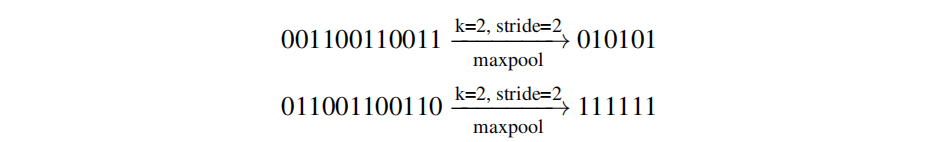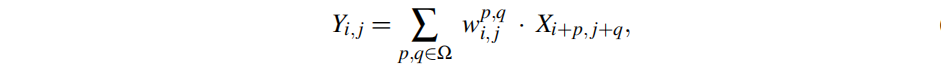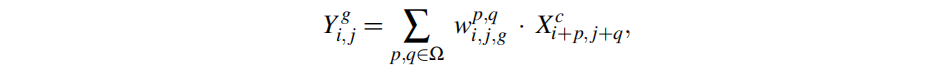点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:极市平台
Aliasing(锯齿)是采样过程中常见现象,本文为这一问题的解决提出了有效新思路:内容自适应低通滤波层,并提出一种用于评价语义/实例分割的平移一致性的新度量准则。作者在分类、分割等多种任务上验证了所提方法的有效性与泛化性。
paper:
https://arxiv.org/abs/2008.09604
code:
https://github.com/MaureenZOU/Adaptive-anti-Aliasing
导语:
该文是加州大学&NVIDIA提出了一种消除Aliasing的方案。该文在AntialiasedCNN的基础上进行了更一步的改进,将固定模糊核改进为内容自适应低通滤波操作。作者还通过不同的任务验证了所提方法的有效性与泛化性能。
Abstract
Aliasing(锯齿)是采样过程中常见现象之一,它将高频信息退化成了更复杂的表现形式。在深度学习领域中,它常见诸于下采样层中(比如Maxpooling、StrideConv)。一种标准方案是在下采样之前进行低通滤波(比如高斯模糊),然而这种处理方案是次优方案:因为不同位置、不同通道的频率信息是不相同的。
为解决上述问题,作者提出了一种
内容自适应低通滤波层,它针对输入特征预测不同位置、不同通道的滤波权值。作者
在多个任务(比如ImageNet分类、COCO实例分割、Cityscapes语义分割等)上验证了所提方案的有效性与泛化性能。定量与定性结果表明:
所提方法可以具有特征频率自适应特性,在避免锯齿的同时保持有用信息。
Introduction
Aliasing指的是下采样过程中高频信息的畸变问题,Nyquist采样理论表明:采样率必须至少是最高频的两倍方可避免Aliasing问题。下图给出了1D信号的下采样Aliasing效应,可以看到经过下采样后输入与输出具有不同的表现形式。
在深度学习领域,下采样层对于降低计算量非常关键,然而这种Aliasing问题会模型性能的严重下降(尤其当测试图像存在shift问题时)。为解决上述问题,有学者提出采用高斯模糊+下采样方案,见下图c。作者认为这种处理方案并非最优:不同位置、不同通道的特征频率信息存在较大差异。
为解决上述方法存在的问题,作者提出了一种内容自适应下采样方案,效果见上图d。它在不同位置、不同通道执行不同的高斯滤波,因此可以更好的保持有用信息并避免Aliasing问题。该文的贡献主要包含以下几点:
-
提出一种新颖的自适应低通滤波器层用于解决Aliasing问题;
-
提出一种新颖的度量准则用于评价语义/实例分割的平移一致性;
-
通过ImageNet分类、Cityscapes分割以及COCO分割等任务验证了所提方案的有效性;
-
Method
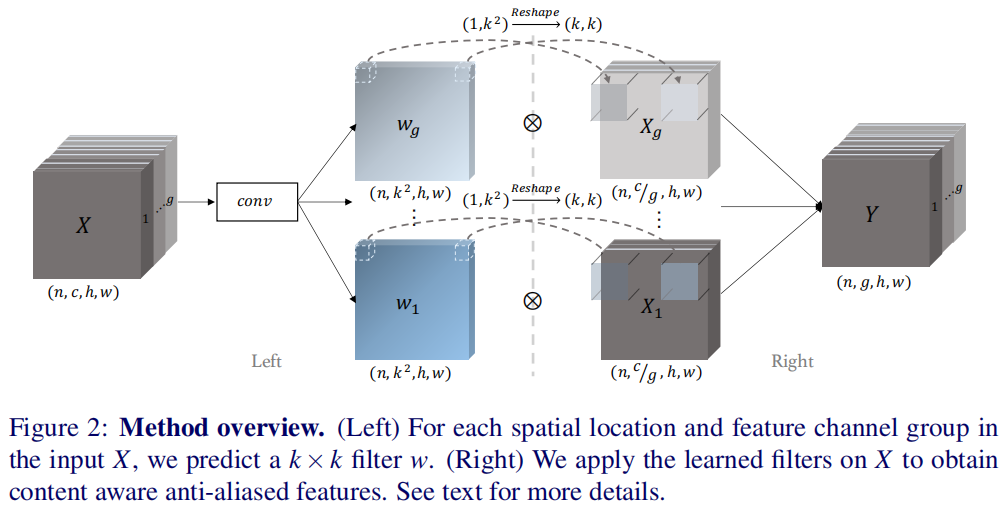
为解决ConvNet中的Aliasing问题,作者提出一种内容自适应低通滤波模块。它为特征的不同位置、不同通道生成低通滤波器参数并执行卷积操作用于消除Aliasing。下图给出了作者所设计的模块结构示意图,其实就是一种动态滤波器卷积。
Spatial adaptive anti-aliasing
由于图像不同位置的频率成分各不相同,作者提出了一种内容自适应方式学习低通滤波器。该过程可以描述为:给出输入特征X,首先生成低通滤波器
(注:不同位置具有不同的滤波器参数),然后将其作用于输入特征X:
其中
表示输出特征。通过这种方式,网路可以学习模糊更高频内容而非更低频内容,从而减少可能的Aliasing问题,同时保持重要的内容信息。
Channel-grouped adaptive anti-aliasing
不同通道特征会从不同角度捕获输入的特征信息,进而呈现出边缘、色彩等差异。因此,作者认为应该对不同通道采用不同的下采样滤波器。基于此,作者将输入通道划分为k组,对每一组预测一个低通滤波器
,然后作用于输入特征X
Learning to predict filters
为动态生成低通滤波器,作者采用Conv+BatchNorm方式生成滤波器参数
,其中g表示分组数,k表示生成动态滤波器的卷积核尺寸。为确保生成的滤波器是低通滤波器,作者约束了生成权值均为正并通过softmax进行归一化。
Analyzing the predicted filters
在该部分内容,我们将分析一下所学习到的滤波器的表现行为。首先,先来看一下滤波器的空间自适应性,见下图。可以看到:当图像内容包含高频信息时,所学习到的滤波器方差非常小,此时需要采用进行模糊以避免Aliasing;相反,当图像内容为平坦区域时,所学习到的滤波器的方差会比较大,此时需要进行更少的模糊以避免Aliasing。
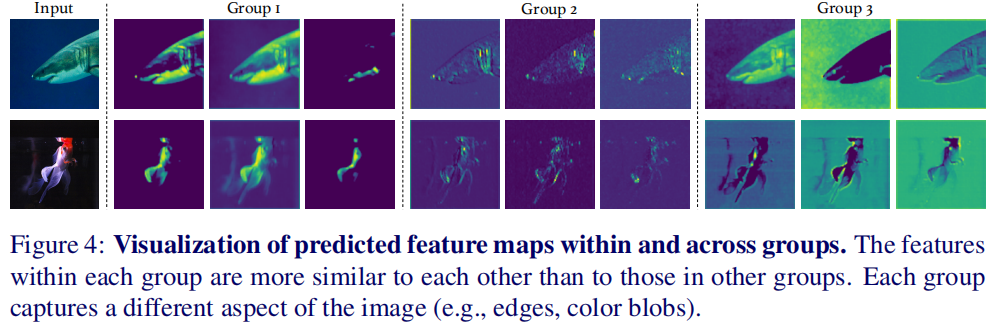
下图给出了不同组学习到的滤波器可视化效果图,同组内的通道特征具有相似的表现形式。通过这种方式,所学习到的滤波器可以针对特征通道的不同频率进行自适应学习,同时可以节省计算量。
Experiments
为验证所提方法的有效性与泛化性能,作者在ImageNet、COCO实例分割、Cityscapes语义分割等任务上进行了实验并与其他SOTA方法进行了对比。
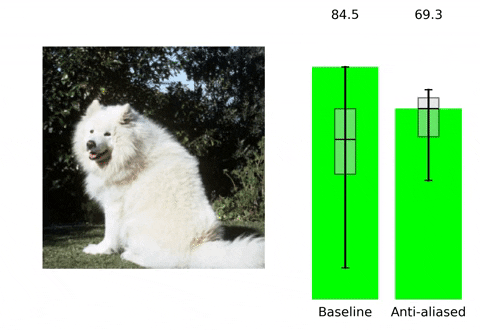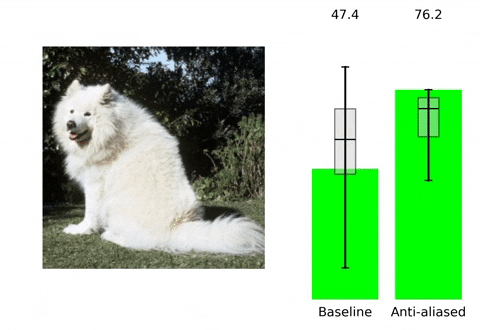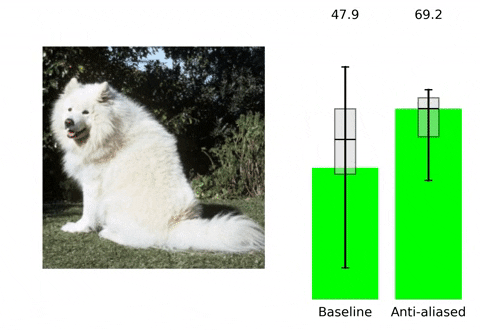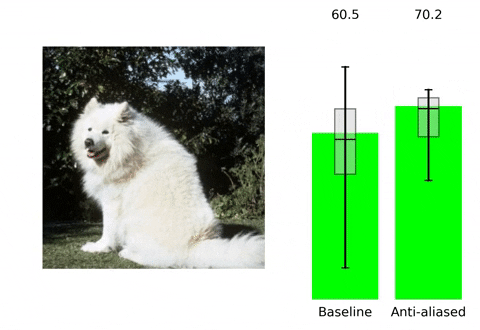
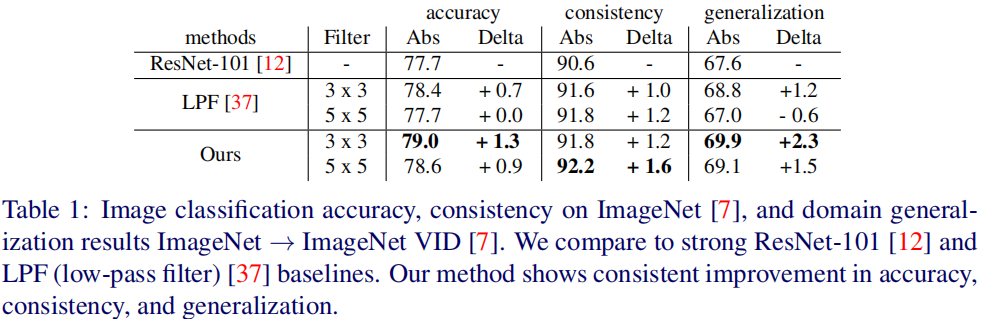
下表给出了所提方法与LPF(低通滤波器)方法的性能对比,可以看到:所提方法取得了更好的性能提升。相比固定模糊核方法,所提方法取得了0.6%的性能提升;所提方法不仅具有更好的指标,同时具有更好的一致性度量指标。
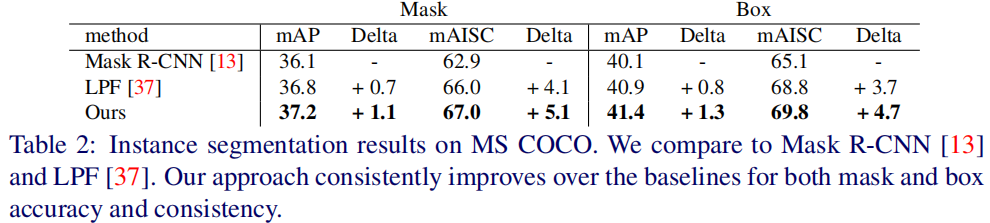
下表给出了所提方法在COCO实例分割任务上的性能对比。可以看到:所提方法取得了更好的性能提升。相比LPF,所提方法取得了0.4mAP的Mask指标提升,0.5mAP的Box指标提升。
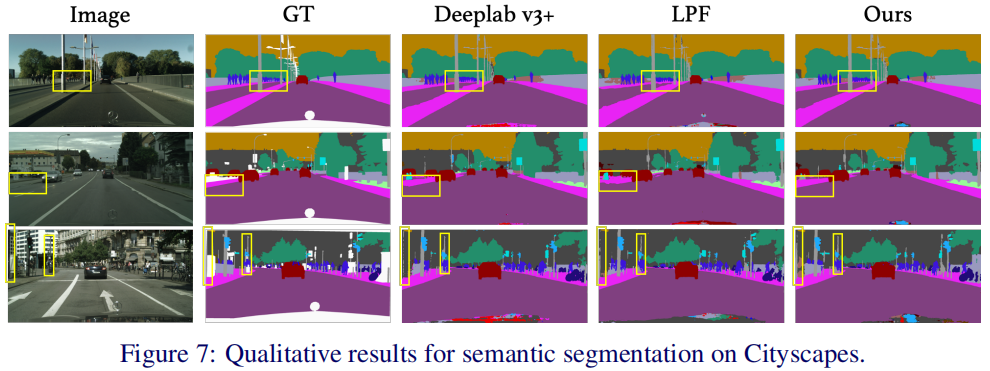
下表给出了所提方法在Cityscape语义分割任务上的性能对比。可以看到:所提方法取得了更高的指标。相比LPF,所提方法取得了0.9mIOU@VOC指标提升与0.6mIOU@Cityscapes指标提升。
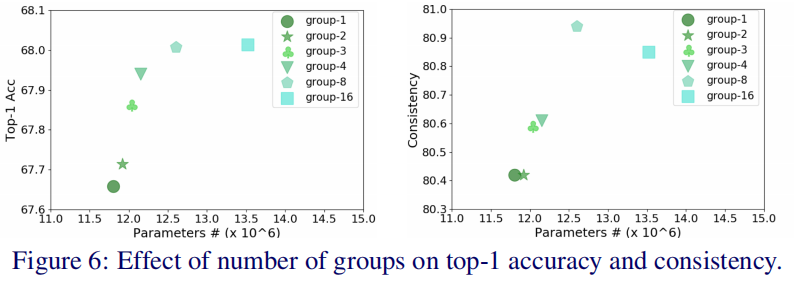
此外,作者还给出了不同分组下的性能对比,见下图。可以看到:提升分组数有助于提升模型性能,当分组数达到8后性能饱和。
最后,作者还给出了不同低通滤波器类型的效果对比,见下表。
![]()
Conclusion
该文提出了一种内容自适应低通滤波器层用于消除Aliasing问题,作者在多个任务(ImageNet分类、COCO实例分割、Cityscapes语义分割)上验证了所提方法的有效性与泛化性能。
该文的思路其实挺简单的,与CARAFE一文有异曲同工之妙。CARAFE采用动态滤波器卷积进行上采样操作,而该文则是采用动态滤波器卷积进行下采样操作。
该文与LPF的关键区别在于:低通滤波器自适应特征。但这种自适应同时也加大了网络的计算量。当然这个计算量加大相比整个网络而言还是比较小的。
该文与其他动态滤波器卷积的一个区别在于:滤波器的权值为正,滤波器的参数为正确保了卷积时的低通特性。这一点与WeightNet中的滤波器处理方式有相似相通之处,WeightNet一文中采用的Sigmoid进行处理,而本文则采用的Softmax。当然,两者的出发点是不相同的,感兴趣的同学可以去看一下上述几篇文章。
-
CARAFE:Content-Aware ReAssembly of FEatures
-
LPF:Making Convolutional Networks Shift-invariant Again.
-
WeightNet Revisiting the Design Space of Weight Networks
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
![]()
下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加微信群
![]()
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()