机器学习翻译基本原理
编者按:Statsbot数据科学家Daniil Korbut简明扼要地介绍了用于机器学习翻译的基本原理:RNN、LSTM、BRNN、Seq2Seq、Zero-Shot、BLEU。
我们都在使用的很多技术,我们其实并不知道它们到底是如何工作的。实际上,理解机器学习驱动的引擎并非易事。Statsbot团队博客希望能讲清楚机器学习是怎么一回事。这次我们决定探索机器翻译,并解释Google翻译算法的原理。
许多年前,翻译来自未知语言的文本是非常耗时的。使用简单的词汇表逐字翻译之所以很困难,是因为读者必须知道语法规则,在翻译整句时需要记住所有的语言版本。
现在,我们不需要为此付出太多的努力——只需将它们粘贴到Google翻译中,就可以翻译短语、句子甚至大段文本。然而,大多数人实际上并不关心机器翻译的引擎是如何工作的。本文为那些关心这个的人而写。
深度学习翻译问题
如果Google翻译引擎试图储存所有的翻译,甚至仅仅储存短句的翻译,都是行不通的,因为可能的变体数量巨大。最好的想法可能是教会计算机一组语法规则,并根据语法规则来翻译句子,如果这一切真像听起来那样简单的话。
如果你曾经试过学习外语,那么你该知道规则总是有很多例外的。当我们试图在程序中刻画所有这些规则,所有这些例外,乃至例外的例外时,翻译质量就崩塌了。
现代机器翻译系统使用不同的方法:通过分析大量文档将文本与规则联系起来。
创建你自己的简单机器翻译工具,对任何数据科学简历来说都是一个很棒的项目。
我们试着调查一下我们称之为机器翻译的“黑盒子”里隐藏着什么。深度神经网络可以在非常复杂的任务(语音/视觉对象识别)中取得优异的结果,但是,尽管它们很灵活,却只能应用于具有固定维度的输入和目标的任务。
循环神经网络
因此,我们需要长短期记忆网络(LSTM),它能应对事先未知长度的序列。
LSTM是一种能够学习长期依赖的循环神经网络(RNN)。循环神经网络看起来就像一串重复的模块。
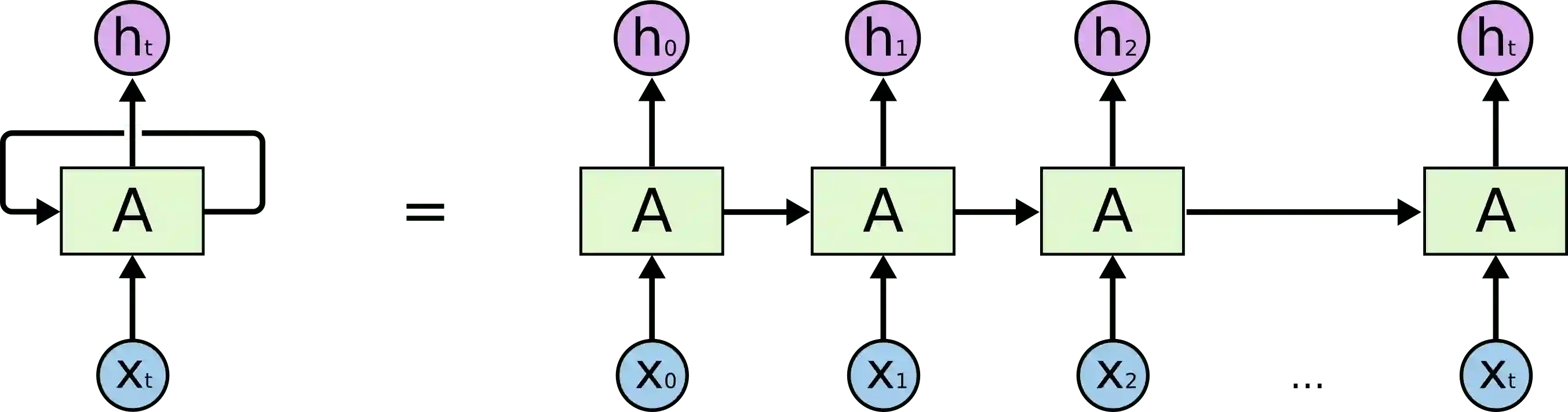
via colah.github.io
因此LSTM在模块之间传递数据,比如,为了生成Ht,我们不仅使用Xt,同时使用所有X之前的输入。关于LSTM的更多信息,可参考Understanding LSTM Networks(英文)和循环神经网络入门(中文)。
双向循环神经网络
我们的下一步是双向循环神经网络(BRNN)。 BRNN将常规RNN的神经元分成两个方向。一个方向是正向的时间,或前馈状态。另一个方向是负向的时间,或反馈状态。这两个状态的输出与反方向的状态的输入互不相连。
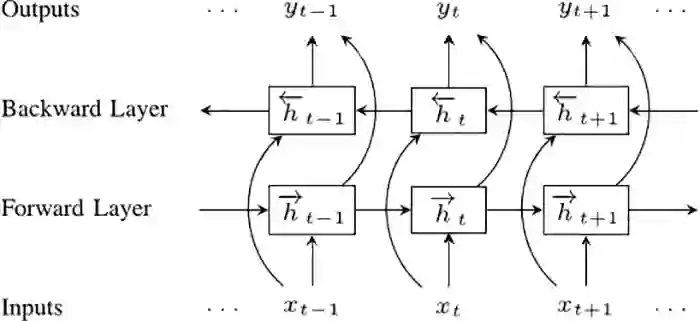
要理解为何BRNN效果更好,可以想像一下我们有一个包含9个单词的句子,然后想要预测第5个单词。我们可以让网络仅仅知道前面4个单词,或者让网络知道前面4个单词和后面4个单词。显然第二种情况下预测的质量会更好。
序列到序列
然后是序列到序列模型(也称为seq2seq)。基本的seq2seq模型包含两个RNN:一个处理输入的编码网络和一个生成输出的解码网络。
最后,我们将创建我们的第一个机器翻译工具!
不过,让我们先考虑一个绝招。Google翻译目前支持103种语言,所以我们应该有103x102个不同的模型。当然,取决于语言的流行程度和训练网络需要的文档数量,这些模型的质量会有所不同。最好我们能创建一个神经网络,然后这个网络能接受任何语言作为输入,然后将其翻译成任何语言。
Google翻译
这个想法正是Google工程师们在2016年末实现的想法。Google工程师使用的正是我们上文提及的seq2seq模型。
唯一的例外是在编码和解码网络之间有8层LSTM-RNN网络,层间有残差连接,还有一些出于精度和速度考虑的调整。如果你想深入了解相关信息,可以看Google’s Neural Machine Translation System这篇论文。
最重要的一点是Google的翻译算法使用单个系统,而不是包含每对语言组合的庞大集合。
在输入句子的开始,系统需要一个指明目标语言的token。
这一方法改善了翻译的质量,同时允许翻译那些系统没有见过对应译文语料的语言组合,这一方法称为“零样本翻译”(Zero-Shot Translation)。
更好的翻译?
当我们谈论Google翻译算法的改进和更好的结果时,我们如何才能正确地评估第一个翻译候选比第二个候选更好呢?
这不是一个微不足道的问题,因为对于一些常用的句子,我们有来自专业译员的参考译文集合,这些译文间当然有一些差异。
能部分解决这个问题的方法有很多,但最流行和最有效的衡量标准是BLEU(bilingual evaluation understudy)。 想象一下,我们有来自机器翻译的两个候选:
候选一: Statsbot makes it easy for companies to closely monitor data from various analytical platforms via natural language.
候选二:Statsbot uses natural language to accurately analyze businesses’ metrics from different analytical platforms.

尽管它们的意思相同,但在质量和结构上都有差异。
让我们看下两个来自人类的翻译:
Reference 1: Statsbot helps companies closely monitor their data from different analytical platforms via natural language.
Reference 2: Statsbot allows companies to carefully monitor data from various analytics platforms by using natural language.
显然,候选一更好,与候选二相比,候选一和人工翻译共享更多的单词和短语。这是简单BLEU方法的核心想法。我们可以比较候选翻译和参考翻译的n元语法,并计算匹配的数量(与它们的位置无关)。我们只评估n元语法的准确率,因为计算多个参考的召回很困难,评估结果是n元语法的几何平均值。
现在可以评估机器学习翻译的复杂引擎了。下一次使用Google翻译进行翻译时,想象一下,在返回最好的版本之前,它分析了数百万个文档。
原文地址:https://blog.statsbot.co/machine-learning-translation-96f0ed8f19e4







