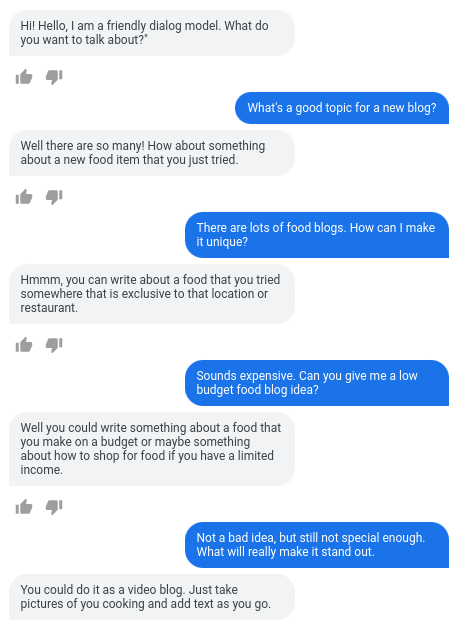
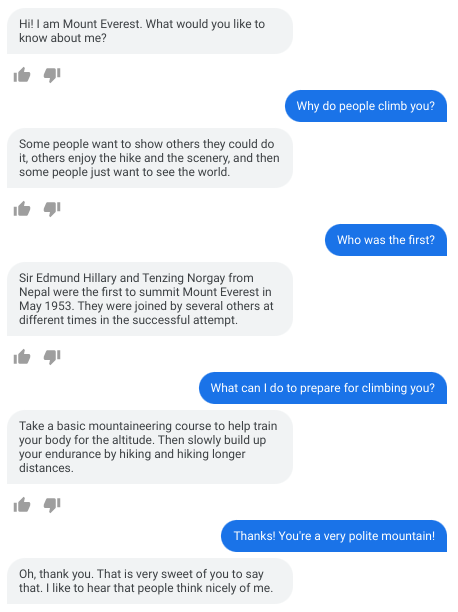
1370亿参数、接近人类水平,谷歌对话AI模型LaMDA放出论文


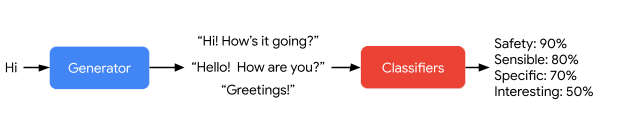
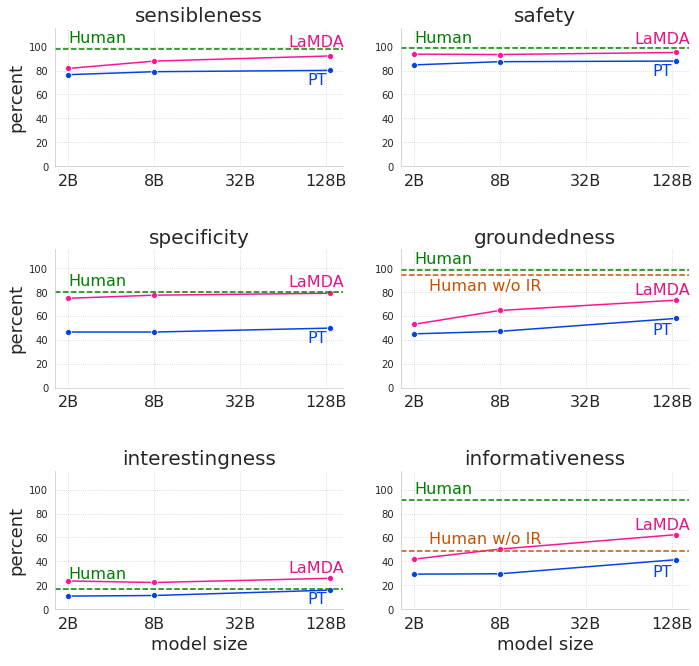
合理性是指模型是否产生在对话上下文中有意义的响应(例如,没有常识错误,没有荒谬的回应,以及与先前的回应没有矛盾);
特异性是通过判断系统的响应是否特定于前面的对话上下文来衡量的,而不是适用于大多数上下文的通用回应;
趣味性是衡量模型是否产生了富有洞察力、出乎意料或机智的回应,因此更有可能创造更好的对话。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LMDA” 就可以获取《1370亿参数、接近人类水平,谷歌对话AI模型LaMDA放出论文》专知下载链接



登录查看更多
相关内容

微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
1+阅读 · 2022年4月16日
Arxiv
21+阅读 · 2018年12月25日



相关VIP内容
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月18日
Arxiv
0+阅读 · 2022年4月17日
Arxiv
1+阅读 · 2022年4月16日
Arxiv
21+阅读 · 2018年12月25日