机器翻译的技术进化史——机器翻译专题(一)
2007年的时候,小线菌还在和同学一起吐槽谷歌翻译还没有小学生翻译得好。一个广泛流传的段子是“How are you?"会被翻译成”怎么是你?",而“How old are you?"会被翻译成”怎么老是你?"一笑之余,机器翻译好像也被等同成了不靠谱的翻译。
2017年,不会说当地语言已经不能成为阻碍人们出行的理由了。机器翻译软件已经能够将大部分用语准确地翻译成另一种语言。再佐以肢体语言的比比划划,与不说同一种语言的人沟通,已经不再是一个难题。短短10年间,机器翻译背后的技术到底有了怎样翻天覆地的变化呢?
今天,小线菌将努力用最简单的语言来带你领略机器翻译技术的前世今生。
普遍意义上,1990年以后都算作机器翻译的新时期。但是这过去的近30年间,机器翻译的进展速度是在高速增加的。总的来说,机器翻译的变化源于三方面:从基于规则、到基于统计模型、到基于神经网络,从基于词、到基于短语、到基于整句,从必须使用大规模平行语料库、到可以使用单语语料库、到实现零数据翻译。
从基于规则,到基于统计模型,再到基于神经网络
最开始的时候,机器翻译就好像个只拿了一本字典和一本语法书就打算兴致勃勃地翻译一门从未见过的语言的孩子。可以想见这个孩子翻译出的内容一定是粗糙的:用词不精准,句法不连贯,内容表达不清晰。这一翻译方法主要基于语法规则和逐词翻译,是机器学习最早期的模样。
后来,随着数学理论的介入,机器翻译开始以统计模型作为基础。统计机器翻译 (SMT, Statistical Machine Translation) 的基本思想是对大量的平行语料进行统计分析,以此来构建统计翻译模型,并在这模型的基础上定义要估计的模型参数,并设计参数估计算法。简而言之,统计机器翻译就是让机器通过大量分析平行语料库中的内容,根据这些内容类比出对于新内容最恰当的翻译方式。
一直到2013年,基于统计模型的机器翻译一直都是主流。13年来,基于人工神经网络的机器翻译 (NMT, Neural Mahcine Translation) 逐渐兴起。人工神经网络翻译拥有一个有海量节点的深度神经网络,通过传到运算,实现生成另一种语言的译文。2016年底,谷歌翻译开发并使用了Google神经机器翻译系统 (GNMT, Google NMT) ,神经网络机器翻译正式登了上舞台。与之前的统计模型相比,神经网络机器翻译具有译文流畅、准确易理解,翻译速度快等优点。

从基于词,到基于短语,再到基于句子
基于统计的机器翻译最早始于1949年的瓦伦·韦弗基于信息论提出的理论。第一个可行模型则来自IBM的研究员Brown, Pietra, Mercer在1993年发表了《统计机器翻译的数学理论:参数估计》。在这一论文中,作者们提出了基于词对齐的统计翻译模型,这也标志着现代统计机器翻译方法的诞生。
然而,受限于建模单元的大小与模型的适应性,基于词对齐的模型训练时长可能很长。2008年Gao和Vogel的论文显示,1千万句、约3亿词的中文-英文平行语料库在Intel Xeon 2.4GHz的服务器上运行需要六天时间。这显然无法满足即时翻译的需求。因此,统计模型也开始了不断的迭代进化。进化的第一步是从语。短语的用法基本固定,无论在怎样的上下文中,语义的改变都有限。因此,使用短语作为翻译算法的基本单位比起使用词语来说,可以得到更为精准的结果。基于短语的机器翻译 (PBMT, Phrase Based Machine Translation) 就此诞生。
2003年,爱丁堡大学的Koehn提出了短语翻译模型,使机器翻译效果得以显著提升。同年,Och提出了最小错误训练 (Minimum Error Rate Training),使得运算成本大规模降低,工业化应用成为可能。在他们的推动下,短语翻译模型开始成为了主要的研究方向。2005年,David Chang提出了层次短语模型。这意味着算法会开始考虑不同层级的短语,并更好地将它们翻译并组织排序。从2006到2016的十年间,PBMT都是机器模型的主要生产力。
但是基于短语的翻译仍旧不是最完善的解决方案:PBMT只能读出局部的上下文联系,在较长的句子中,PBMT往往会不准确或者忽略了句法特征。那么,如何才能了解更深层次的上下文关系呢?基于句子的机器翻译应运而生——人工神经网络机器翻译(NMT)。
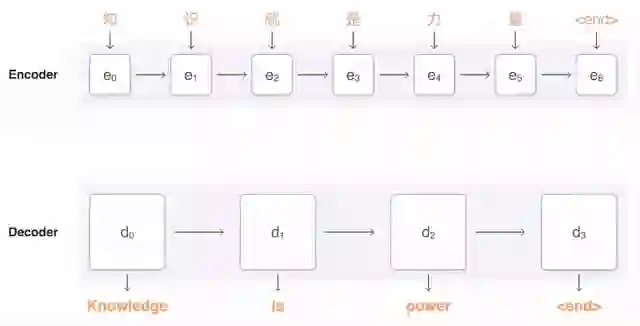
NMT的主要代表是Google推出的GNMT。通过使用长短时记忆 (LSMT, Long Short-Term Memory) 与循环神经网络 (RNN, Recurrent Neural Network),NMT模型可以将任意长度的句子转化为向量,同时将比较重要的单词在记忆里保存比较长的时间。这使得计算机对于语义有了一定的理解,而不是仅仅地在进行字面匹配。
可是机器是如何区分什么是一个句子中的核心内容并理解语义的呢?GNMT提出了在转换器(Transformer) 中建立关注机制 (Attention Mechanism) 。这一机制将句中的每个单词与所有其他单词逐一比对,并为每个单词与别的单词的关联程度逐一打分。这使得一个指代模糊的单词在句子的语境下有了更清晰的具体指代对象。(下图中,蓝色连线的颜色越深则说明关联程度越高。
从使用大规模平行语料库,到可以使用单语语料库,到实现零数据翻译
至我们刚刚讨论的GNMT为止,机器翻译的效率与能力都在飞速地提升着。可这些翻译模型都有一个前提:需要使用大规模的平行语料库 (Large-scale Parallel Corpora)。可大规模的平行语料库收集成本高,也并不适用于所有语种。在这样的情况下,有没有可能我们可以通过使用单语语料库来实现智能的机器翻译呢?
Facebook提出了一种模型,将两种不同的语言从各自的单语语料库 (Monolingual Corpora) 中提取句子,然后映射到相同的潜在空间。通过学习这个潜在空间,对两种语言进行重构。这个模型获得32.76的BLEU值。这也意味着这种i性能的神经机器翻译方法可以在无监督的情况下,利用单语语料库学会两种语言之间的翻译。
Google也在16年11月提出了零数据翻译 (Zero-Shot Translation) 的可能性。零数据翻译指的是通过参数共享,系统将可以把翻译知识从一个语言对迁移到其他语言对。比如说,系统从未学习过如何进行日语与韩语的互译,但会英语与日语以及英语与韩语的翻译。通过在句子前加入人工标记 (token) 来明确目标语言,零数据翻译模型将可以实现通过单一模型来翻译多种语言,而不需要增加新的参数,并且能够进一步提升翻译质量。
小线菌的划重点时间!
机器翻译在过去几十年间快速成长,我们可以把他类比成一个孩子的成长故事,就暂时给他起名叫做范宜(谐音:翻译)好了。
最一开始的时候,范宜是个只会翻字典找对应的孩子。后来他学会了数学和统计,于是他开始一点点构建统计模型,希望以此提高翻译的准确度。他最先尝试逐词翻译,可是翻译出的内容经常牛头不对马嘴。于是他开始以短语为单位重新建模,这一次的效果好多了。然而随着年龄的增长,世界对他的要求也越来越高,给他的句子也越来越长。为了确保句子的连贯性,范宜开始逐渐尝试以句子做单位,并能翻译出句中各短语之间的逻辑关系。听人说,他这方法这就像人类的神经网络一样,可厉害了。尽管如此,还是有人会问说:“范宜啊,你不熟悉的、从来没去过的那些地方,从来没学过的语言,到底能不能翻?” 范宜愣了一下,就迅速地给出了答案“能”。不仅仅是可以根据那个不熟悉的语言的资料来学习着翻译,在没有多余数据仅有之前这门语言和别的语言的翻译技巧的知识的情况下,他也能做到精准翻译。
青年范宜已经成为了很多时候大家寻求翻译的第一对象。之后的他又会有怎样的发展?
预告
机器翻译技术的好坏是如何大规模判别的?这些技术是如何应用到商业中的?这些技术对于人类译者的影响几何?机器能够深入理解文本对于人类而言,到底意味着什么?小线菌将在机器翻译这一专题下与大家一一探讨。请多多关注哦~
参考资料:
boxi, Google发布新的机器翻译系统,但它真的能抢笔译人员的饭碗吗?
新智元,Facebook最新对抗学习研究:无需平行语料库完成无监督机器翻译
Devin Coldewey, 关注机制让机器读懂词与词之间的关系

五分钟,你可以掌握一个科学知识。
五分钟,你可以了解一个科技热点。
五分钟,你可以近观一个极客故事。
精确解构科技知识,个性表达投融观点。
欢迎关注线性资本。
Linear Path, Nonlinear Growth。




