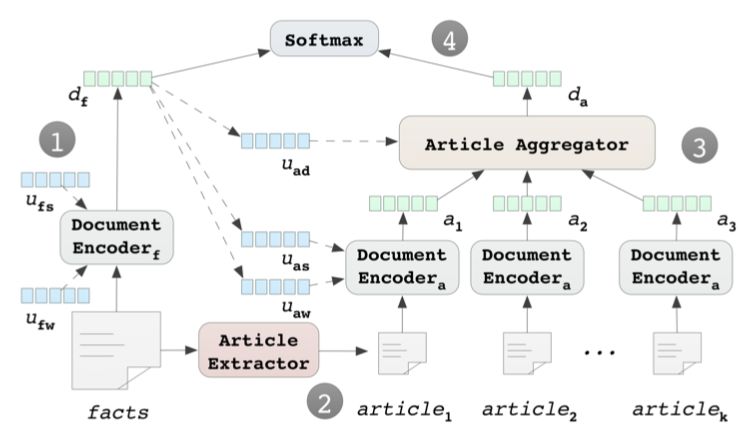
过程:
事实描述(fact)通过document encoder生成fact向量表示d_f。
fact也通过Article Extractor抽取其中的匹配度较高的k个法条。
抽取出来的k个法条通过document encoder生成向量表示s。然后通过article Aggregator生成法条的最终向量表示d_a。
把 d_f 和 d_a concat在一起,做分类。
Document Encoder
一个句子由多个词组成,一个文本由多个句子组成,可以先过句子级别的encoder,再过文本级别的encoder。如下图可以得到文本的embedding。论文中对这两个encoder都采用了Bi-GRU作为编码端,为了能够获取到更多的信息,论文还采用了attention机制。
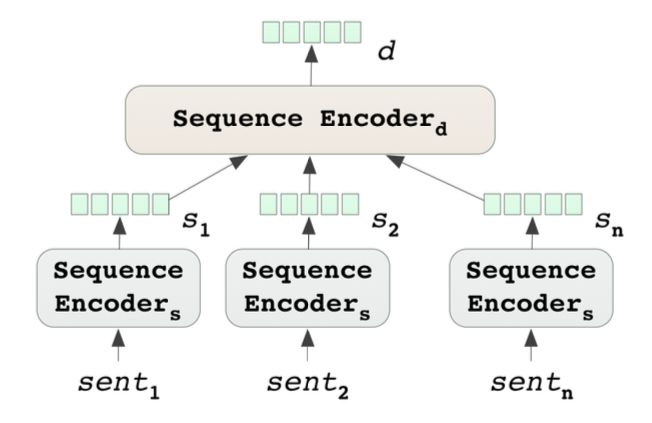
Attention Sequence Encoder
为了能够获取更多的有用信息,采用了Hierarchical Attention(16年的一篇文本分类的论文),模型结构图如下图
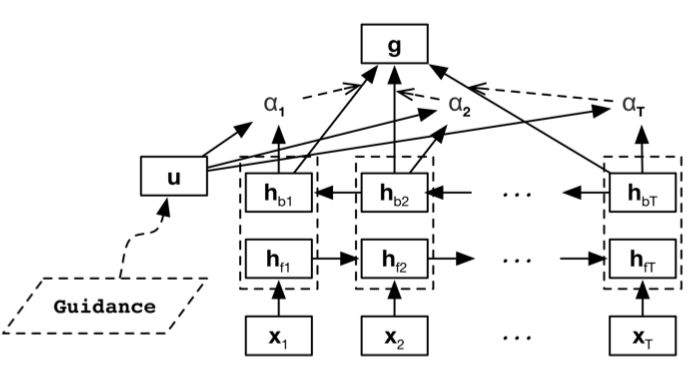
计算的公式是:
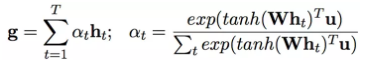
这样就能够明白Figure 1 中的 U_fw 和 U_fs是这里Attention机制的u。
Law Articles
用法条特征来更准确的预测是这篇论文的重点。如何准确的抽取出法条特征也是一个难点,论文中采用了两个步骤来获取特征向量。
首先采用一个快速且容易的SVM分类器,做多个二分类,过滤掉大部分不匹配的法条,得到k的最为匹配的相关法条,分类器还加入了TF-IDF特征、chi-square,更为准确的获取相关法条。
抽取出k个相关法条之后,再通过Article Encoder(和Document Encoder一样)获取法条的向量表示,这里不同的是attention中的u不在是随机的,而是通过fact embedding动态产生的,通过下面的公式。
最后在通过Attentive Sequence Encoder从k个法条中获取到支持预测的法条,这里的u也是通过fact embedding动态产生的。
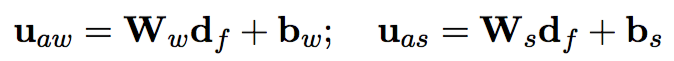
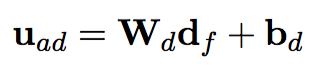
Output
最终的把fact embedding(d_f) 和 article embedding(d_a) concat 在一起,做最后的预测,这里还设置了一个threshold。
Supervised Article Attention
在训练的过程中,利用金标的法条监督法条attention的分布,就是想要法条attention的分布于目标法条的分布相似, loss的计算公式如下:
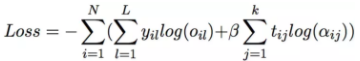
实验部分
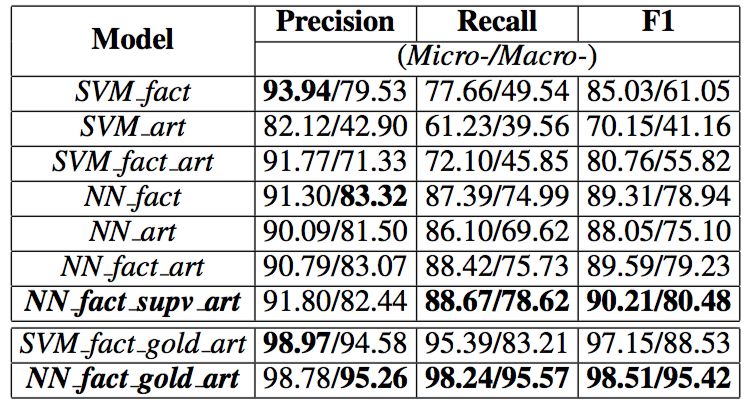
实验的参数设置没有什么特别的,实验部分,论文做了很多的对比实验,从结果来看(下图)法条特征对预测确实起着很大的作用。
总结
法条特征对这个任务确实起着很重要的作用,虽然论文仅仅做了单一罪名的预测,没有尝试多罪名预测中法条特征的影响,但是论文的思路已经给我们提供了新的方向。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流





