阿里巴巴:Representation Learning在优酷个性化 搜索排序中的应用

源 | 阿里巴巴集团 文 | 搜库 & iDST 转自 | 小象
提升视频搜索排序流量分发效率是实践文娱战略的关键
在用户消费升级的大背景下,文化娱乐已经成为人们生活中非常重要的一部分。马老师曾说过:未来阿里巴巴大发展有两个策略,一个是健康,一个是快乐。而文化娱乐对于承载中国网民的欢乐起到了极大的推动作用。而视频作为文化娱乐的重要载体,如何做好用户和视频内容的连接,对于践行阿里大文娱的战略思想至关重要。
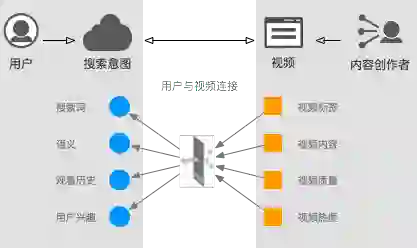
如何做好用户和视频内容的连接,短期来看,是在不断提升对用户和视频内容的理解的前提下,实现流量分发效率的提升。长期来看,是通过一个健康的流量分发生态使得内容生产者有意愿生产更多优质的内容,抓住用户的兴趣点,通过视频内容的精确分发,实现流量分发效率的提升,进一步吸引更多的用户,从而引导内容生产者有针对性的生产优质内容,实现内容流量分发生态的健康发展。优酷搜索作为流量分发的核心入口,如何实现流量分发效率的提升对分发生态的健康运转以及用户粘性提升至关重要。这其中,搜索排序是践行流量分发效率提升的核心场景。
利用表征学习在广度上发掘增益特征和深度特征组合能力来提升流量分发效率
视频搜索排序最基本的三个元素是用户、搜索意图、视频内容。如何通过不同维度的数据来实现对用户、搜索意图和视频内容的表达,是提升流量分发效率的核心。传统的机器学习方法更多是通过长时间的数据挖掘经验积累来做特征工程优化,从广度和深度上来提升预测效果。具体来讲,在广度上,通过寻找能产生增益的特征,从深度上,通过高重要度特征的深度组合来实现模型预测能力的提升。不论是从广度还是深度上的特征工程,都会面临优化后期的投入产出比指数级下降的挑战,通过大量资源投入产出的特征对模型效果的提升非常有限。
优酷与iDST合作,通过RepresentationLearning来发掘广度上的增益特征,深度上的深层组合特征。在搜索转化提升空间非常有限的情况下,依然实现整体搜索用户人均观看时长 4.7%的提升,UPGC搜索用户人均观看时长11.4%以上的提升。用户跳出率下降8.95%.目前Representation Learning已经在优酷个性化搜索排序上全量应用。
通过策略组合和用户个体与共性的特征表达来实现个性化搜索排序
个性化搜索排序核心有两个:用户个体差异化的兴趣表达和用户群体共同的兴趣表达。RepresentationLearning从以上两个角度入手,通过超高维的稀疏编码来表达用户个体,利用深层神经网络拟合群体共性。具体来讲,基于用户id特征、用户的视频观看序列特征,对id和视频观看序列编码后进行模态融合,生成用户个体的embedding表达,即用户的表征向量,作为个性化搜索排序的重要输入特征。实践证明,在用户搜索泛意图的场景下,用户的表征向量能很好的捕获泛意图下的个体的差异化兴趣。视频维度表达上,主要通过视频的id、视频标题文本、视频质量与热度等特征,生成视频的表征表达。视频搜索排序中,视频的表达是核心,同时也是用户和搜索意图表达的基础。通过视频来表征用户相对用户id、用户统计特征更有助于表达用户在视频上的隐含兴趣点。
搜索排序分为三个阶段,检索、粗排、精排。为保证排序中最大化个性化视频候选集,在检索阶段,融入RepresentationLearning作为召回策略之一,并在粗排阶段引入了个性化视频i2i数据,以保证精排阶段有更大的空间提升个性化排序效果。
使用压缩编码技术实现特征降维,提升长尾视频曝光
特征表达层面,为了更好的表达用户个体以及保证个体间的相互独立性,原始特征主要采用One-Hot编码,将特征域下的id特征、文本特征、质量特征映射到超高维度,然后通过多模态的压缩编码技术,在保证个体差异的前提下,对高维特征进行压缩。结合iDST自研的稀疏全连接层,最大程度保留个体差异化特征信息的前提下,实现特征与模型权重系数的压缩。在视频特征维度,另一个面临的挑战是在热门视频特征丰富的情况下,长尾视频很容易在热门视频中淹没,为解决此类问题,引入挂靠编码。利用相似视频i2i数据,使得冷门视频与热门视频共享权值,尽可能缓解行为数据对长尾冷门视频的淹没效应。压缩编码能极大的降低模型复杂度并加快模型迭代效率,同时也是特征域间多模态融合的基础。
域间独立的特征编码网络,特征域输出向量的多模态融合
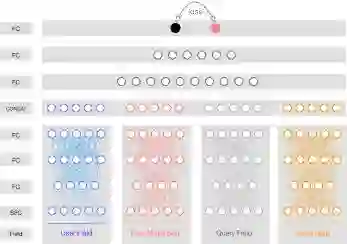
如上图所示,第一层是对特征域编码层,按照前面提及的用户、搜索意图、视频三元素。在用户维度,划分了用户id域、用户观看视频序列域。搜索意图维度,划分了搜索词id域、搜索词视频表达域、文本编码域。视频维度,划分了视频统计特征域、视频文本编码域、视频i2i域。合计8个相互独立的域(上图以4个特征域为例展示)。
第二层和第三层不同特征域间网络结构相互独立,通过稀疏编码优化的全连接层对第一层的高维特征域进行降维,把高维信息投影至低维的向量空间中。再通过第三层全连接层对域内信息的二次编码,输出域内特征向量。然后通过第四层concat层对域间的id特征向量、行为特征向量、文本特征向量和观看序列特征向量做多模态的特征向量融合。之后经过两层的全连接网络实现对给定用户和搜索意图下每个视频的排序分值。
通过REPL优化平台流程化实现特征工程、模型训练与预测评估
阿⾥集团的离线⼤数据处理任务基本基于ODPS平台,但是深度学习相关的模型训练及调优在GPU上往往更为方便及高效。iDST深度学习REPL项目组基于电商数据探索了深度学习表征学习的特征抽取能力,抽取出来的REPL特征被应用于电商的搜索和推荐等多个领域,取得了不错的效果。在这些探索的基础上,iDST算法、产品及工程团队对相关流程进行了整理抽象,实现了对ODPS的离线处理任务与REPL相关的GPU训练任务的模块化及一体化调度,建设了深度学习REPL平台。用户在REPL平台之上,可以方便的使用REPL相关的功能,通过前端页面或是API方便的进行深度学习REPL相关的特征工程,模型训练以及预测评估工作。平台同时提供了REPL特征及模型的管理功能,用户可以基于自己产生的特征模型,搭建需要的模型预测服务。总之,平台集成了部分REPL相关的流程和功能,让用户可以方便的使用,以较低的成本在业务场景进行REPL相关的应用探索、实验及调优。
模型离线与在线的拆分、搜索架构融合实现
所有的深度学习模型在输入维度高,网络结构复杂的情况下,在线完整的实现前向网络预测都会面临响应耗时的挑战,对于复杂的网络,即使使用GPU也很难保证在线的预测性能。基于此类问题,我们对整个神经网络做等价拆分,大部分计算工作在离线部分使用GPU计算,针对不同特征域分别生成中间的特征向量,不同特征域的特征向量通过一定形式的叠加,相当于等价实现了整个预测网络。由于小部分网络在线实现,极大缓解了整个前向网络预测的耗时增加。
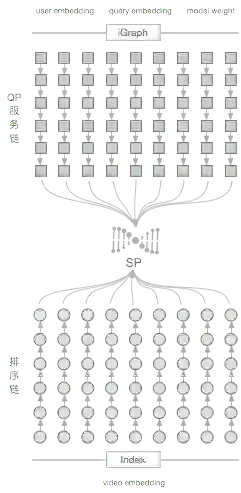
通常情况下,搜索架构主要QP,SP, 索引三部分构成。QP负责搜索意图方面的工作,索引负责倒排与正排索引及算分。简单来说,一次搜索发起,SP调用QP获取搜索意图相关的信息后,把请求发送至Searcher,算分插件对召回的每个视频Doc算分后进行排序。
Representation Learning的工程实现如下,离线计算的用户表征向量、搜索词表征向量以及模型文件由QP服务提供,视频表征向量放入正排。每次请求发起,经SP调用QP把用户域搜索词表征向量及模型文件发至Searcher,Searcher的算法插件在拿到用户、搜索词、视频表征向量和模型文件后,经过在线部分的模型预测生成每个视频Doc的分数进行排序。
上线后,经过ABtest测试,整体来看,人均TS(搜索产生的总TS/搜索用户数)有4.7%的提升,用户跳出率(用户搜索后无任何有效点击)下降了8.95%。从UPGC来看,人均TS提升了11.4%,RepresentationLearning主要解决个性化搜索的效率问题,UPGC在个性化上有更大的空间,这也正是UPGC提升效果明显的原因。
其他延伸
随着深度学习的成熟以及在工业界取得的成果,深度学习与传统机器学习的融合也广受关注。以传统机器学习输出特征,深度学习模型预测,或深度学习输出特征,传统机器学习做模型预测也愈发流行。这使得特征与模型和界线越来越模糊,特征即模型,模型即特征。我们也尝试基于RepresentationLearning输出特征,然后使用GBDT做上层的融合,以及使用GBDT叶子节点做特征,使用RepresentationLearning来融合,模型预测效果均有不同程度的改善。

马恩驰 enchi.mec@alibaba-inc.com






