别再用假任务做小样本学习实验了!来试试这个全新基准数据集

NLP 小样本研究往往使用人为构造的 N 分类任务来评价模型性能。然而,一方面,这些人造的简单任务不能反映真实世界 NLP 问题的复杂性;另一方面,现有 NLP 小样本研究缺乏一个统一的 benchmark,导致实验效率低下。
为此,我们标注了全新的小样本联合学习基准数据集 FewJoint,并基于该数据集组织了 SMP2020-ECDT 小样本对话语言理解评测,同时提供了适配 FewJoint 的全新小样本工具平台 MetaDialog。

本文主要内容:

FewJoint 基准数据集介绍
1.1 简介
小样本学习(Few-shot Learning)旨在像人一样只用几个样本学习新的任务,近年来已经成为受到整个机器学习社区关注的热点问题,并被看作是让机器智能接近人类智能的关键方向。

Few-shot Learning 在计算机视觉领域和理论领域快速发展,但在 NLP 领域的进展却相对缓慢。造成这种差异性的一个主要原因是缺少公共的评价基准(benchmark)。
已有的 Few-shot NLP 研究多是在自己构造的数据集上进行实验,研究者经常需要复现前人工作而不同论文的结果也往往不是直接可比较的。这种低效的实验方式极大地影响了研究效率,也阻碍了方法的累积进步。
为此,我们推出了一个全新的小样本基准数据集 – FewJoint,基于该数据集,我们还组织了 SMP 2020 的小样本对话语言理解评测。不同于过往的 NLP 小样本研究使用人为构造的简单文本分类任务,我们引入了包含 59 个真实领域的对话语言理解任务(Spoken Language Understanding,SLU)。
SLU任务在简单文本分类(Intent Detection)之外,还涵盖了序列标注(Slot Filling)与多任务联合学习(Joint Learning)。这些更高级且真实的任务使得 FewJoint 能比现有的简单文本分类任务更好地反映真实世界 NLP 任务的难度和复杂性。
FewJoint 基准数据集主要有如下几个特点:
-
包含 59 个真实 domain,目前 domain 最多的对话数据集之一,可以避免构造模拟 domain,非常适合小样本和元学习方法评测。 -
反映真实 NLP 任务难度,打破目前 Few-shot NLP 只做文本分类等简单人造任务的局限性。 -
完全公开,提供易用的 NLP Few-shot Learning Benchmark。 -
提供配套 N LP few-shot learning 工具平台——MetaDialog,方便快速开展实验。
1.2 数据集构造
我们选取了讯飞 AIUI 开放平台上的 59 个真实对话机器人 API 作为我们的领域。用户语料的来源主要包括两部分:
(1)来自平台真实用户语料
(2)领域专家人工构造的语料
两个数据来源的数据比例大概为 3:7。
在对每一条数据进行用户意图和语义槽标注后,我们将所有 59 个 domain 分成 3 个部分:45 个训练 domain,5 个开发 domain,9 个测试 domain。我们将测试和开发 domain 数据重构为小样本学习形式:每个 domain 包含一个人工构造的 K-shot 支持集(support set),以及一个由剩余其他数据组成的查询集(query set)。
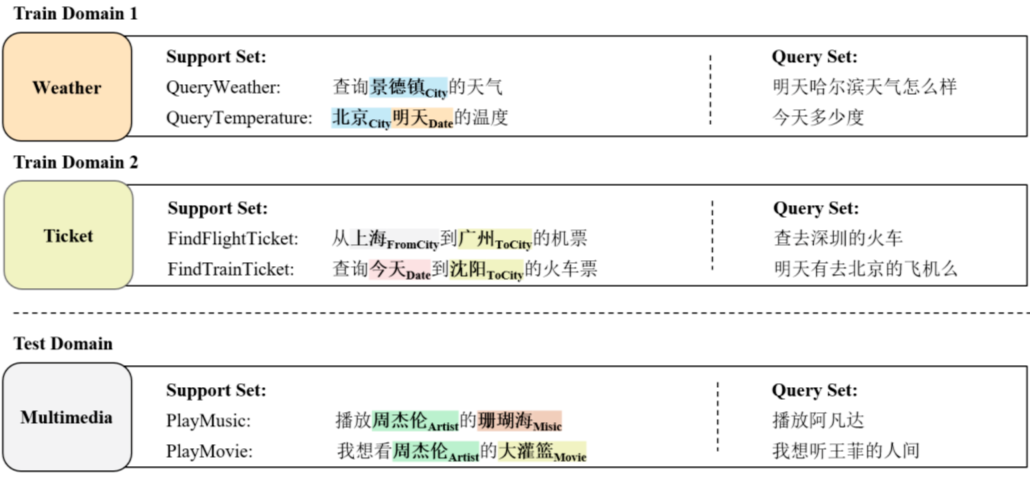
如图 2 所示,在 FewJoint 上实验时,模型先在训练 domain 上学习通用的先验知识。然后在每个测试 domain 上,模型根据少量 support set 中的样例,预测查询集中的样本的用户意图(Intent)和语义槽(Slot)。
1.3 数据集统计
表1是我们收集的原始用户语料信息以及相应的语义框架标注信息。
|
统计内容 |
统计值 |
||
|
语料总句子数 |
6,694 |
||
|
平均句子长度 |
9.9 |
||
|
总领域数 |
59 |
||
|
训练领域数 |
45 |
||
|
开发领域数 |
5 |
||
|
测试领域数 |
9 |
||
|
总意图类别数 |
143 |
||
|
平均每个领域意图数 |
2.42 |
||
|
总语义槽类别数 |
205 |
||
|
平均每个领域语义槽数 |
3.47 |
表 2 是我们重构后的小样本评测集信息,我们提供 4 种 shot 设置:1,3,5,10。其中,3-shot 是我们所推荐的主设置。
|
Few-shot设置 |
支持集大小 |
查询集大小 |
|
|
1-shot |
Dev |
22 |
556 |
|
Test |
77 |
1,624 |
|
|
3-shot |
Dev |
66 |
511 |
|
Test |
213 |
1,572 |
|
|
5-shot |
Dev |
108 |
470 |
|
Test |
341 |
1,439 |
|
|
10-shot |
Dev |
192 |
389 |
|
Test |
668 |
1,120 |
|
|
|
|
平均支持 集意图数 |
平均支持 集语义槽数 |
|
1-shot |
Dev |
1.4 |
1.7 |
|
Test |
1.3 |
2.0 |
|
|
3-shot |
Dev |
4.1 |
4.1 |
|
Test |
3.7 |
4.6 |
|
|
5-shot |
Dev |
6.8 |
6.5 |
|
Test |
6.0 |
7.3 |
|
|
10-shot |
Dev |
12 |
11.4 |
|
Test |
11.7 |
15.0 |
|
1.4 实验结果
这里我们给出基于该数据集的 baseline 结果,在Prototypical Network (SepProto)[1] 基础上,我们尝试了两种常用的 trick:
(2) Finetune: 在目标 domain 精调 Metric 函数。
实验结果如表 3 所示,可以看到 JointProto 明显地优于 SepProto,这体现出了联合学习 Intent 和 slot 的必要性。同时 Finetune 的结果提升也显示出了通过精调来适应目标领域的重要性。
|
Model |
Intent Acc. |
Slot F1 |
Sentence Acc. |
|
SepProto |
72.30 |
34.11 |
16.40 |
|
JointProto |
78.46 |
40.37 |
23.65 |
|
JointProto+Finetune |
73.82 |
61.79 |
38.97 |

2.1 比赛概况
ECDT 中文人机对话技术评测(The Evaluation of Chinese Human-Computer Dialogue Technology)是 SMP 全国社会媒体处理大会的评测项目之一,我们在今年的评测中首次引入了小样本对话语言理解技术任务。
经过近 4 个月的激烈角逐,来自招行 AI Lab、上海交通大学、北京大学、香港中文大学等队伍获得了奖项。完整的获奖名单如下:
|
|
获奖队伍 |
队员 |
|
|
一等奖 |
招行AI Lab CC |
文俊杰、郑桂东、刘沛奇、段旭欢、刘奕君 |
|
|
二等奖 |
上海交通大学 SpeechLab |
俞凯、朱苏、陈露、曹瑞升、李杰宇、杨晨宇 |
|
|
北京大学 |
邹月娴、周培林、侯晓龙、徐伟元 |
||
|
三等奖 |
香港中文大学-高可信工程实验室 |
冯沛璋、王鸿儒、刘常健 |
|
|
Coca-Dialog |
陈凯、张小童、牛萌、杨鲁锋 |
||
|
来也科技小组 |
段沛宸、于孟萱 |
||
|
1STEP.AI |
顾夏辉、李伟、刘威 |
||
2.2 参赛方法
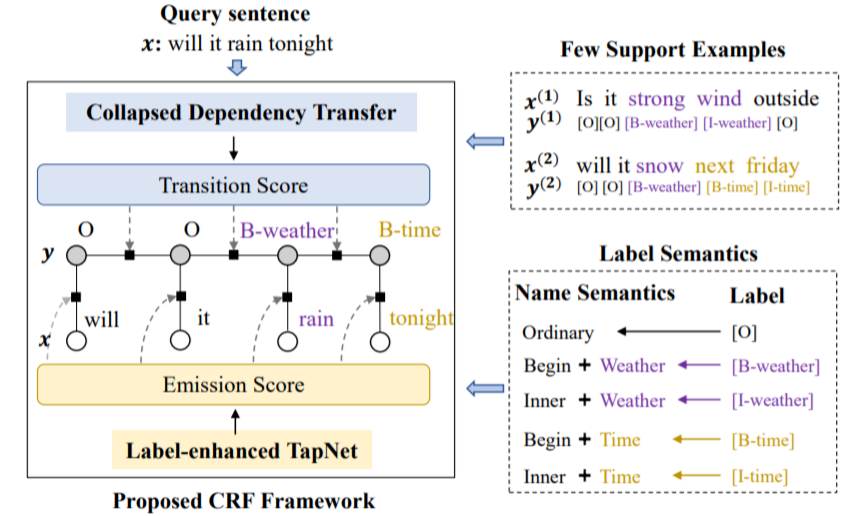
在采用的比赛方法方面,参赛队基本都使用了 Finetuning 和 Joint Learning 的技巧,前几名的方法都使用了基于 Metric Learning 的小样本学习框架,并采用了 Collapse Dependency Transfer [2] 策略处理小样本下的序列标注问题。
第一名的解决方案的模型主体构建于本基准数据集提供的平台 MetaDialog,在语义槽识别中还引入了 L-TapNet 模型 [2]。在解决意图识别上,参赛队主要 Finetune 简单的分类器,或者利用原型网络 Prototypical Network。其中,前者展示出更好的效果。
Collapsed Dependency Transfer 和 L-TapNet 是 A CL 2020 长文 Few-shot Slot Tagging [1] 中提出的方法。具体的,为了建模标签之间的依赖关系(Transition Score),该工作提出了一种跨领域建模标签依赖关系的方法——坍缩依赖迁移(Collapsed Dependency Transfer, CDT)。
CDT 首先从数据充足的源域(Source Domain)学习抽象标签依赖关系,并在小样本的目标域中泛化学到的依赖关系来辅助标签序列的预测。
为了在小样本情形下得到每个词的标签概率(Emission Score),该工作还提出了 L-TapNet,来基于每个词和不同标签表示的相似度计算属于不同标签的概率。L-TapNet 在计算时利用了 label 名字中的语义信息,并通过线性偏差消除法(Linear-error Nulling)构造映射空间来将不同标签类别在 embedding 空间有效分开。

小样本平台工具MetaDialog
我们为 FewJoint 数据集提供了一个完全适配的自然语言小样本工具平台——MetaDialog。它为两种主要的自然语言任务(文本分类和序列标注)提供 Few-shot Learning 下的解决方案。该平台的主要特点如下:
(1)SOTA 解决方案
支持CDT [2] 用于序列标记任务的 Few-shot Learning。
支持使用标签名称或标签描述中的语义信息。
支持与 huggingface/transformers 兼容的各种深度预训练词表示,例如 BERT 和 Electra。
支持成对嵌入表示机制(Pair-wise Embedding)[2] [3]。
(2)易用且灵活的架构
提供通用的 Train & Testing 工具。
支持具有统一接口的各种小样本模型,例如 ProtoNet 和 TapNet。
-
支持多种可以快速切换的相似性度量方式和 logits 缩放方法。 -
提供元学习风格的小样本数据生成工具。
相关链接:
数据集论文:
https://arxiv.org/abs/2009.08138
数据集下载地址:
https://atmahou.github.io/attachments/FewJoint.zip
小样本工具平台主页地址:
https://github.com/AtmaHou/MetaDialog

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






