用于目标定位的全局平均池化
编者按:Udacity深度强化学习课程负责人Alexis Cook讲解了全局平均池化(GAP)的概念,并演示了为分类问题训练的GAP-CNN在目标定位方面的能力。
图像分类任务中,卷积神经网络(CNN)架构的常见选择是重复的卷积模块(卷积层加池化层),之后是两层以上的密集层(全连接层)。最后密集层使用softmax激活函数,每个节点对应一个类别。
比如,VGG-16的架构:
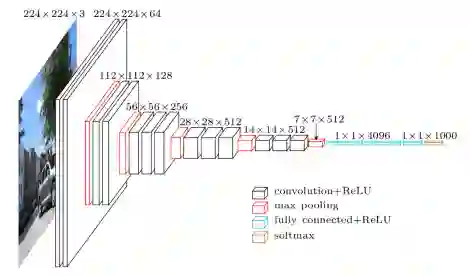
译者注:上图中,黑色的是卷积层(ReLU激活),红色的是最大池化层,蓝色的是全连接层(ReLU激活),金色的是softmax层。
运行以下代码,可以得到VGG-16模型的网络层清单:(译者注:需要安装Keras)
python -c 'from keras.applications.vgg16 import VGG16; VGG16().summary()'
输出为:
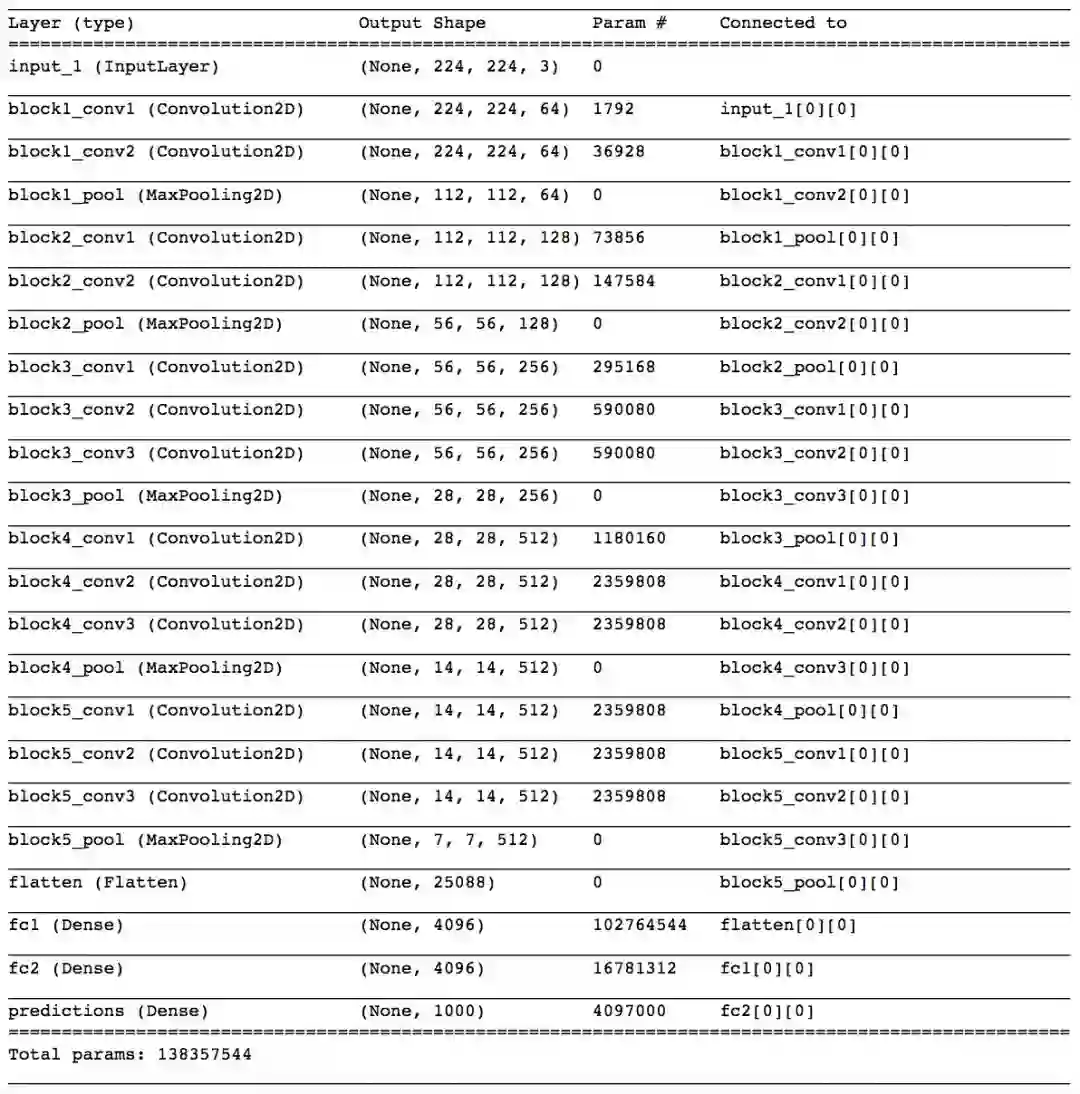
你会注意到有5个卷积模块(两到三个卷积层,之后是一个最大池化层)。接着,扁平化最后一个最大池化层,后面跟着三个密集层。注意模型的大部分参数属于全连接层!
你大概可以想见,这样的架构有过拟合训练数据集的风险。实践中会使用dropout层以避免过拟合。
全局平均池化
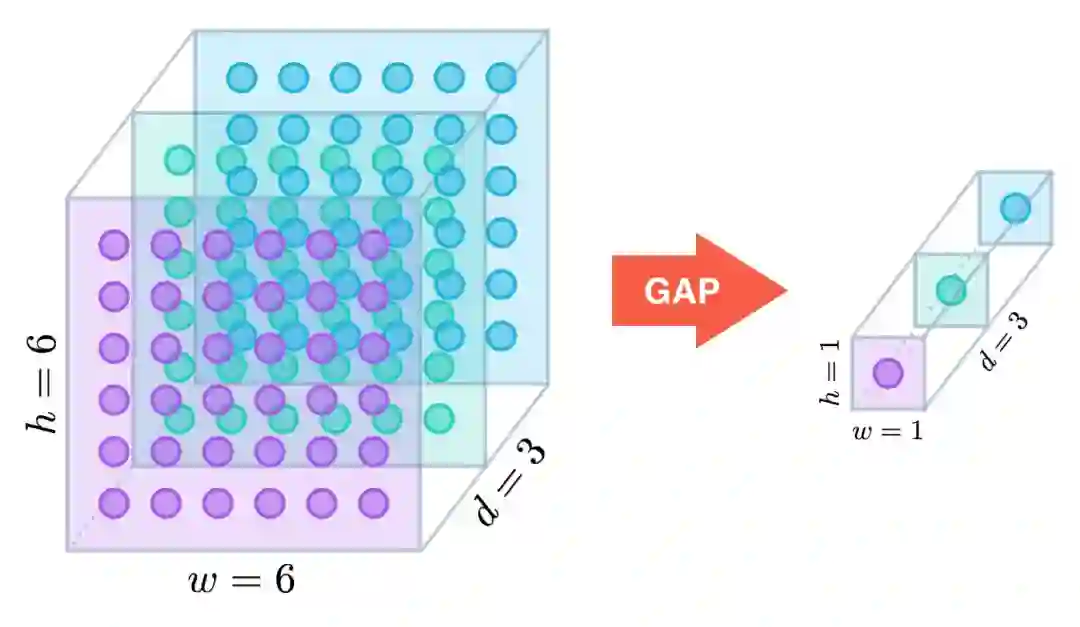
最近几年,人们开始使用全局平均池化(global average pooling,GAP)层,通过降低模型的参数数量来最小化过拟合效应。类似最大池化层,GAP层可以用来降低三维张量的空间维度。然而,GAP层的降维更加激进,一个h × w × d的张量会被降维至1 × 1 × d。GAP层通过取平均值映射每个h × w的特征映射至单个数字。
在最早提出GAP层的网中网(Network in Network)架构中,最后的最大池化层的输出传入GAP层,GAP层生成一个向量,向量的每一项表示分类任务中的一个类别。接着应用softmax激活函数生成每个分类的预测概率。如果你打算参考原论文(arXiv:1312.4400),我特别建议你看下3.2节“全局平均池化”。
ResNet-50模型没这么激进;并没有完全移除密集层,而是在GAP层之后加上一个带softmax激活函数的密集层,生成预测分类。
目标定位
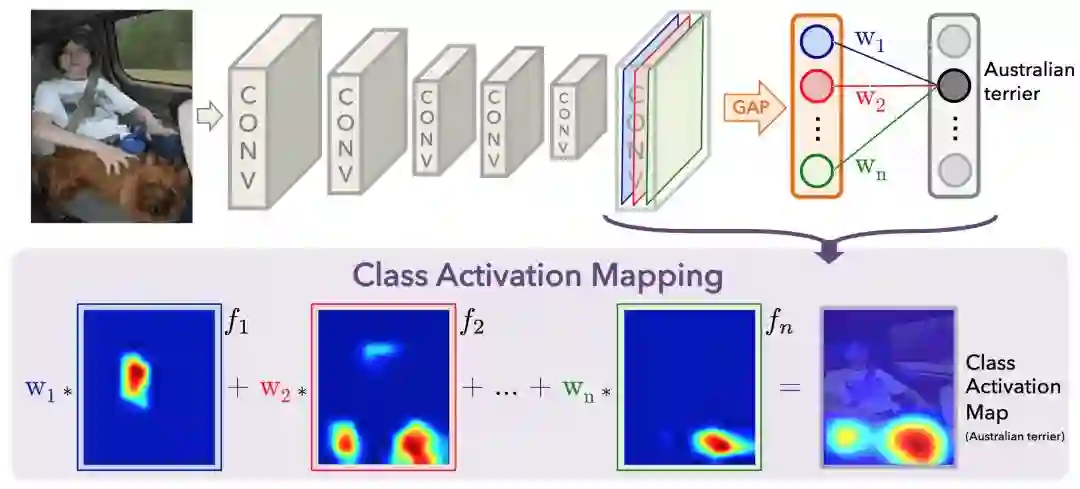
2016年年中,MIT的研究人员展示了为分类任务训练的包含GAP层的CNN(GAP-CNN),同样可以用于目标定位。也就是说,GAP-CNN不仅告诉我们图像中包含的目标是什么东西,它还可以告诉我们目标在图像中的什么地方,而且我们不需要额外为此做什么!定位表示为热图(分类激活映射),其中的色彩编码方案标明了GAP-CNN进行目标识别任务相对重要的区域。
我根据Bolei Zhou等的论文(arXiv:1512.04150)探索了预训练的ResNet-50模型的定位能力(代码见GitHub:alexisbcook/ResNetCAM-keras)。主要的思路是GAP层之前的最后一层的每个激活映射起到了解码图像中的不同位置的模式的作用。我们只需将这些检测到的模式转换为检测到的目标,就可以得到每张图像的分类激活映射。
GAP层中的每个节点对应不同的激活映射,连接GAP层和最后的密集层的权重编码了每个激活映射对预测目标分类的贡献。将激活映射中的每个检测到的模式的贡献(对预测目标分类更重要的检测到的模式获得更多权重)累加起来,就得到了分类激活映射。
代码如何运作
运行以下代码检视ResNet-50的架构:
python -c 'from keras.applications.resnet50 import ResNet50; ResNet50().summary()'
输出如下:

注意,和VGG-16模型不同,并非大部分可训练参数都位于网络最顶上的全连接层中。
网络最后的Activation、AveragePooling2D、Dense层是我们最感兴趣的(上图高亮部分)。实际上AveragePooling2D层是一个GAP层!
我们从Activation层开始。这一层包含2048个7 × 7维的激活映射。让我们用fk表示第k个激活映射,其中k ∈{1,…,2048}。
接下来的AceragePooling2D层,也就是GAP层,通过取每个激活映射的平均值,将前一层的输出大小降至(1,1,2048)。接下来的Flatten层只不过是扁平化输入,没有导致之前GAP层中包含信息的任何变动。
ResNet-50预测的每个目标类别对应最终的Dense层的每个节点,并且每个节点都和之前的Flatten层的各个节点相连。让我们用wk表示连接Flatten层的第k个节点和对应预测图像类别的输出节点的权重。
接着,为了得到分类激活映射,我们只需计算:
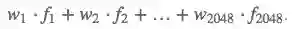
我们可以将这些分类激活映射绘制在选定的图像上,以探索ResNet-50的定位能力。为了便于和原图比较,我们应用了双线性上采样,将激活映射的大小变为224 × 224.

如果你想在你自己的目标定位问题上应用这些代码,可以访问GitHub:https://github.com/alexisbcook/ResNetCAM-keras
原文地址:https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/



