清华大学:刘洋——基于深度学习的机器翻译

来源:图灵人工智能
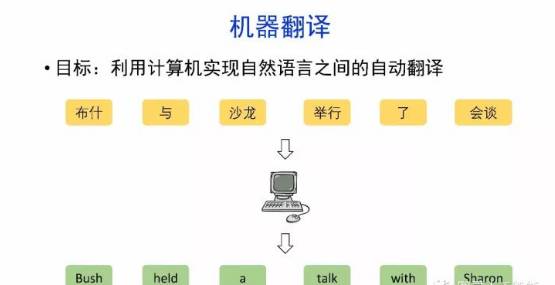
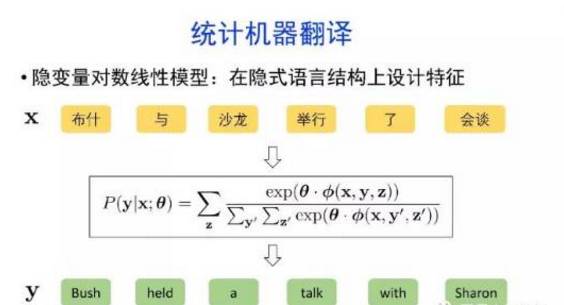
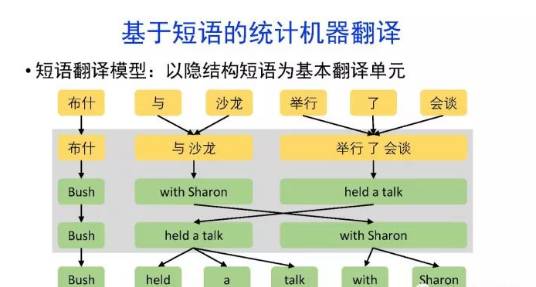
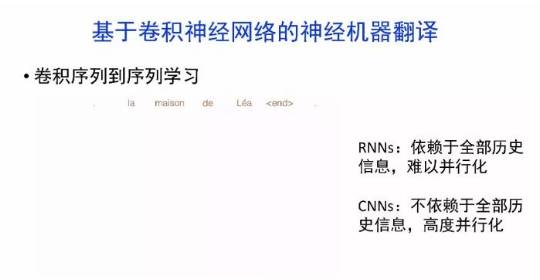
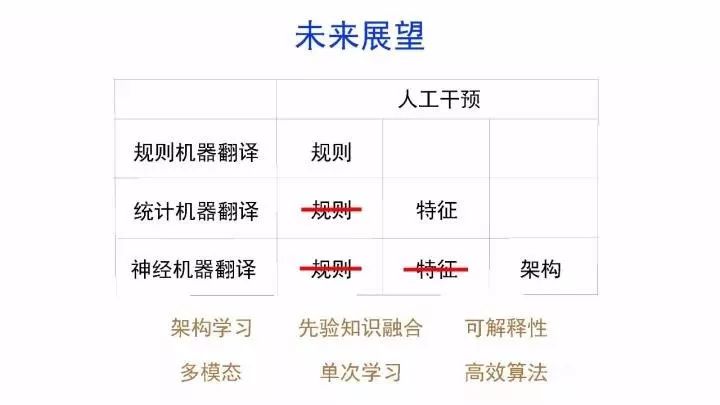
概要:机器翻译的目标是利用计算机实现自然语言之间的自动翻译。机器翻译经历了规则机器翻译、统计机器翻译、神经机器翻译。
刘洋,清华大学计算机科学与技术系副教授,博士生导师,国家优秀青年基金获得者。研究方向是自然语言处理,在自然语言处理和人工智能领域重要国际刊物Computational Linguistics和国际会议ACL、EMNLP、IJCAI和AAAI上发表50余篇论文,获ACL 2017杰出论文和ACL 2006优秀亚洲自然语言处理论文奖。承担10余项国家自然科学基金、国家重点研发计划、国家863计划、国家科技支撑计划和国际合作项目,2015年获国家自然科学基金优秀青年项目资助。获得2015年国家科技进步二等奖、2014年中国电子学会科学技术奖科技进步类一等奖、2009年北京市科学技术奖二等奖和2014年中国中文信息学会钱伟长中文信息处理科学技术奖汉王青年创新奖一等奖等多项科技奖励。担任中国中文信息学会青年工作委员会主任兼计算语言学专业委员会秘书长、国际计算语言学学会SIGHAN Information Officer、ACM TALLIP Associate Editor、ACL 2015组织委员会共同主席、ACL 2014讲习班共同主席、ACL 2017与EMNLP 2016程序委员会机器翻译领域共同主席。
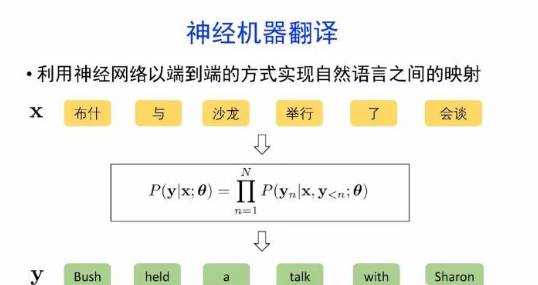
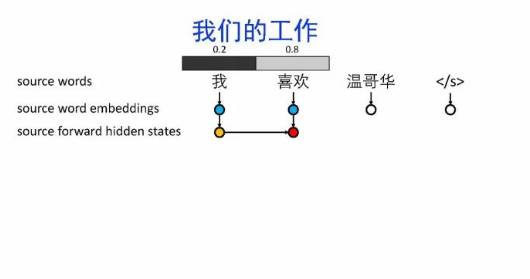
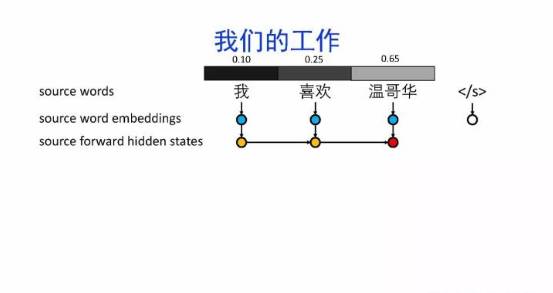
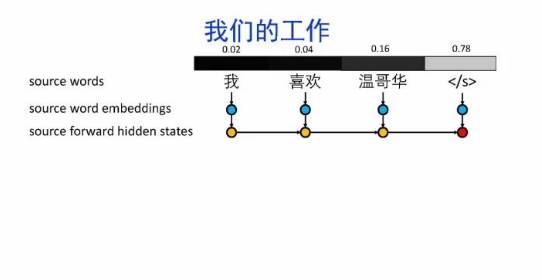
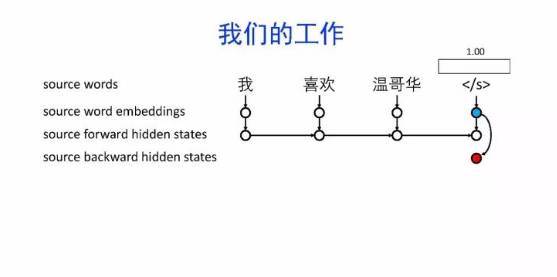
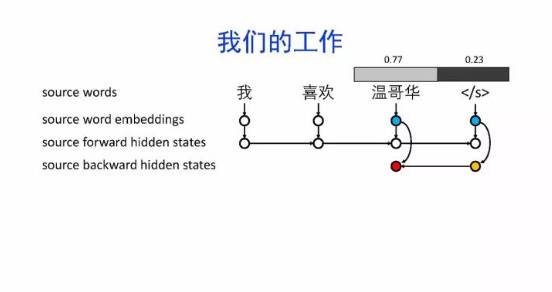
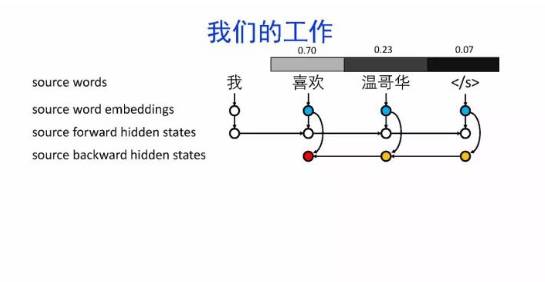
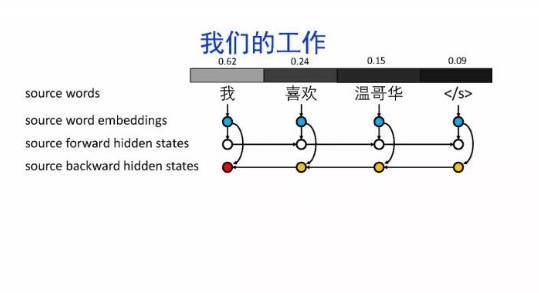
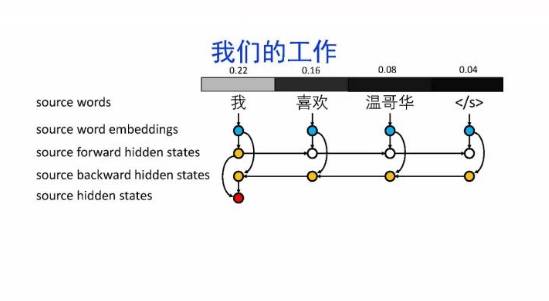
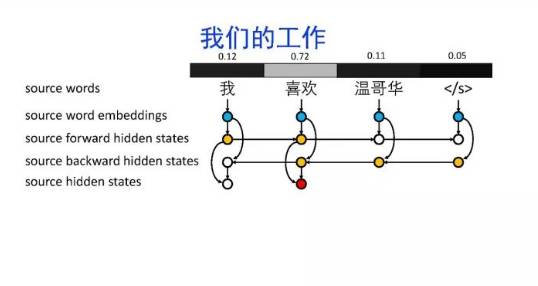
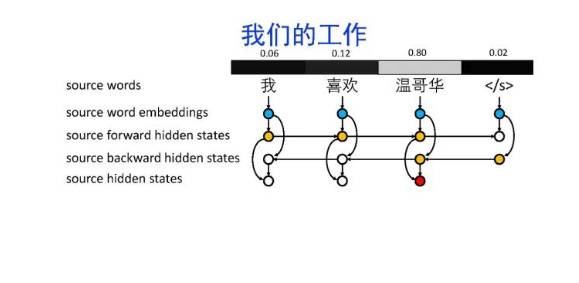
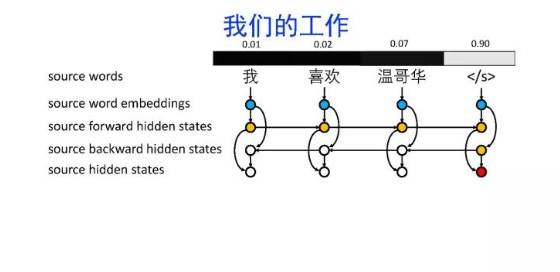
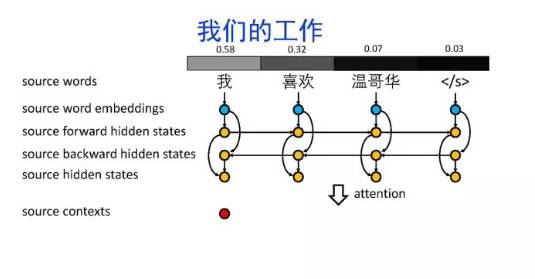
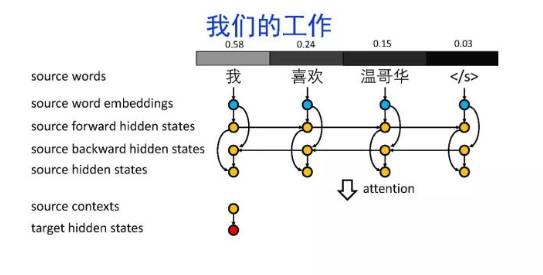
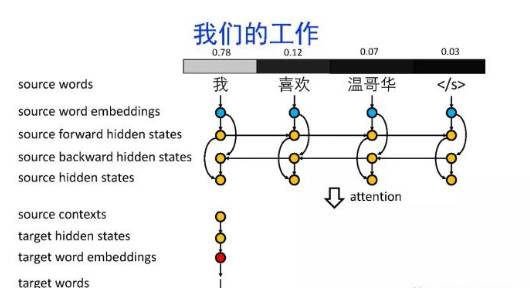
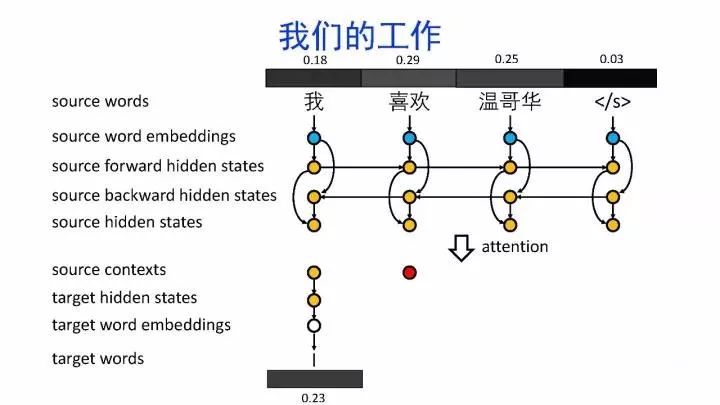
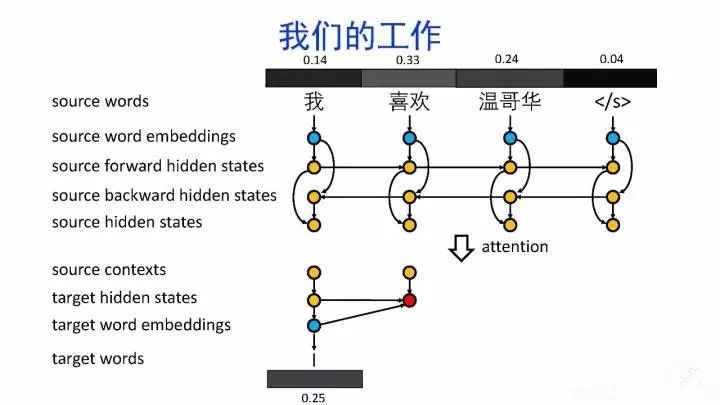
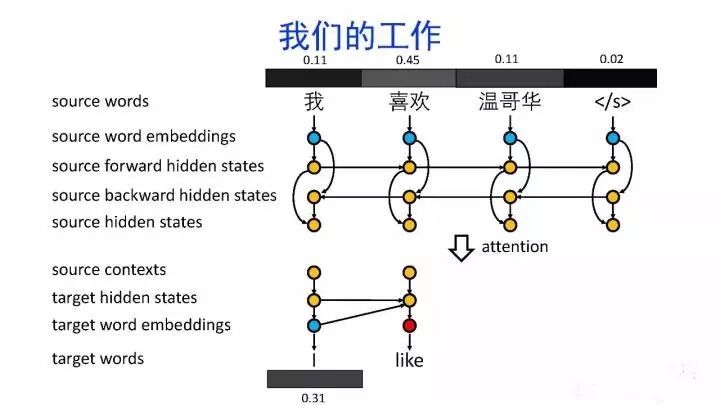
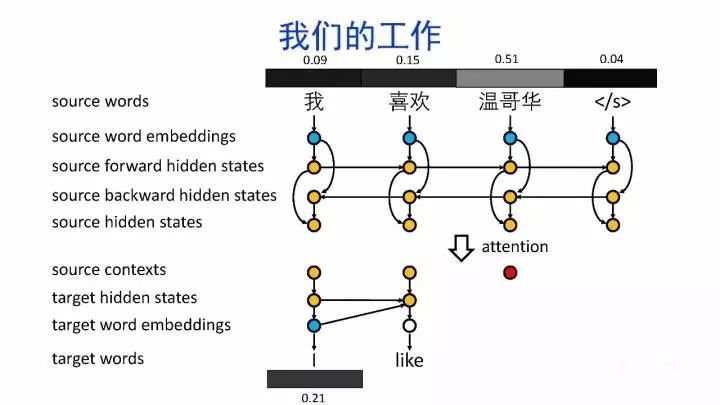
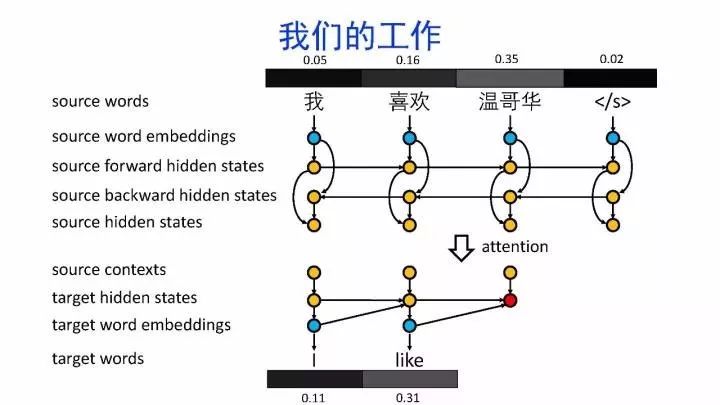
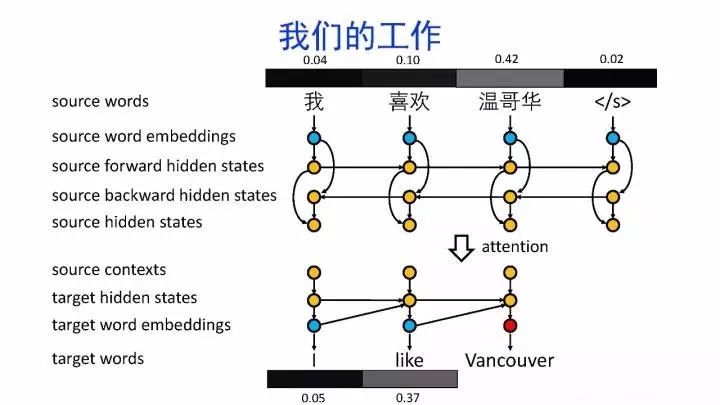
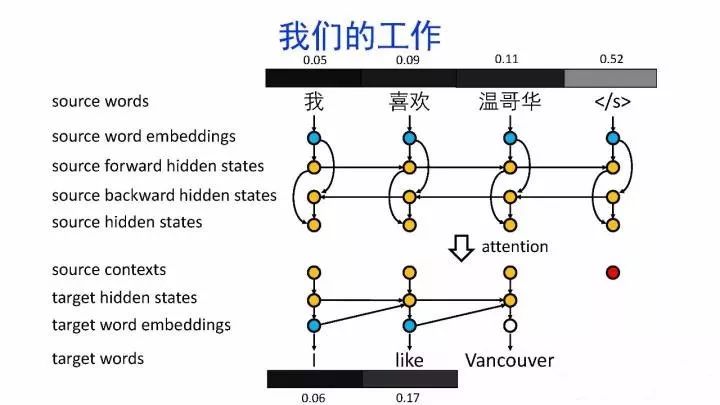
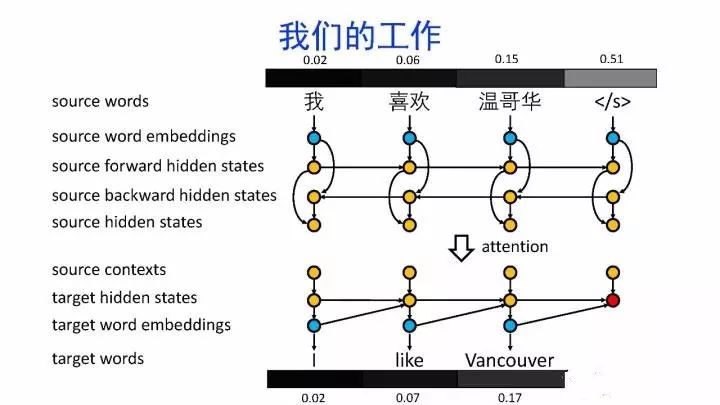
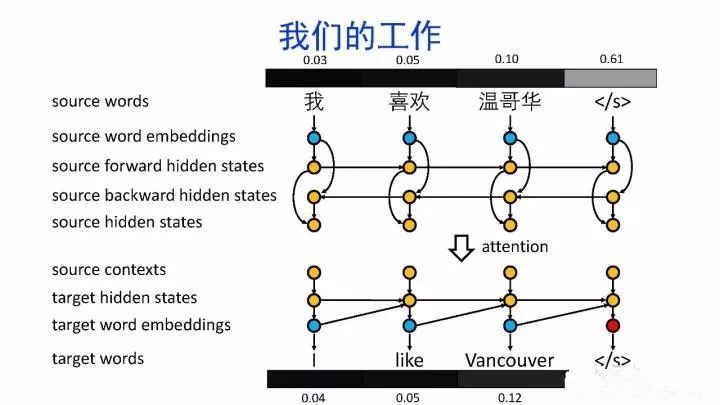
导读:机器翻译的目标是利用计算机实现自然语言之间的自动翻译。机器翻译经历了规则机器翻译、统计机器翻译、神经机器翻译。神经机器翻译通过神经网络直接实现自然语言的相互映射。
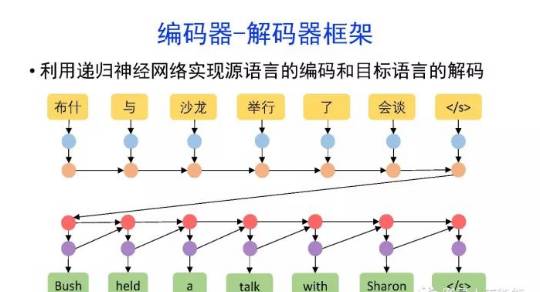
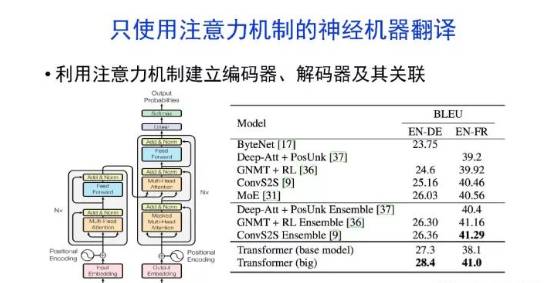
•神经机器翻译近年来取得迅速发展,已经取代统计机器翻译成为新的主流技术。
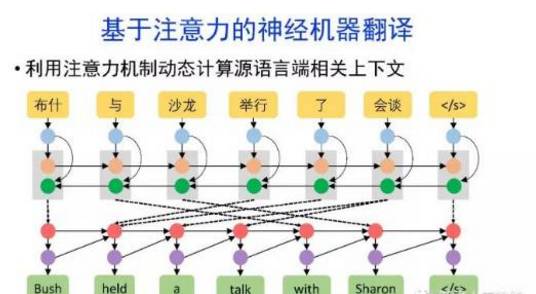
•神经机器翻译在架构、先验知识融合、可解释性等方面仍面临挑战,需要进一步深入探索。
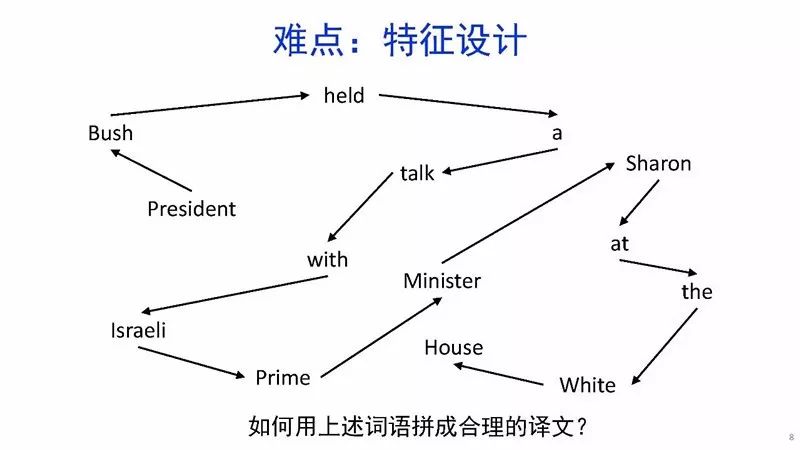
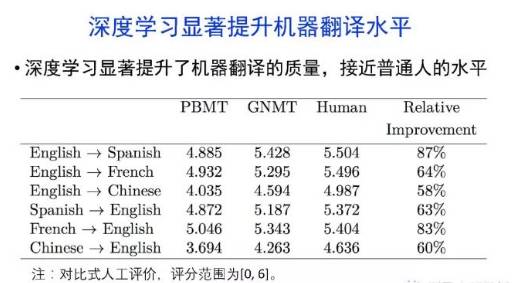
深度学习显著提升了机器翻译的质量,接近普通人的水平主要挑战
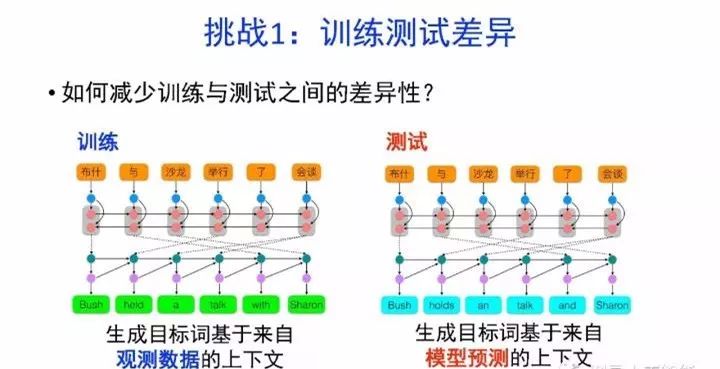
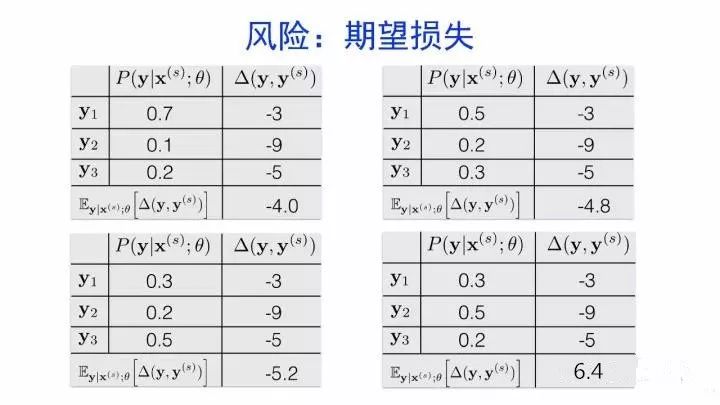
如何减少训练与测试之间的差异性?
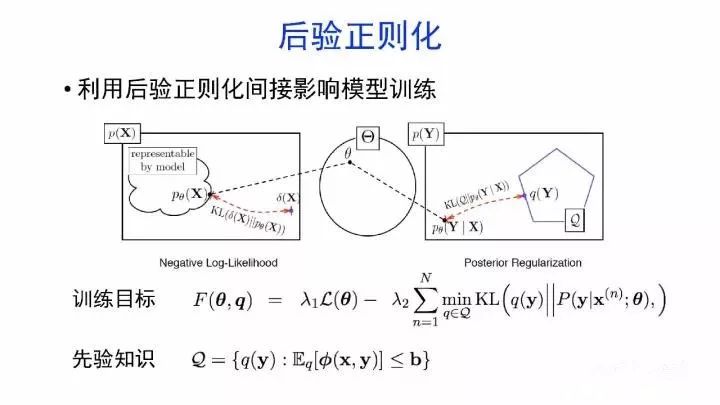
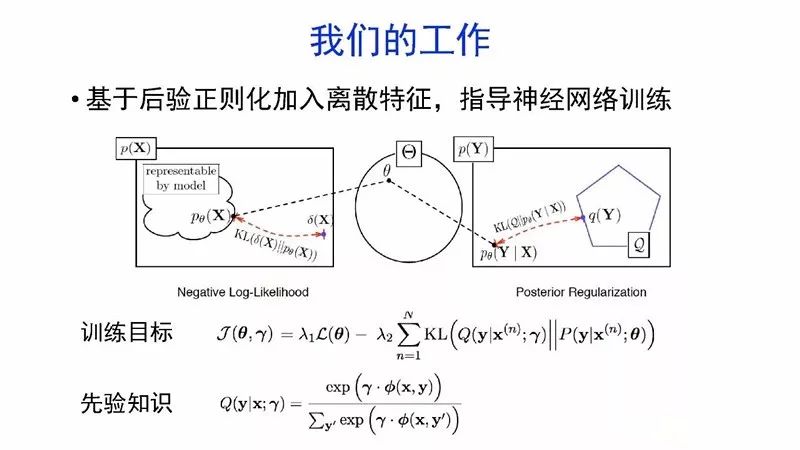
如何向神经网络加入先验知识?
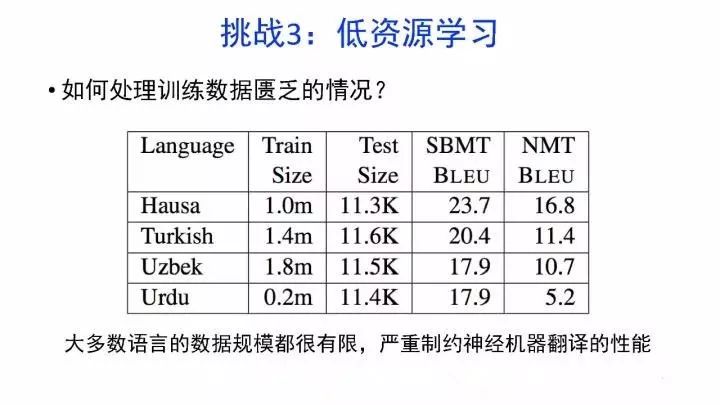
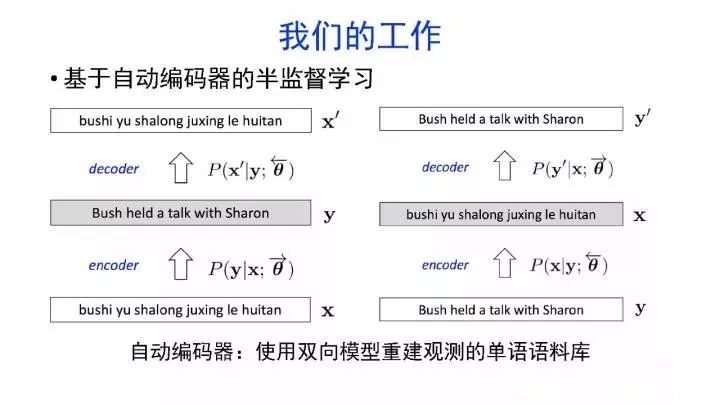
如何处理训练数据匮乏的情况?
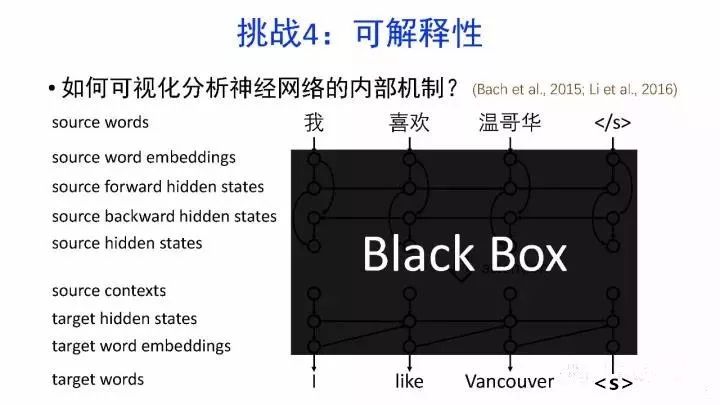
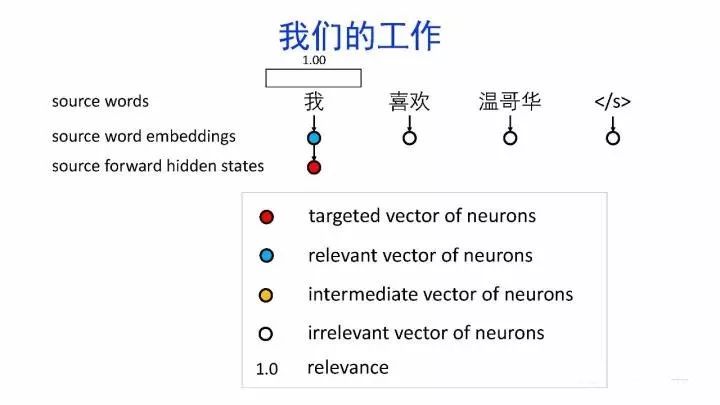
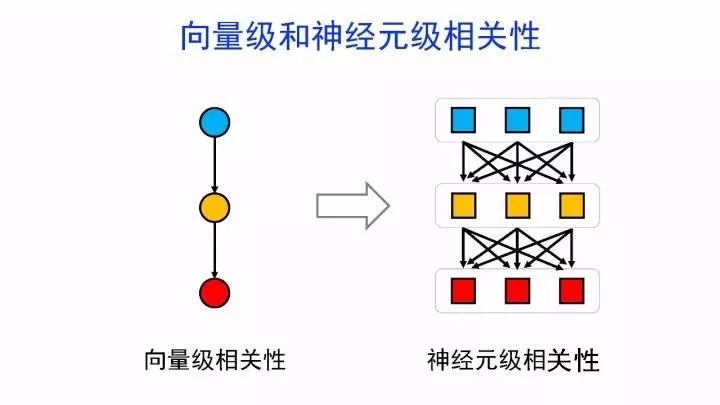
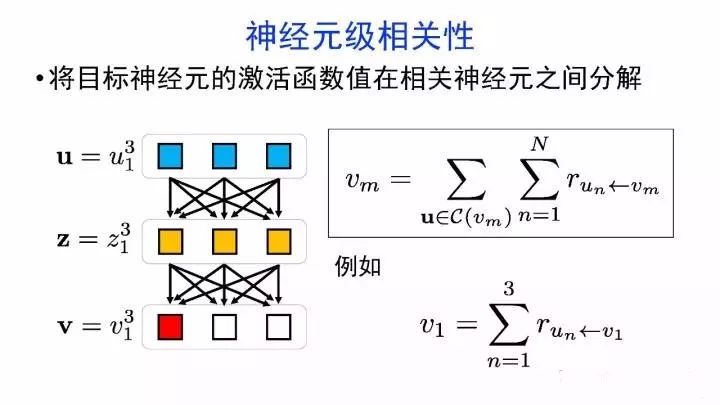
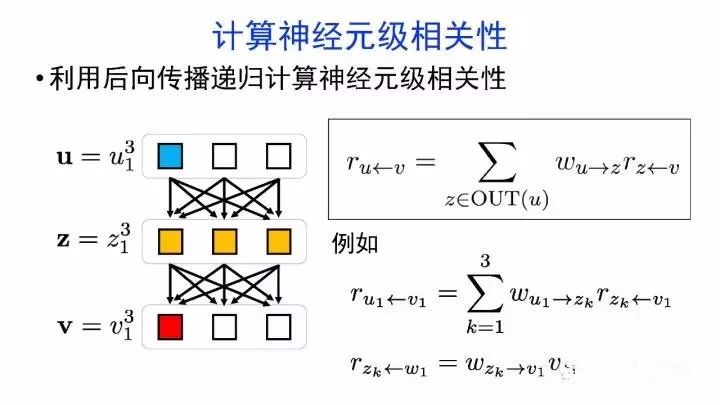
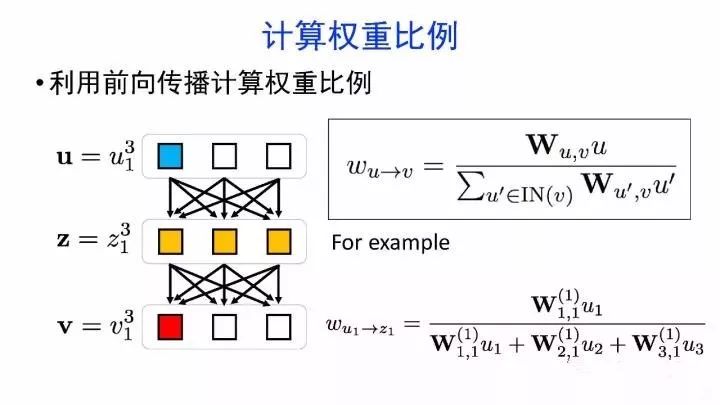
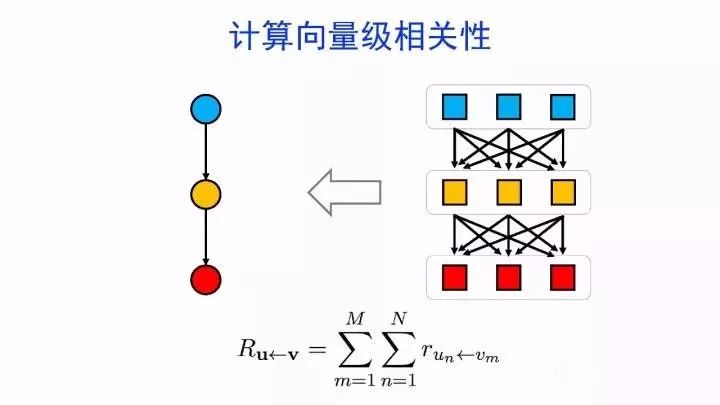
如何可视化分析神经网络的内部机制?