赛尔原创 | IJCAI 2018 基于主题信息的神经网络作文生成模型
本文介绍哈尔滨工业大学社会计算与信息检索研究中心(SCIR)录用于IJCAI 2018的论文《Topic-to-Essay Generation with Neural Networks》,在本文中,我们提出了段落级作文生成任务,其输入为固定个数的话题词,输出是一段关于这些话题词的作文描述;在方法层面,我们采用Seq2Seq的神经网络框架,针对多主题输入情况,我们加入主题感知的coverage方法,使得作文能够在表达不同主题语义的情况下,着重针对某一主题进行表述。我们自动构建了两个作文相关语料库,并通过客观和主观评价说明我们的模型结果均优于基线方法。本论文的实验代码和数据已经开源:https://github.com/hitcomputer/MTA-LSTM
论文作者:冯骁骋、刘家豪、秦兵、刘挺
关键词:文本生成,神经网络,作文生成
联系邮箱:xcfeng@ir.hit.edu.cn
个人主页:http://ir.hit.edu.cn/ xcfeng/
1. 引言
随着近几年来人工智能的飞速发展,我们想要去验证一下机器是否真的能够像人一样能说会道,其中作文自动生成可以看作是一个极具代表性的任务,不仅需要计算机去理解题意还要计算机针对所理解内容生成较长篇幅的作文,这其中逻辑通顺、语义连贯、主题明确、表达清晰都是所要研究的难点,针对这一问题,我们定义了段落级作文生成任务,其输入是多个话题词,输出是围绕这些话题词的一些文本,可以看作是段落级的作文。图1给出了具体示意,其输入的话题词是“妈妈”,“孩子”,“希望”,“长大”和“母爱”。

图1 用五个主题词生成的段落示例
在方法层面,我们希望模型能够接受多个话题词的控制,生成包含这些语义的一段文本,并且篇幅较长。为此我们提出了一个主题感知(Topic-aware)的生成模型。具体而言,我们构建了一个多主题的Coverage向量,它学习每个话题词的权重并且在生成过程中不断更新,然后,Coverage向量输入到注意力网络中,用于指导文本生成。与其它的Coverage方法不同的是,我们会预先对多个话题词进行估计,找到一个最核心的词作为整个段落的主题,这样我们的模型能够保证所生成的段落可以覆盖所有的话题词也能够保持一个较为明确的主题。此外我们还自动构建了两个段落级的中文作文生成语料,包含305,000个作文段落和55,000个知乎文本。实验表明,我们的主题感知生成模型在BLEU 指标上相比于其他模型获得了更好的结果。而且人工评价结果表明我们所提出的模型有能力生成连贯并且和输入话题词相关的段落文本。
2. 方法
本小节将详细介绍我们的作文生成模型。首先,我们直接将话题词的词向量进行平均,利用平均后的向量来表示话题词集的语义,并通过这一向量来控制LSTM-based decoder进行文本生成。在此之后,我们引入了注意力网络(Attention Network)对话题词和生成词语之间的语义关联进行建模。最后,我们对Attention-based LSTM模型进行扩展,引入覆盖机制(Coverage Mechanism ),该机制能够动态跟踪注意力网络的历史信息,从而加强对还未进行表达的话题词的关注度,最终使得生成文本能够包含所有的话题词语义信息。
2.1 基于词向量平均的文本生成模型(Topic-Averaged LSTM,TAV-LSTM)
本部分我们将介绍基于词向量平均的文本生成模型,这是我们方法的基础版本,采用向量平均的方法来求得话题词集合的语义表示。由于LSTM 模型在文本生成任务中有着非常卓越的表现,所以我们采用LSTM 模型作为生成器解码器。在传统的Encoder-Decoder 模型中,Encoder 部分往往负责将一个长序列(比如一个句子)表示成固定维度的向量,而Decoder 部分则是根据这个向量表示来生成另一个序列。在本文中,我们将话题词平均作为输入,用LSTM进行解码来生成一段文本,具体如图2上部分所示:
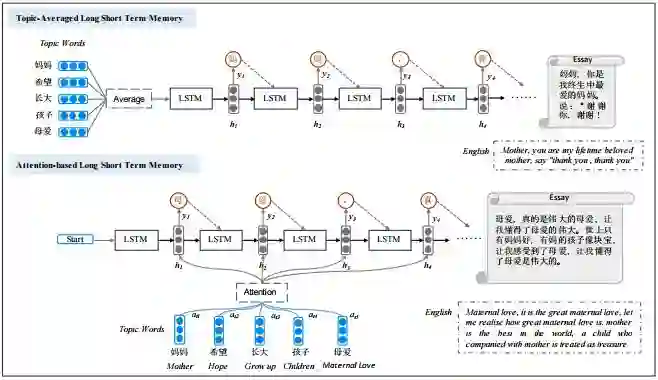
图2 基于词向量平均的文本生成模型与基于注意力网络的文本生成模型
我们按照如下公式计算得到话题词集合的语义表示,并将其作为Decoder的初始状态,用于控制其生成文本,
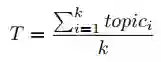
其中T是话题词集合的向量表示,k为输入话题词的个数,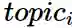
2.2 基于注意力网络的文本生成模型(Topic-Attention LSTM,TAT-LSTM)
上述主题平均模型是直接将话题词的词向量进行平均,也就是说每一个话题词都被同等的对待,相当于我们认为话题词之间是没有重要性差别的。然而这种方法会带来一些歧义,使得话题词集合的语义表示并不是唯一的,例如某个话题词集合向量表示为[0.6, 0.8] ,那么它可以通过两个不同的话题词集合A:[0.5, 0.9] 和[0.7, 0.7] 、B:[0.3, 0.6] 和[0.9, 1.0] 来获得。针对这一问题我们引入了注意力机制(Attention Mechanism)。其作用主要有两方面,一是可以很好的实现对生成文本的控制;二是注意力机制可以刻画话题词和生成文本间的局部相关性,这是符合人类作写规律的。当人类完成一大段作文书写时,显然是某些句围绕一个话题词,而其他句围绕别的话题词,不可能每一句都是包含整个话题词集的语义,这样写出来的作文才具有一定层次感和逻辑关系,符合人们的写作规律。而注意力机制能很好的刻画这种局部相关性,因为在生成每个词时Attention结构会对话题词自动分配不同的权重,即相当于当前生成的这部分由权重比较高的几个话题词所决定。模型结构图如2下部分所示,具体计算细节可以参照原文。
2.3 多主题感知生成模型(Multi-Topic-Aware LSTM, MTALSTM)
虽然上面的注意力模型已经很好地利用话题词的语义信息了,但我们发现这个模型并不能够保证生成的文本包含话题词集的所有语义信息,也就是说可能有话题词所带的语义并没有出现在最终生成的文本内容中。针对这一问题我们提出了多主题感知模型(Multi-Topic-Aware LSTM),具体的结构如图3所示。我们在传统的注意力公示上进行修改,引入coverage机制,如图3所示,我们引入了变量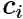
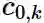
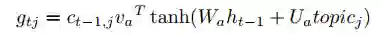
而
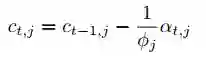
其中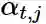
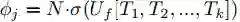
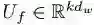
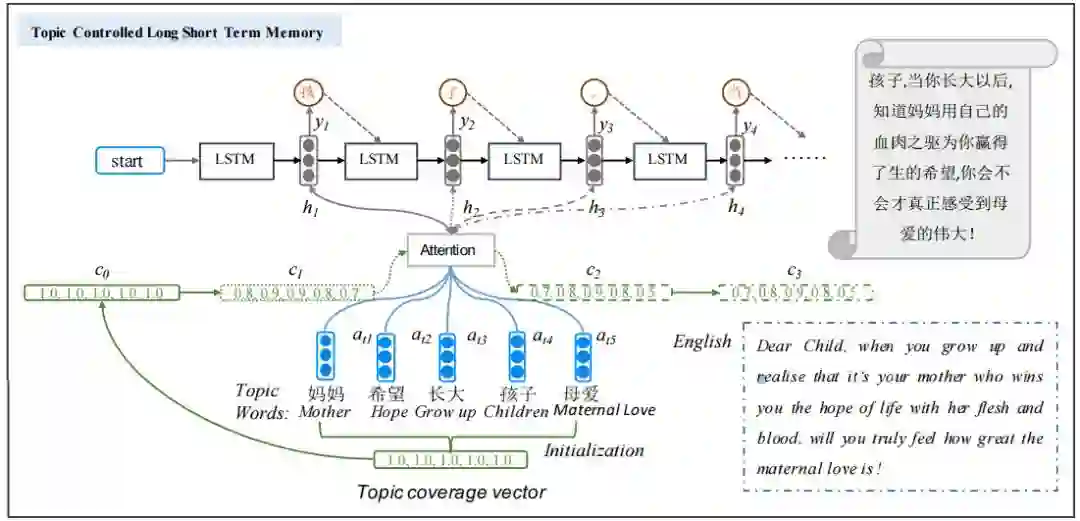
图3 多主题感知生成模型(c是主题词的coverage向量)
2.4 训练
我们采用和机器翻译一样的训练目标,最大化极大似然估计。
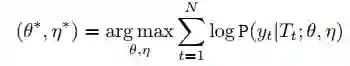
在生成策略上为了保证文本的多样性,我们采用beam-search+sample的策略,beam为10,从中随机选取一个作为文本生成结果。
3. 实验
3.1 语料构建
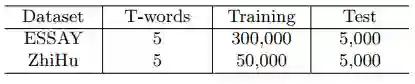
在本文中,我们的研究内容是作文自动生成,更具体的,是生成更多符合多主题的作文文本,为此我们建立一个作文语料库(ESSAY)。写作是中国高考语文卷中的一道大题,因此在互联网上有很多优秀作文样例供广大考生学习。所以,我们打算直接收集这些数据作为训练语料,同时为了保证爬取的文本质量,我们只对那些有评语和评分的作文进行爬取。具体过程如下,1)我们首先爬取了228,110 篇作文,并且这些都是老师评分比较高的;2)由于我们针对的是段落级文本生成任务,所以从这些作文中筛选出词数目在50-100的段落,组成我们的语料数据集;3)我们和诗歌生成一样,用textrank从这些段落中抽取出关键词作为话题词集。具体的语料集数量如表1所示。此外,由于作文语料库是由textrank抽取算法得到的话题词,其结果必然存在一些噪声。为了解决这一问题,我们又爬取了知乎语料库(ZhiHu),在这个数据集中,每个问题文本都有用户给出的1到5个话题词,和作文语料库类似,我们爬取那些词数目在50-100并且有五个话题词的段落,构建语料库,具体数量如表1所示。
表1 数据集信息(T代表主题词的数量)
3.2 实验设置
我们利用哈工大社会计算与信息检索实验室开发的LTP平台对两个语料库的中文进行分词。选择了50,000个高频词作为模型的训练和测试词表。词向量维度为100,用word2vec对之前所有爬取的作文语料进行训练,LSTM隐层为800。模型参数为均匀分布初始化[−0.04, 0.04]。Dropout为0.5,采用AdaDelta算法进行更新,测试阶段采用beam-search+sample的策略。
3.3 实验结果
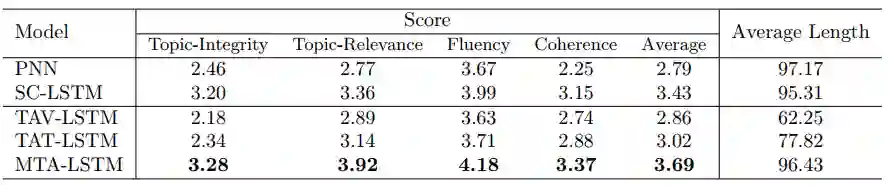
我们首先对提出的各个模型和一些baseline方法进行人工评价,评价指标为话题完整性(Topic-Integrity)、话题相关性(Topic-Relevance)、流畅度(Fluency)和连贯性(Coherence),每一项由三个人进行1-5的打分,之后进行平均,其评测结果如表2所示。在人工评价中,我们对三位打分人员的一致性进行了测试,kappa 值、t检验、Pearson系数都满足要求。
表2 不同方法在ESSAY数据集上得到分值的平均值(最优值用粗体标出)
为了进一步支持人工评价的结果,我们利用BLEU评价指标对实验结果进行了自动评价,结果如图3 所示,各模型性能与人工评价基本一致。接下来我们给出一个较好的生成样例(表4),其输入的话题词为“现在”、“未来”、“梦想”、“科学”和“文化”。
表3 不同方法在ESSAY数据集和ZhiHu数据集上得到的BLEU-2分值
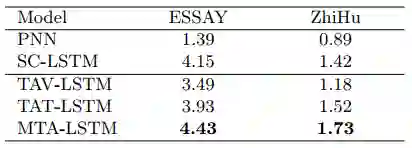
表4 MTA-LSTM模型利用五个主题词生成的段落示例

4. 结论
在本文中,我们提出了面向多主题的段落级作文生成任务,并且针对这一问题开发了主题感知模型。为了进一步验证模型的好坏,我们自动构建了两个语料库,分别是作文语料库和知乎语料库,并在这两个语料库上对不同模型进行比较。人工评价和自动评价结果均显示我们的多主题感知作文生成模型能够获得最好的效果。在未来的工作中,我们将尝试融合一些外部知识和逻辑表达到现有模型中去,以期生成可读性更强的作文文本。
IJCAI 2018系列原创往期推送:
赛尔原创 | IJCAI 2018 利用跨语言知识改进稀缺资源语言命名实体识别
塞尔原创 | IJCAI 2018 在消费意图识别任务上的基于树核最大平均差异的领域自适应
赛尔原创 | IJCAI 2018基于叙事事理图谱和可扩展图神经⽹络的脚本事件预测模型
本期责任编辑: 丁 效
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





