谷歌 AI:语义文本相似度研究进展

本文为雷锋字幕组编译的技术博客,原标题 Advances in Semantic Textual Similarity,作者为 Google AI 的软件工程师与技术主管 Yinfei Yang。
翻译 | 张韵晨 马力群 整理 | 凡江
插播一则小广告:NLP领域的C位课程,斯坦福CS224n正在AI慕课学院持续更新中,无限次免费观看!链接:
https://gair.leiphone.com/gair/2018yr
最近基于神经网络的自然语言理解的研究的迅速发展,尤其是关于学习文本语义表示的研究,使一些十分新奇的产品得到了实现,比如智能写作与可对话书籍。这些研究还可以提高许多只有有限的训练数据的自然语言处理任务的效果,比如只利用 100 个标注的数据搭建一个可靠的文本分类器。
接下来,我们将讨论两篇最近由谷歌发表的关于语义表示研究的论文,这两个新的模型可以从 TensorFlow Hub (https://www.tensorflow.org/hub/)上下载,我们期待开发者可以利用他们搭建新的令人激动的应用程序。
语义文本相似度
在 Learning Semantic Textual Similarity from Conversations (https://arxiv.org/abs/1804.07754)这篇论文中,我们提出了一个新的方法来学习用来计算语义文本相似度的句子表示方法。从直觉上来说,如果两个句子有相近的关于回复信息的分布,那么它们的语义是相近的。例如,「你多大了?」与「你的年龄是多少?」都是关于年龄的问题,都有相近的回答,比如「我 20 岁了」。与此相反,「你最近怎么样?」(How are you?)与「你的多大了?」(How old are you?)包含了几乎相同的单词,但它们有不同的含义以及会引导出不同的回答。
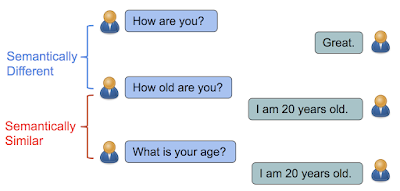
如果多个句子有相同的回答,那么他们在语义上是相近的。否则,他们在语义上是不同的。
在这一工作中,我们的目标是通过一个回答分类任务来学习语义相似度: 给定一轮对话作为输入,我们希望从一批随机选择的回答中挑选出正确的回答。但是,我们最终的目标是学习一个可以返回表示各种自然语言间关系的编码的模型,这些自然语言间的关系包括相似度与关联性。通过加入另一个预测任务(在这一任务中,采用 SNLI entailment 数据集)与利用共享的编码层增强两者,我们在相似度衡量任务上得到了十分不错的表现,比如 STSBenchmark(一个句子相似度衡量的基准)与 CQA task B(一个问题与问题间相似度衡量的任务)。这是因为逻辑上的蕴含与简单的等价关系完全不同,而且逻辑上的蕴含提供了更多用来学习复杂的语义表示的信息。

对于给定的输入,分类被认为是一个针对潜在选择的排名问题。
通用的句子编码器
在 Universal Sentence Encoder (https://arxiv.org/abs/1803.11175)这篇论文中,我们提出了一个模型,这个模型通过添加更多的任务来扩展上述的多任务训练,采用类似于 skip 思想的预测给定的文本选项周围的句子的模型共同训练这些任务。然而,我们采用了一个只有编码器的结构来代替原来的 skip 思想中编码器-解码器的结构,我们的结构通过一个共享的编码器来驱动预测任务。采用这种方法,训练时间显著减少的同时仍保留了在各种迁移任务上的表现,包括情感与语义相似度分类。模型的目标是提供一个单独的编码器,它可以尽可能广泛地支持各种应用,包括改写检测、关联性、聚类以及自定义文本分类。
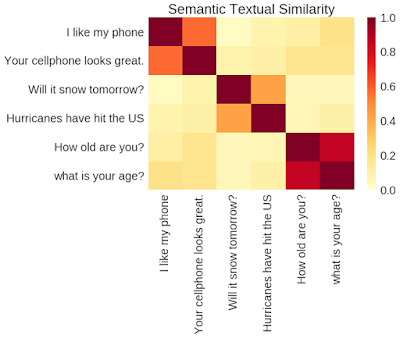
通过 TensorFlow Hub 上的通用句子编码器的输出进行句对语义相似度比较。
正如我们在这篇论文中所表述的,一个版本的通用句子编码器模型使用了深度均值网络( DAN )编码器。而第二个版本则使用了一个更为复杂的自主网络结构——转换器。
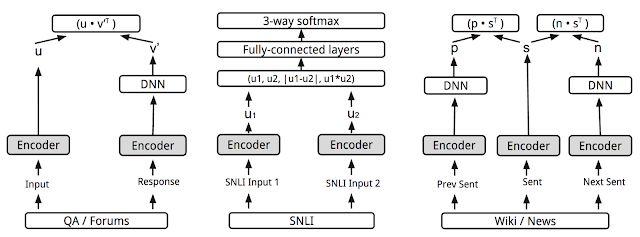
正如《通用句子编码器》论文中所表述的多任务训练,各种任务以及任务结构通过共享编码器层/参数而结合(如上图中灰色框)。
通过使用更加复杂的结构,模型与结构更简单的深度均值网络模型相比在各种情感和相似度分类任务上表现更好,而在短句子的表现上仅仅是表现的稍微慢一些。然而,随着句子长度的增加,使用转换器模型的计算时间显著增加,而深度均值网络( DAN )编码器模型的计算时间几乎保持不变。
新模型
除了上述的通用句子编码器模型之外,我们还在 TensorFlow Hub 上共享了两个新模型:大型通用句子编码器以及精简版通用句子编码器。 这些是预训练的 Tensorflow 模型,可以返回可变长度文本输入的语义编码。 这些编码可用于语义相似性度量,相关性,分类或自然语言文本的聚类。
大型通用句子编码器使用我们第二篇论文中介绍的转换器编码器进行训练。 它针对需要高精度语义表示的场景以及以牺牲速度和大小为代价获取最佳性能的模型。
小模型使用句子片段而不是单词进行训练,这样大幅度降低了词汇的大小,这是模型大小的主要决定因素。它针对内存和CPU等资源有限的场景,例如基于手持设备或基于浏览器的实现。
我们很高兴与社区分享这项研究和这些模型。我们相信我们在这里展示的只是一个开始,况且还有重要的研究问题需要解决。例如将这一技术扩展到更多语言(上述模型目前支持英语)。我们也希望进一步开发这种技术,以便能够理解段落甚至文档级别的文本。在实现这些任务时,可能会制作出真正”通用”的编码器。
致谢
感谢Daniel Cer、Mario Guajardo-Cespedes、 Sheng-Yi Kong、Noah Constant 进行了模型训练,Nan Hua、Nicole Limtiaco、Rhomni St. John 进行了任务迁移, Steve Yuan、Yunhsuan Sung、Brian Strope、Ray Kurzweil 参加了模型结构的讨论。特别对 Sheng-Yi Kong 和 Noah Constant 训练小模型所做的工作进行感谢。
博客原址:
https://ai.googleblog.com/2018/05/advances-in-semantic-textual-similarity.html